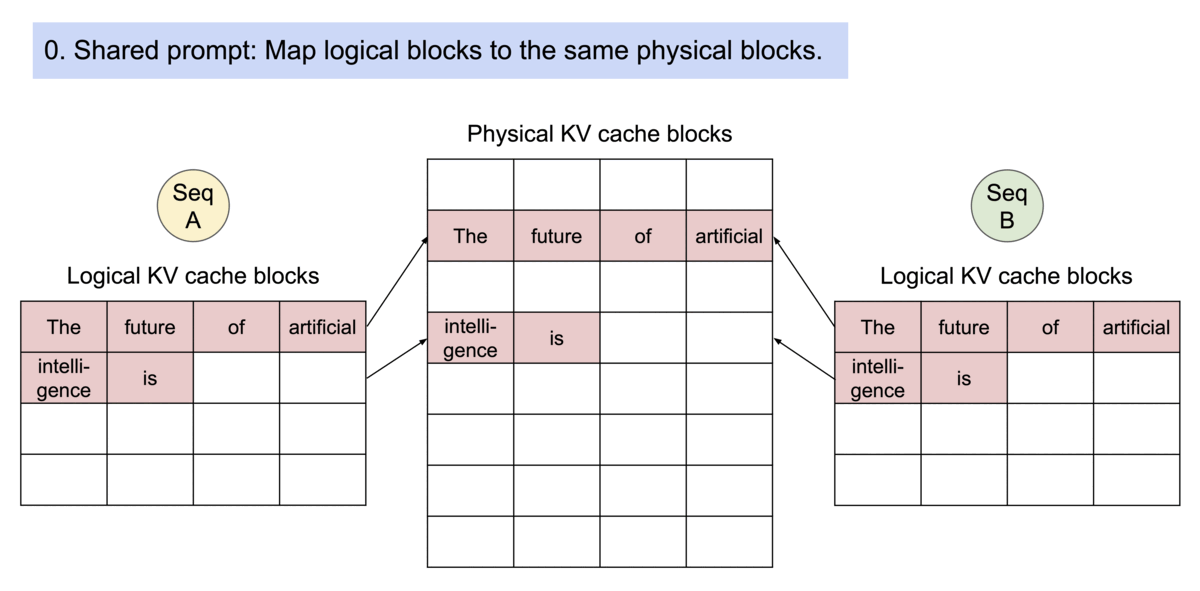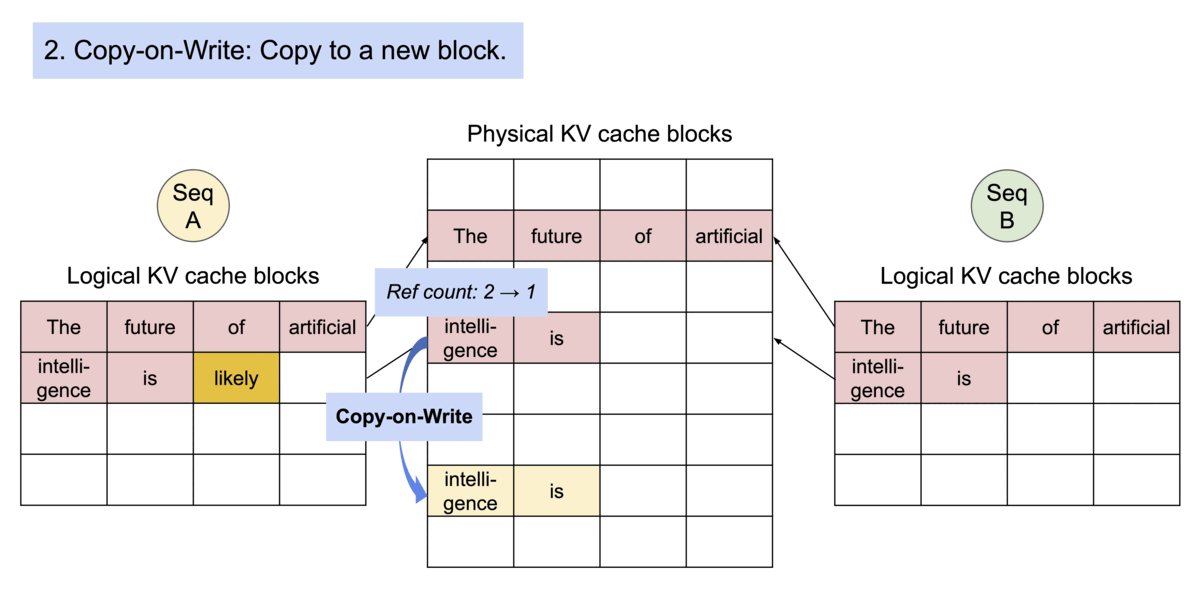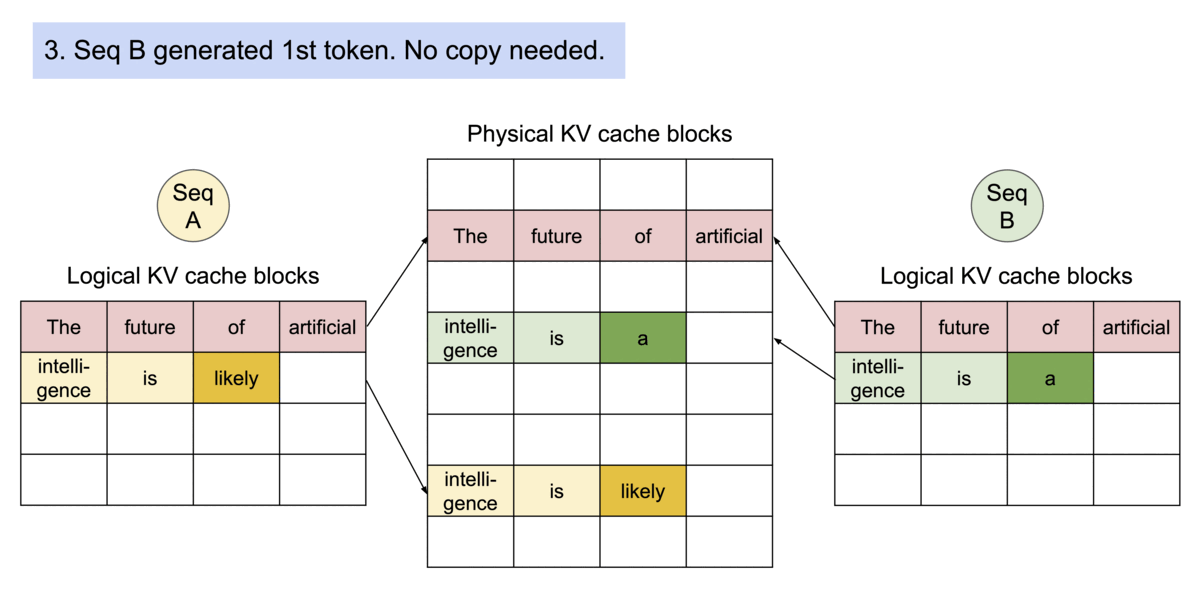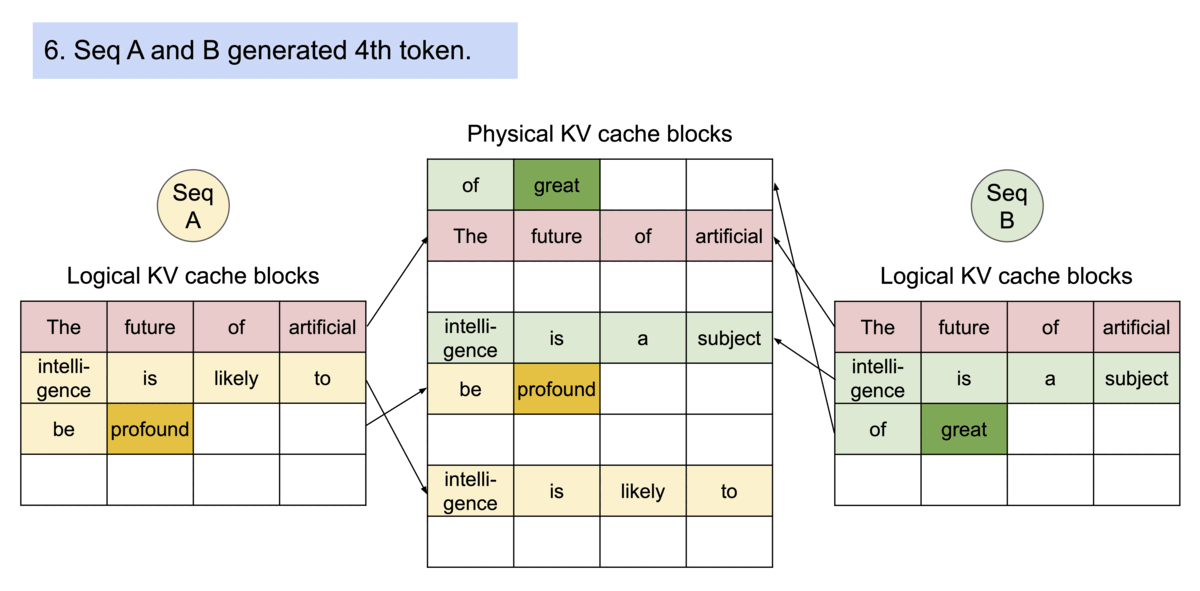
vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention
GitHub | Documentation | Paper
https://blog.vllm.ai/2023/06/20/vllm.html
LLMs promise to fundamentally change how we use AI across all industries. However, actually serving these models is challenging and can be surprisingly slow even on expensive hardware. Today we are excited to introduce vLLM, an open-source library for fast LLM inference and serving. vLLM utilizes PagedAttention, our new attention algorithm that effectively manages attention keys and values. vLLM equipped with PagedAttention redefines the new state of the art in LLM serving: it delivers up to 24x higher throughput than HuggingFace Transformers, without requiring any model architecture changes.
vLLM has been developed at UC Berkeley and deployed at Chatbot Arena and Vicuna Demo for the past two months. It is the core technology that makes LLM serving affordable even for a small research team like LMSYS with limited compute resources. Try out vLLM now with a single command at our GitHub repository.
Beyond State-of-the-art Performance
We compare the throughput of vLLM with HuggingFace Transformers (HF), the most popular LLM library and HuggingFace Text Generation Inference (TGI), the previous state of the art. We evaluate in two settings: LLaMA-7B on an NVIDIA A10G GPU and LLaMA-13B on an NVIDIA A100 GPU (40GB). We sample the requests’ input/output lengths from the ShareGPT dataset. In our experiments, vLLM achieves up to 24x higher throughput compared to HF and up to 3.5x higher throughput than TGI.
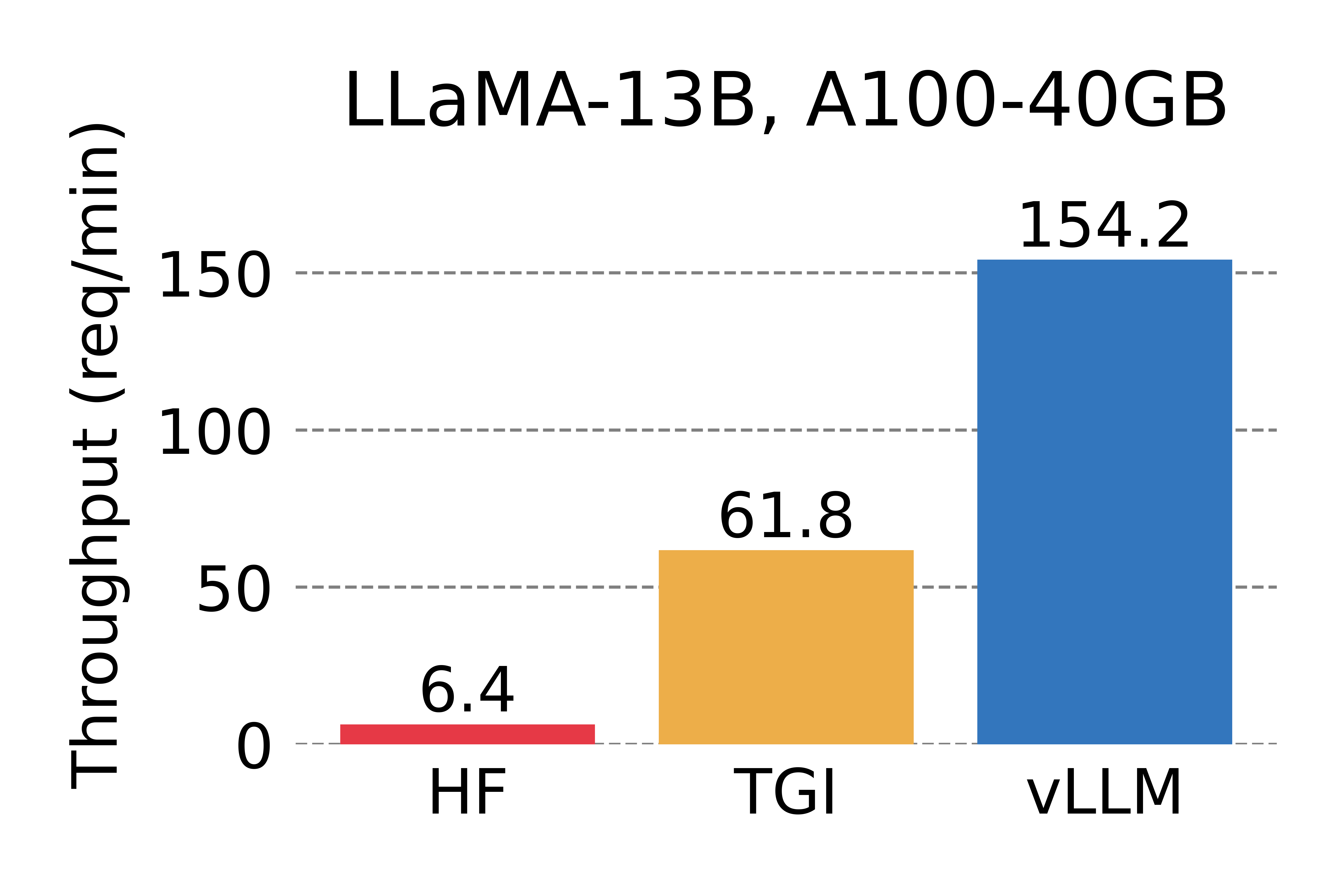
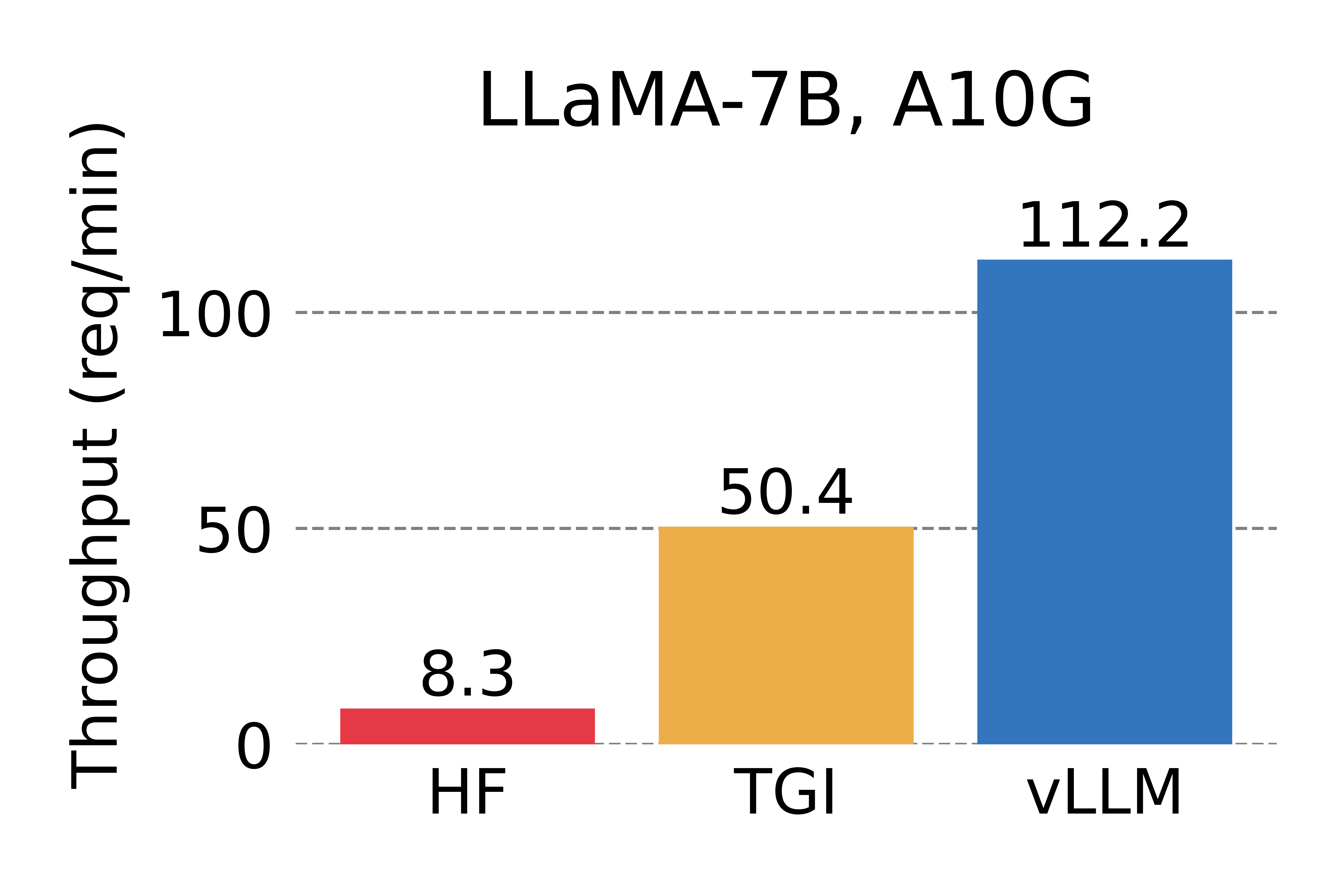
Serving throughput when each request asks for one output completion. vLLM achieves 14x – 24x higher throughput than HF and 2.2x – 2.5x higher throughput than TGI.
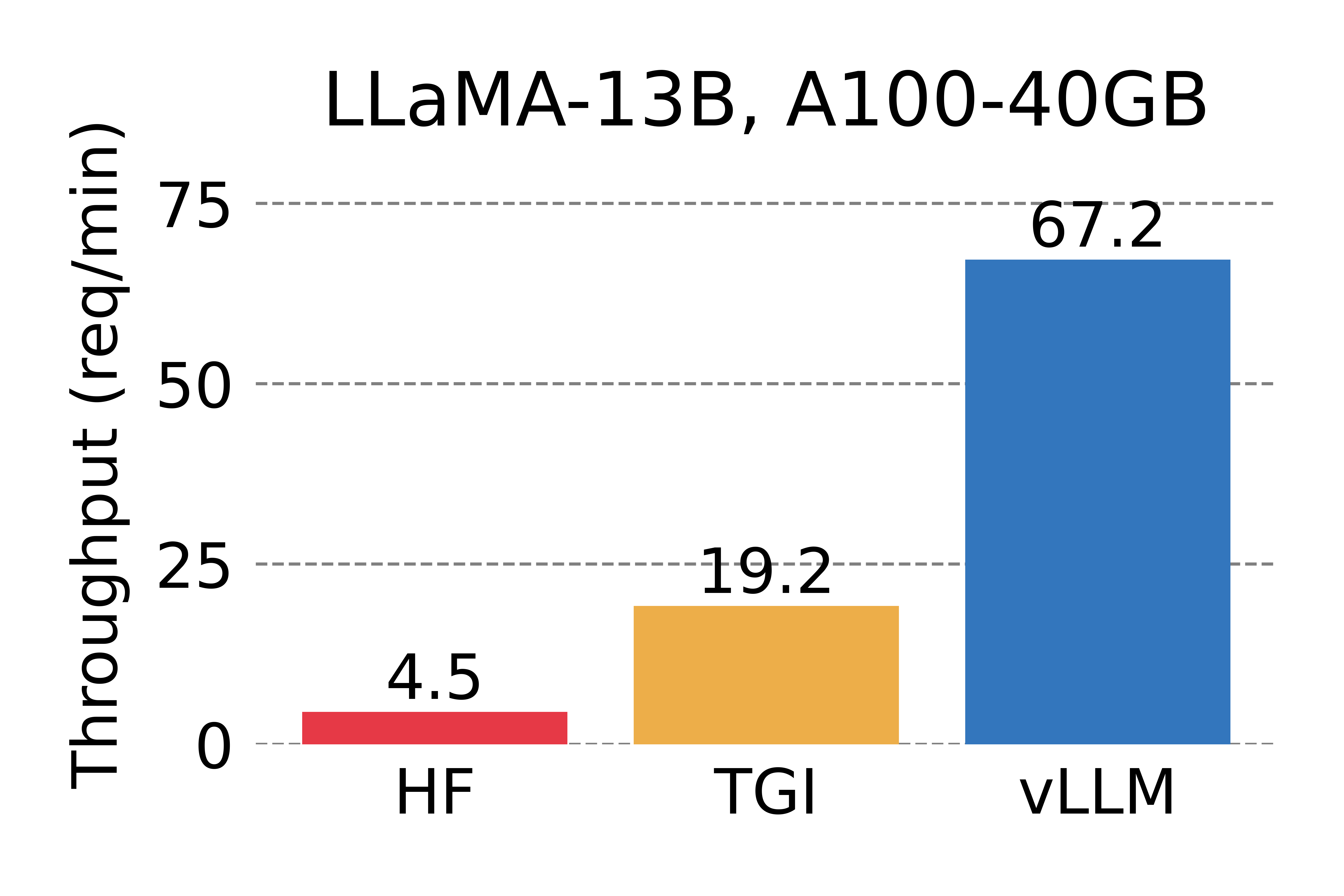
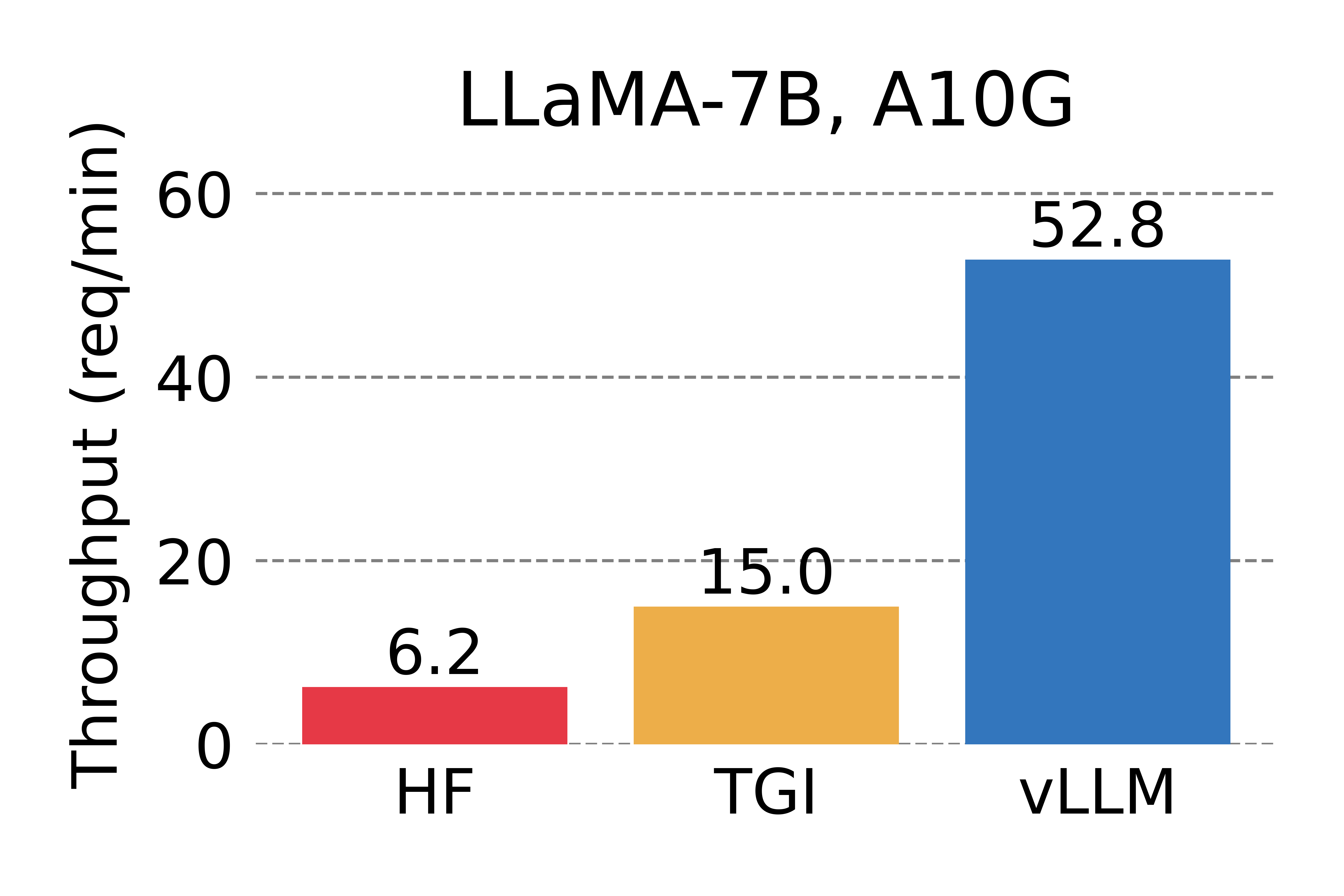
Serving throughput when each request asks for three parallel output completions. vLLM achieves 8.5x – 15x higher throughput than HF and 3.3x – 3.5x higher throughput than TGI.
The Secret Sauce: PagedAttention
In vLLM, we identify that the performance of LLM serving is bottlenecked by memory. In the autoregressive decoding process, all the input tokens to the LLM produce their attention key and value tensors, and these tensors are kept in GPU memory to generate next tokens. These cached key and value tensors are often referred to as KV cache. The KV cache is
- Large: Takes up to 1.7GB for a single sequence in LLaMA-13B.
- Dynamic: Its size depends on the sequence length, which is highly variable and unpredictable. As a result, efficiently managing the KV cache presents a significant challenge. We find that existing systems waste 60% – 80% of memory due to fragmentation and over-reservation.
To address this problem, we introduce PagedAttention, an attention algorithm inspired by the classic idea of virtual memory and paging in operating systems. Unlike the traditional attention algorithms, PagedAttention allows storing continuous keys and values in non-contiguous memory space. Specifically, PagedAttention partitions the KV cache of each sequence into blocks, each block containing the keys and values for a fixed number of tokens. During the attention computation, the PagedAttention kernel identifies and fetches these blocks efficiently.
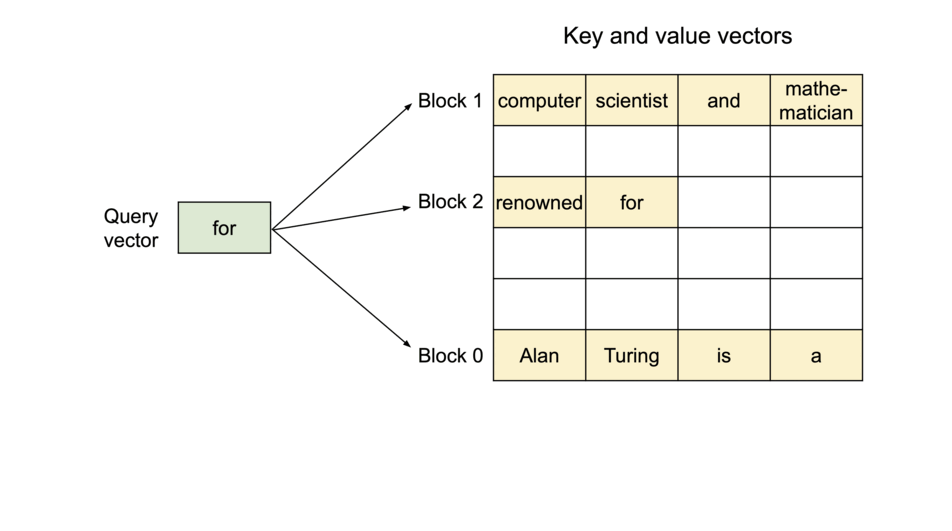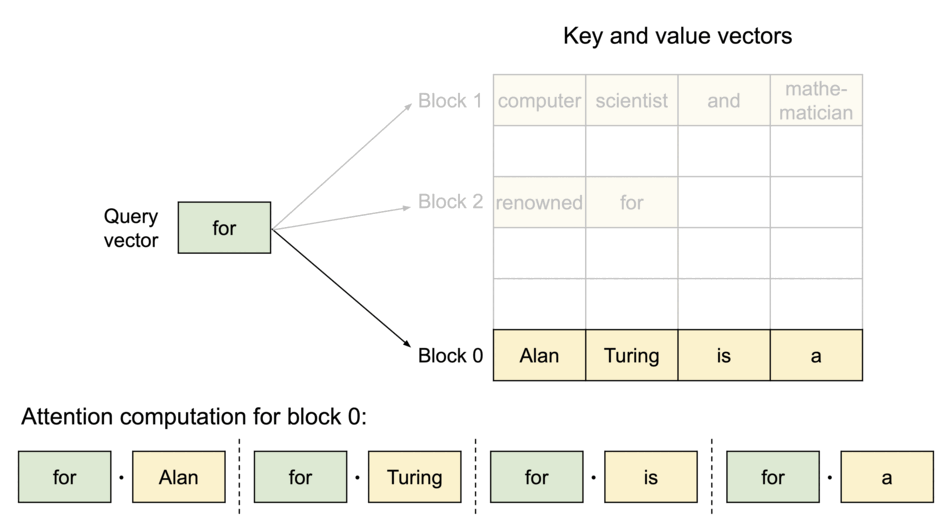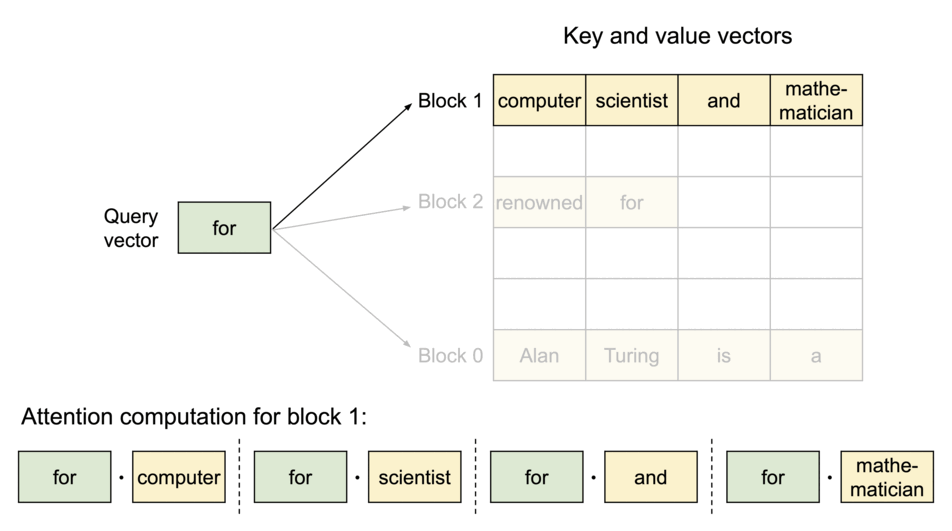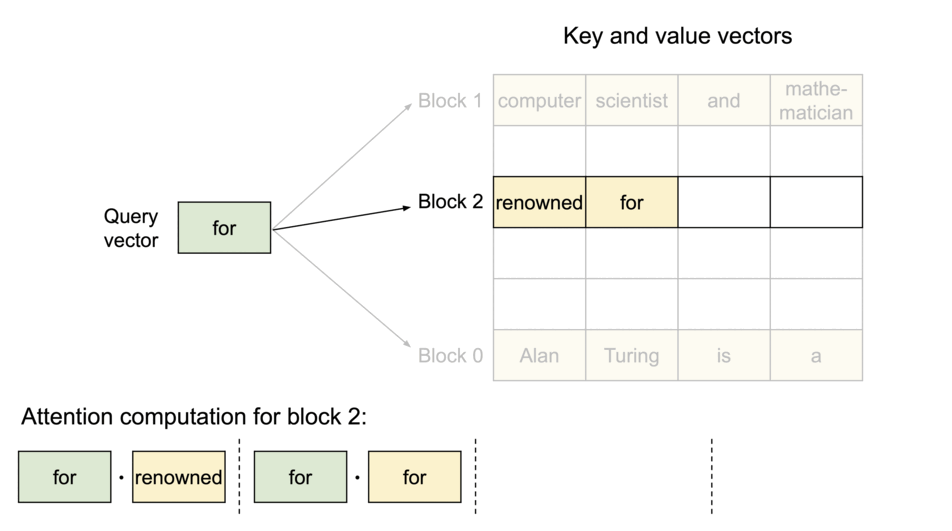
PagedAttention: KV Cache are partitioned into blocks. Blocks do not need to be contiguous in memory space.
Because the blocks do not need to be contiguous in memory, we can manage the keys and values in a more flexible way as in OS’s virtual memory: one can think of blocks as pages, tokens as bytes, and sequences as processes. The contiguous logical blocks of a sequence are mapped to non-contiguous physical blocks via a block table. The physical blocks are allocated on demand as new tokens are generated.
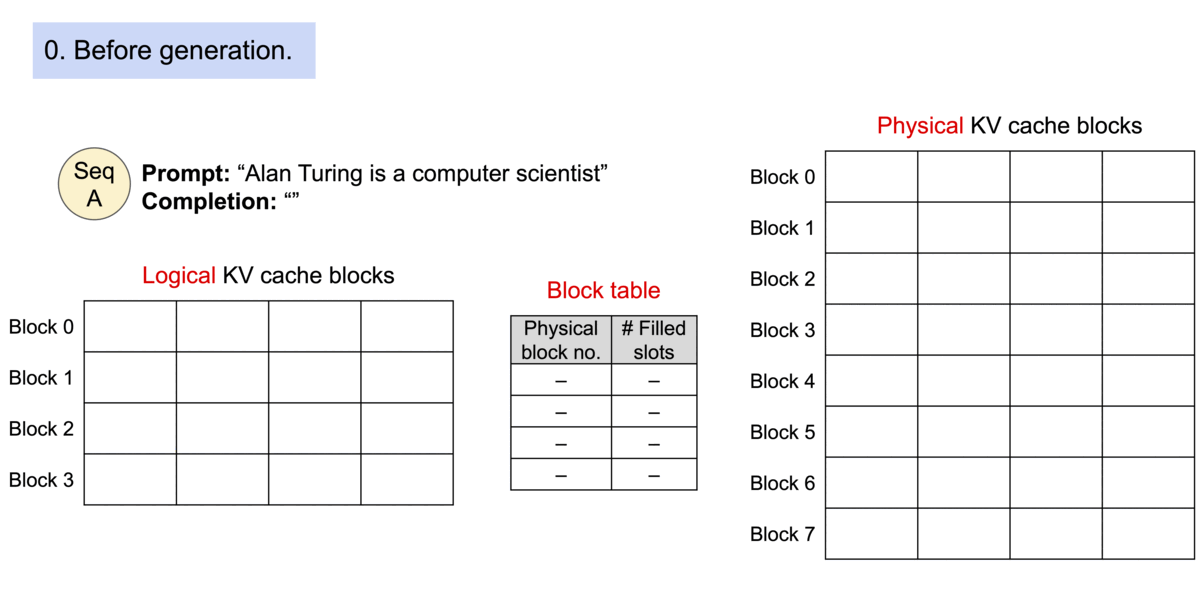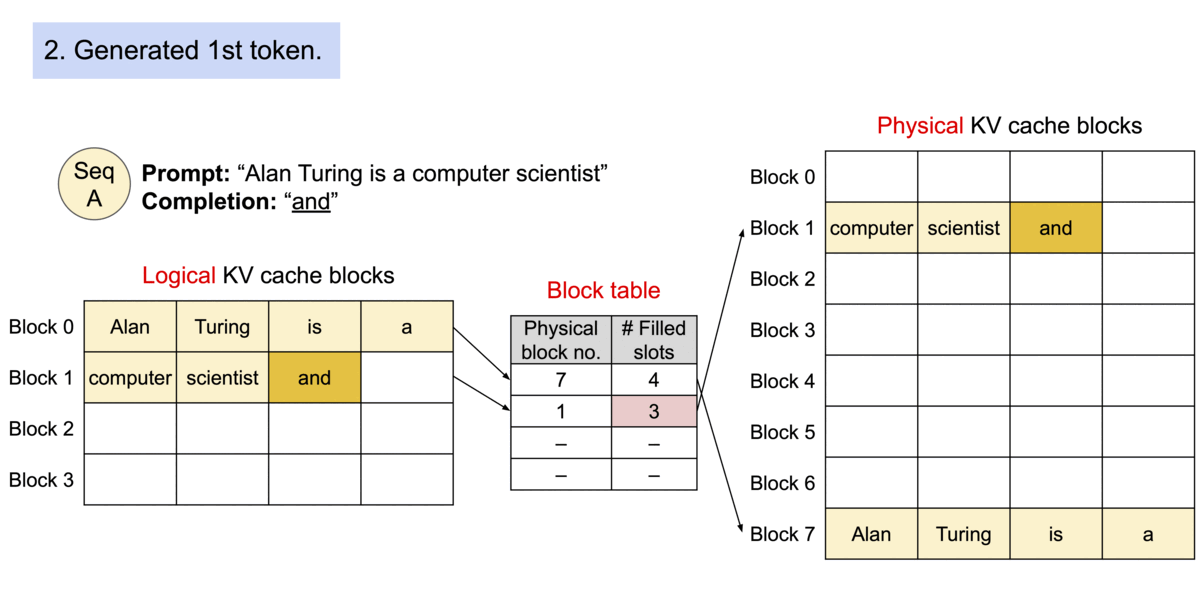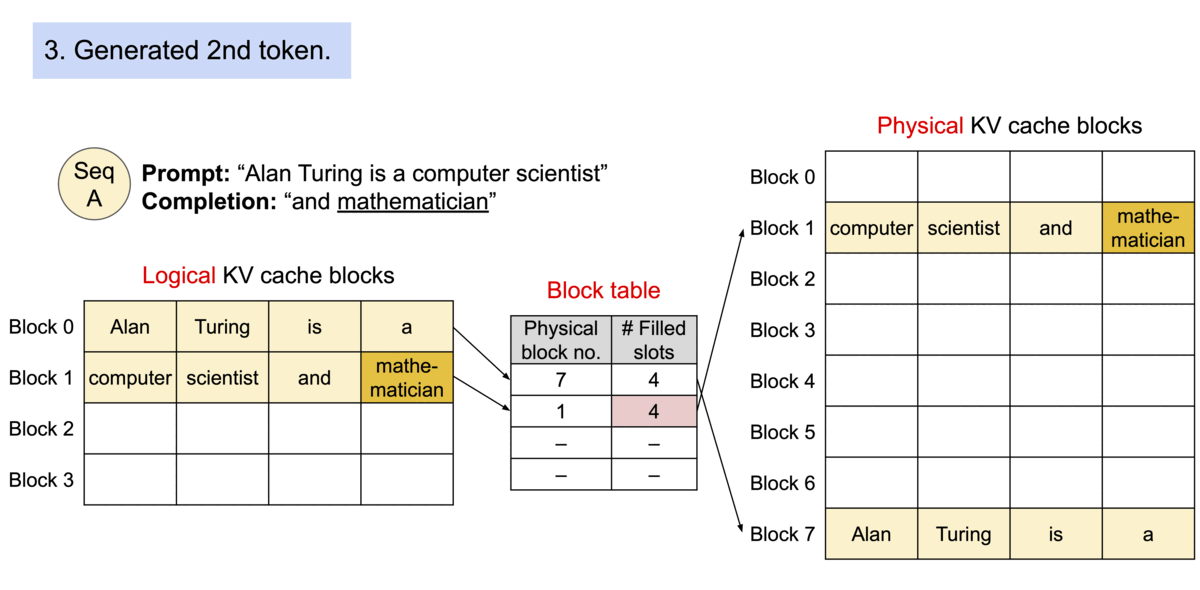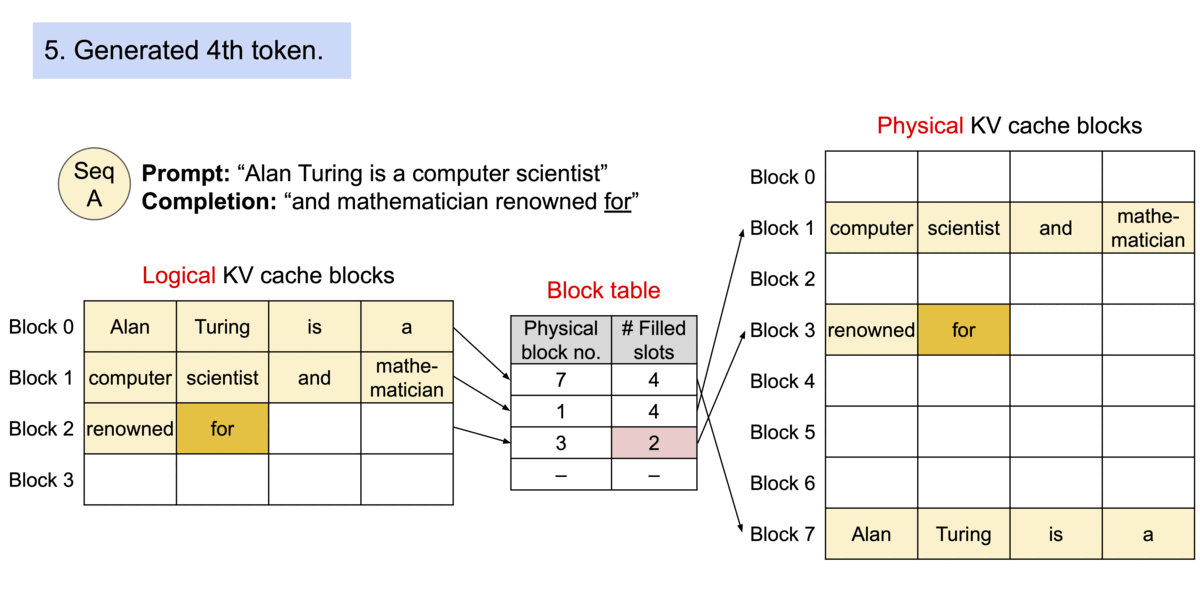
Example generation process for a request with PagedAttention.
In PagedAttention, memory waste only happens in the last block of a sequence. In practice, this results in near-optimal memory usage, with a mere waste of under 4%. This boost in memory efficiency proves highly beneficial: It allows the system to batch more sequences together, increase GPU utilization, and thereby significantly increase the throughput as shown in the performance result above.
PagedAttention has another key advantage: efficient memory sharing. For example, in parallel sampling, multiple output sequences are generated from the same prompt. In this case, the computation and memory for the prompt can be shared between the output sequences.
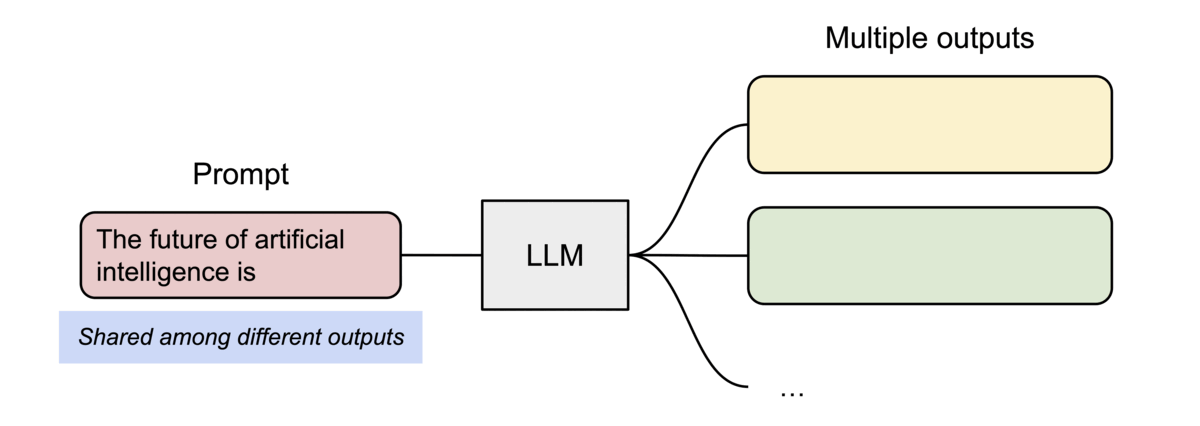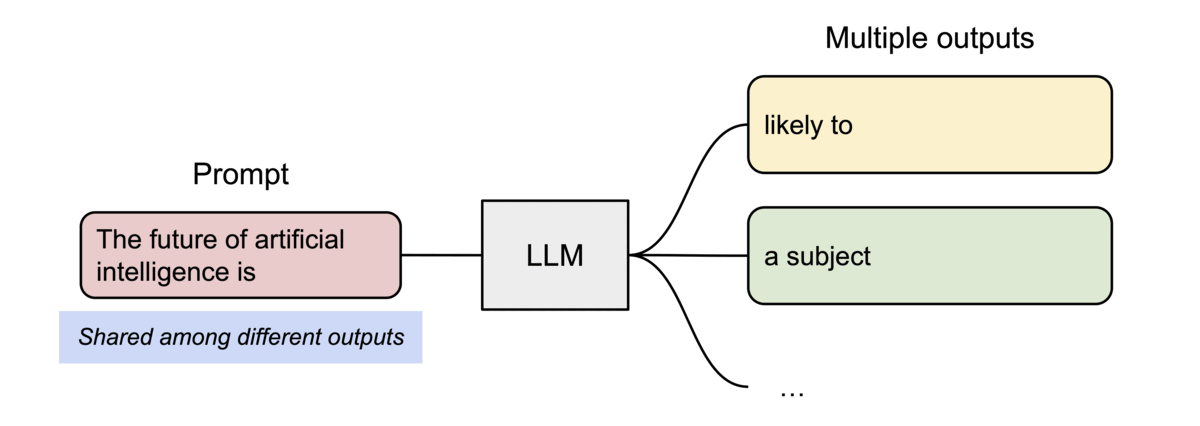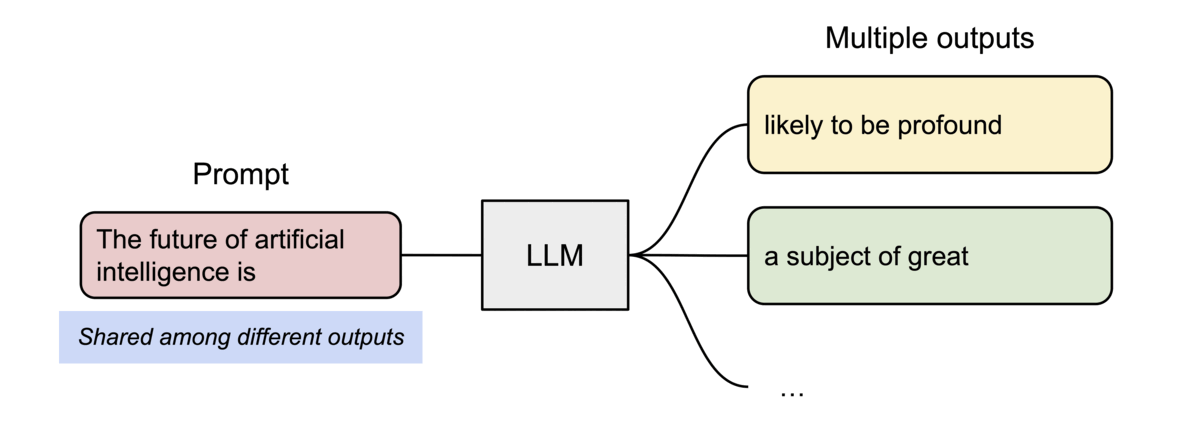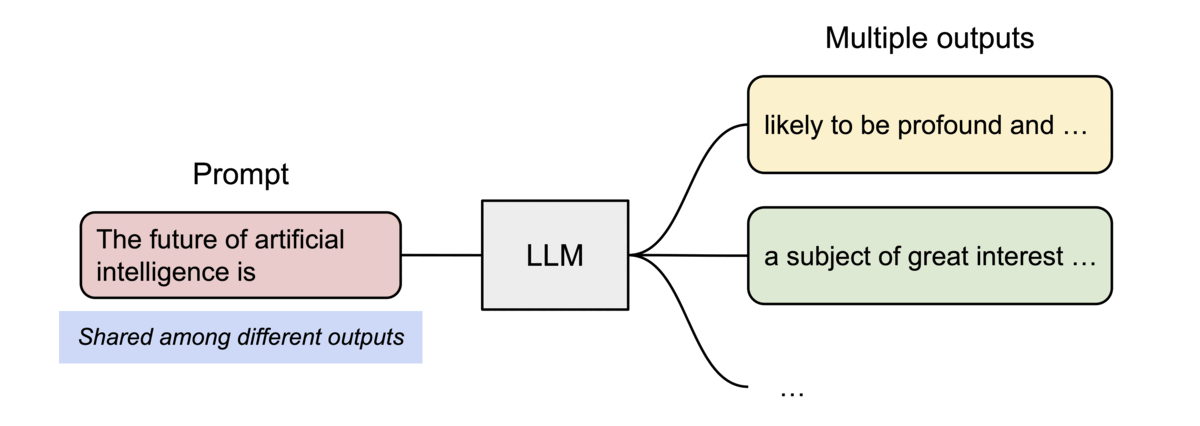
Example of parallel sampling.
PagedAttention naturally enables memory sharing through its block table. Similar to how processes share physical pages, different sequences in PagedAttention can share the blocks by mapping their logical blocks to the same physical block. To ensure safe sharing, PagedAttention keeps track of the reference counts of the physical blocks and implements the Copy-on-Write mechanism.
Example generation process for a request that samples multiple outputs.
PageAttention’s memory sharing greatly reduces the memory overhead of complex sampling algorithms, such as parallel sampling and beam search, cutting their memory usage by up to 55%. This can translate into up to 2.2x improvement in throughput. This makes such sampling methods practical in LLM services.
PagedAttention is the core technology behind vLLM, our LLM inference and serving engine that supports a variety of models with high performance and an easy-to-use interface. For more technical details about vLLM and PagedAttention, check out our GitHub repo and stay tuned for our paper.
The Silent Hero Behind LMSYS Vicuna and Chatbot Arena
This April, LMSYS developed the popular Vicuna chatbot models and made them publicly available. Since then, Vicuna has been served in Chatbot Arena for millions of users. Initially, LMSYS FastChat adopted a HF Transformers based serving backend to serve the chat demo. As the demo became more popular, the peak traffic ramped up several times, making the HF backend a significant bottleneck. The LMSYS and vLLM team have worked together and soon developed the FastChat-vLLM integration to use vLLM as the new backend in order to support the growing demands (up to 5x more traffic). In an early internal micro-benchmark by LMSYS, the vLLM serving backend can achieve up to 30x higher throughput than an initial HF backend.
Since mid-April, the most popular models such as Vicuna, Koala, and LLaMA, have all been successfully served using the FastChat-vLLM integration – With FastChat as the multi-model chat serving frontend and vLLM as the inference backend, LMSYS is able to harness a limited number of university-sponsored GPUs to serve Vicuna to millions of users with high throughput and low latency. LMSYS is expanding the use of vLLM to a wider range of models, including Databricks Dolly, LAION’s OpenAsssiant, and Stability AI’s stableLM. The support for more models is being developed and forthcoming.
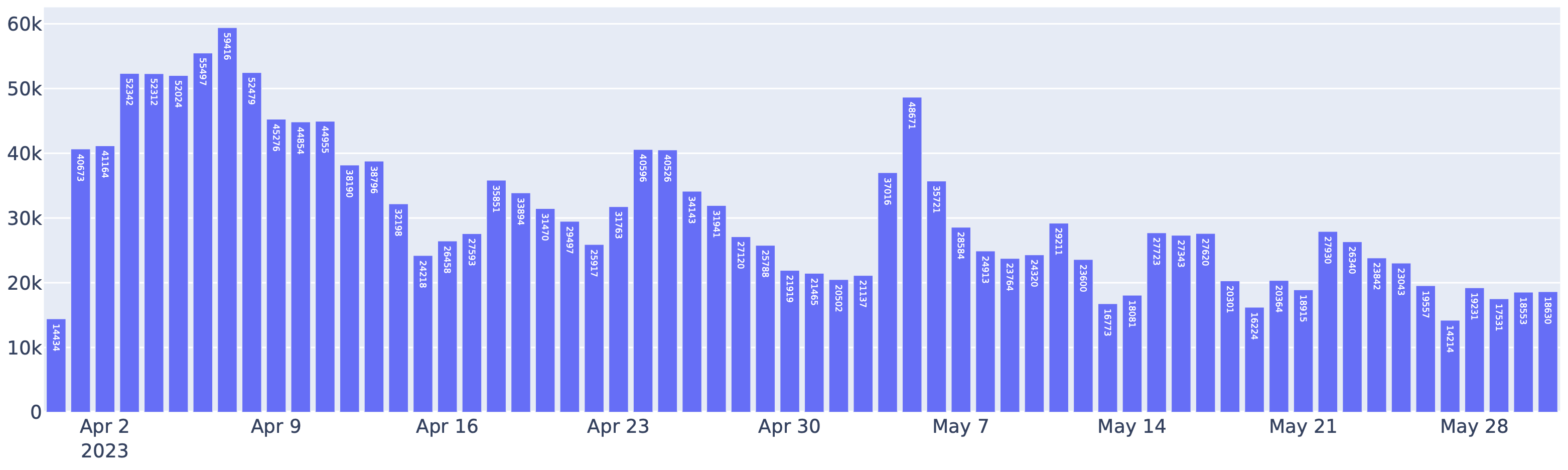
Requests served by FastChat-vLLM integration in the Chatbot Arena between April to May. Indeed, more than half of the requests to Chatbot Arena use vLLM as the inference backend.
This utilization of vLLM has also significantly reduced operational costs. With vLLM, LMSYS was able to cut the number of GPUs used for serving the above traffic by 50%. vLLM has been handling an average of 30K requests daily and a peak of 60K, which is a clear demonstration of vLLM’s robustness.
Get started with vLLM
Install vLLM with the following command (check out our installation guide for more):
$ pip install vllm
vLLM can be used for both offline inference and online serving. To use vLLM for offline inference, you can import vLLM and use the LLM class in your Python scripts:
from vllm import LLM
prompts = ["Hello, my name is", "The capital of France is"] # Sample prompts.
llm = LLM(model="lmsys/vicuna-7b-v1.3") # Create an LLM.
outputs = llm.generate(prompts) # Generate texts from the prompts.
To use vLLM for online serving, you can start an OpenAI API-compatible server via:
$ python -m vllm.entrypoints.openai.api_server --model lmsys/vicuna-7b-v1.3
You can query the server with the same format as OpenAI API:
$ curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "lmsys/vicuna-7b-v1.3",
"prompt": "San Francisco is a",
"max_tokens": 7,
"temperature": 0
}'
For more ways to use vLLM, please check out the quickstart guide.
Blog written by Woosuk Kwon and Zhuohan Li (UC Berkeley). Special thanks to Hao Zhang for the integration of vLLM and FastChat and for writing the corresponding section. We thank the entire team — Siyuan Zhuang, Ying Sheng, Lianmin Zheng (UC Berkeley), Cody Yu (Independent Researcher), Joey Gonzalez (UC Berkeley), Hao Zhang (UC Berkeley & UCSD), and Ion Stoica (UC Berkeley).
Distributed Inference with vLLM
Motivation
Serving large models often leads to memory bottlenecks, such as the dreaded CUDA out of memory error. To tackle this, there are two main solutions:
- Reduce Precision – Utilizing FP8 and lower-bit quantization methods can reduce memory usage. However, this approach may impact accuracy and scalability, and is not sufficient by itself as models grow beyond hundreds of billions of parameters.
- Distributed Inference – Spreading model computations across multiple GPUs or nodes enables scalability and efficiency. This is where distributed architectures like tensor parallelism and pipeline parallelism come into play.
vLLM Architecture and Large Language Model Inference Challenges
LLM inference poses unique challenges compared to training:
- Unlike training, which focuses purely on throughput with known static shapes, inference requires low latency and dynamic workload handling.
- Inference workloads must efficiently manage KV caches, speculative decoding, and prefill-to-decode transitions.
- Large models often exceed single-GPU capacity, requiring advanced parallelization strategies.
To address these issues, vLLM provides:
- Tensor parallelism to shard each model layer across multiple GPUs within a node.
- Pipeline parallelism to distribute contiguous sections of model layers across multiple nodes.
- Optimized communication kernels and control plane architecture to minimize CPU overhead and maximize GPU utilization.
GPU Parallelism Techniques in vLLM
Tensor Parallelism
Problem: Model Exceeds Single GPU Capacity
As models grow, a single GPU cannot accommodate them, necessitating multi-GPU strategies. Tensor parallelism shards model weights across GPUs, allowing concurrent computation for lower latency and enhanced scalability.
This approach, originally developed for training in Megatron-LM (Shoeybi et al., 2019), has been adapted and optimized in vLLM for inference workloads.

Tensor Parallelism relies on two primary techniques:
- Column Parallelism: Splitting weight matrices along columns and concatenating results after computation.
- Row Parallelism: Splitting matrices along rows, summing partial results post-computation.

As a specific example, let’s break down how this parallelism works for the MLP (multi-layer perceptron) layers in Llama models:
- Column parallelism applies to up-projection operations.
- Element-wise activation functions (e.g., SILU) operate on sharded outputs.
- Row parallelism is used in down-projection, with an all-reduce operation to aggregate final results.
Tensor parallelism ensures that inference computations are distributed across multiple GPUs, maximizing the memory bandwidth and compute available. When used, we can achieve latency improvements from effectively multiplying memory bandwidth. This occurs because sharding model weights allows multiple GPUs to access memory in parallel, reducing bottlenecks that a single GPU might encounter.

However, it requires high-bandwidth interconnects between each GPU, like NVLink or InfiniBand, to minimize overhead from the increased communication costs.
Pipeline Parallelism
Problem: Model Exceeds Multi-GPU Capacity
For extremely large models (e.g., DeepSeek R1, Llama 3.1 405B), a single node may not suffice. Pipeline parallelism shards models across nodes, each handling specific contiguous model layers.
How It Works
- Each GPU loads and processes a distinct set of layers.
- Send/Receive Operations: Intermediate activations are transmitted between GPUs as computation progresses.
This results in lower communication overhead compared to tensor parallelism since data transfer occurs once per pipeline stage.
Pipeline Parallelism reduces memory constraints across GPUs but does not inherently decrease inference latency as tensor parallelism does. To mitigate throughput inefficiencies, vLLM incorporates advanced pipeline scheduling, ensuring that all GPUs remain active by optimizing micro-batch execution.
Combining Tensor Parallelism and Pipeline Parallelism
As a general rule of thumb, think of the applications of parallelism like this:
- Use pipeline parallelism across nodes and tensor parallelism within nodes when interconnects are slow.
- If interconnects are efficient (e.g., NVLink, InfiniBand), tensor parallelism can extend across nodes.
- Combining both techniques intelligently reduces unnecessary communication overhead and maximizes GPU utilization.
Performance Scaling and Memory Effects
While the basic principles of parallelization suggest linear scaling, in practice, the performance improvements can be super-linear due to memory effects. With either Tensor Parallelism or Pipeline Parallelism, throughput improvements can arise in non-obvious ways due to the memory available for KV Cache increasing super-linearly.

This super-linear scaling effect occurs because larger caches allow for larger batch sizes for processing more requests in parallel and better memory locality, resulting in improved GPU utilization beyond what might be expected from simply adding more compute resources. In the above graph you can see between TP=1 and TP=2, we are able to increase the amount of KV Cache blocks by 13.9x which allows us to observe 3.9x more token throughput – much more than the linear 2x we would expect from using 2 GPUs instead of 1.
Further Reading
For readers interested in diving deeper into the techniques and systems that influenced vLLM’s design:
- Megatron-LM (Shoeybi et al., 2019) introduces the foundational techniques for model parallelism in large language models
- Orca (Yu et al., 2022) presents an alternative approach to distributed serving using iteration-level scheduling
- DeepSpeed and FasterTransformer provide complementary perspectives on optimizing transformer inference
Conclusion
Serving large models efficiently requires a combination of Tensor Parallelism, Pipeline Parallelism, and performance optimizations like Chunked Prefill. vLLM enables scalable inference by leveraging these techniques while ensuring adaptability across different hardware accelerators. As we continue to enhance vLLM, staying informed about new developments such as expert parallelism for Mixture of Experts (MoE) and expanded quantization support will be crucial for optimizing AI workloads.
Come to the Bi-weekly Office Hours to learn more about LLM inference optimizations and vLLM!
Acknowledgement
Sangbin Cho (xAI) for the origination of some of the figures.
将这几款工具放在一起 “掰手腕”,从性能、易用性、适用场景等多个维度来一场全方位的较量,帮你找到最称手的那个 “兵器”。
| 工具名称 | 性能表现 | 易用性 | 适用场景 | 硬件需求 | 模型支持 | 部署方式 | 系统支持 |
|---|---|---|---|---|---|---|---|
| SGLang v0.4 | 零开销批处理提升1.1倍吞吐量,缓存感知负载均衡提升1.9倍,结构化输出提速10倍 | 需一定技术基础,但提供完整API和示例 | 企业级推理服务、高并发场景、需要结构化输出的应用 | 推荐A100/H100,支持多GPU部署 | 全面支持主流大模型,特别优化DeepSeek等模型 | Docker、Python包 | Linux |
| Ollama | 继承 llama.cpp 的高效推理能力,提供便捷的模型管理和运行机制 | 小白友好,提供图形界面安装程序一键运行和命令行,支持 REST API | 个人开发者创意验证、学生辅助学习、日常问答、创意写作等个人轻量级应用场景 | 与 llama.cpp 相同,但提供更简便的资源管理 | 模型库丰富,涵盖 1700 多款,支持一键下载安装 | 独立应用程序、Docker、REST API | Windows、macOS、Linux |
| VLLM | 借助 PagedAttention 和 Continuous Batching 技术,多 GPU 环境下性能优异 | 需要一定技术基础,配置相对复杂 | 大规模在线推理服务、高并发场景 | 要求 NVIDIA GPU,推荐 A100/H100 | 支持主流 Hugging Face 模型 | Python包、OpenAI兼容API、Docker | 仅支持 Linux |
| LLaMA.cpp | 多级量化支持,跨平台优化,高效推理 | 命令行界面直观,提供多语言绑定 | 边缘设备部署、移动端应用、本地服务 | CPU/GPU 均可,针对各类硬件优化 | GGUF格式模型,广泛兼容性 | 命令行工具、API服务器、多语言绑定 | 全平台支持 |