Kubernetes Storage Performance Comparison
https://medium.com/volterra-io/kubernetes-storage-performance-comparison-9e993cb27271
If you are running Kubernetes you are likely use or want to use volumes for block storage through dynamic provisioning. The greatest dilemma is to select right storage technology for your cluster. There is not a simple answer or single test, which would tell you what is the best technology on market. Actually it very much depends on the type of workload you want to run. For the bare metal clusters you need to select right option for your use-case and integrate it on your own hardware compared to public cloud managed k8s clusters. Public cloud managed k8s offering as AKS, EKS or GKE come out of box with a block storage, but this does not mean it’s the best option. There are many situations, where failover time of default public cloud storage class takes way too long. For instance test of failed VM in AWS EBS with volume attached to a pod took more than 5 minutes to come back online on a different node. Therefore cloud native storages as Portworx or OpenEBS are trying to solve this kind of problems.
My goal was to take the most common storage solutions available for Kubernetes and to prepare basic performance comparison. I’ve decided to perform all tests on Azure AKS with following backends:
- AKS native storage class — Azure native premium
- AWS cloud volume mapped into instance — Azure hostPath with attached Azure managed disk
- OpenEBS with cStor backend
- Portworx
- Gluster managed by Heketi
- Ceph managed by Rook
Now let’s introduce each storage backend with installation description, then we will go over AKS testing cluster environment used and present the results at the end.
Storages
This section introduce storage solutions used in the tests. It describes installation procedure and advantages/disadvantages of each solution.
Native Azure Storage Class
The reason why I had chosen this storage class was to get baseline for all tests. This storage class should provide the best performance. Azure dynamically creates managed disks and map them into VMs with k8s as volume for pods.
There is no need to do anything special, just to use it. When you provision a new AKS cluster, there are automatically predefined 2 storage classes called “default” and “managed-premium”. Premium class use SSD-based high-performance and low-latency disks for the volumes.
$ kubectl get storageclasses NAME PROVISIONER AGE default (default) kubernetes.io/azure-disk 8m managed-premium kubernetes.io/azure-disk 8m $ kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE dbench-pv-claim Bound pvc-e7bd34a4-1dbd-11e9-8726-ae508476e8ad 1000Gi RWO managed-premium 10s $ kubectl get po NAME READY STATUS RESTARTS AGE dbench-w7nqf 0/1 ContainerCreating 0 29sAdvantages
- Default on AKS therefore no need to do anything.
Disadvantages
- Very slow at failover scenario — it takes sometimes almost 10 minutes to get volume re-attached to a pod on a different node.
OpenEBS
OpenEBS was completely new for me and I was very interested to test it. It represents a new Container Attached Storage (CAS) concept, where is a single microservice-based storage controller and multiple microservice-based storage replicas. It belongs to cloud native storage category together with Portworx.
It is fully open sourced and currently it provides 2 backends — Jiva and cStor. I started with Jiva and then switched to cStor. cStor has several improvements as controller and its replicas are deployed in a single namespace (the namespace where openebs is installed) or it takes raw disk instead of formatted partitions. Each k8s volume is having it’s own storage controller, the storage can scale up within the permissible limits of a storage capacity available at the node.
How to get it on AKS?
Installation on AKS is very easy.
- I had to connect to console of all k8s nodes and install iSCSI, because it uses iSCSI protocol for connection between k8s node with pod and storage controller.
apt-get update
apt install -y open-iscsi
2. Then I applied single YAML definition to my k8s cluster
kubectl apply -f https://openebs.github.io/charts/openebs-operator-0.8.0.yaml
3. At next step the OpenEBS controller discovered all of my disks at underlying nodes. But I had to manually identify my additional AWS managed disk attached to it.
kubectl get disk NAME AGE disk-184d99015253054c48c4aa3f17d137b1 5m disk-2f6bced7ba9b2be230ca5138fd0b07f1 5m disk-806d3e77dd2e38f188fdaf9c46020bdc 5m4. Then I added those disks into custom k8s resource StoragePoolClaim, which is referenced by standard StorageClass.
— apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: openebs-custom annotations: openebs.io/cas-type: cstor cas.openebs.io/config: | – name: StoragePoolClaim value: “cstor-disk” provisioner: openebs.io/provisioner-iscsi — apiVersion: openebs.io/v1alpha1 kind: StoragePoolClaim metadata: name: cstor-disk spec: name: cstor-disk type: disk maxPools: 3 poolSpec: poolType: striped disks: diskList: – disk-2f6bced7ba9b2be230ca5138fd0b07f1 – disk-806d3e77dd2e38f188fdaf9c46020bdc – disk-184d99015253054c48c4aa3f17d137b1After I had finished these steps I was able to dynamically provision a new volumes via k8s PVC.
Advantages
- Open source
- Maya does great job at the resource usage visualisation. You can easily deploy several services in your k8s cluster and easily setup monitoring and logging to collect all important aspects of your cluster. It’s a perfect tool for debugging.
- CAS concept in general — I really like the idea behind container storage and I believe there is the future.
- Community behind OpenEBS — I was able to resolve any my problem or question in matter of minutes. Team on Slack was very helpful.
Disadvantages
- immaturity — OpenEBS is a rather new project and it has not reached stable version yet. The core team is still working on backend optimizations, which should significantly improve the performance in the following months.
- iSCSI connection between Kubelet and storage controller is implemented by k8s services, which might be a problem in some overlay network CNI plugins like Tungsten Fabric.
- It’s required to install additional software (iSCSI) on Kubernetes nodes making it more than impractical in the case of managed Kubernetes clusters.
Note: OpenEBS team adjusted my test case scenarios there https://github.com/kmova/openebs/tree/fio-perf-tests/k8s/demo/dbench
Portworx
Portworx is another container native storage designed for kubernetes, with focus on highly distributed environments. It is a host-addressable storage, where each volume is directly mapped to the host it is attached on. It provides auto-tuning based on type of application I/O. More information is available there. Unfortunately it is the only storage solution in this blog, which is not open sourced. However it provides 3 nodes trial for free.
How to get it installed on AKS?
Installation on AKS was also very easy. I used Kubernetes spec generator available at their website.
- I selected Portworx hosted etcd to simplify my setup and filled k8s version 1.11.4.
- I had to modify Data Network Interface to azure0, because I was using Azure cni with advanced networking. Otherwise Portworx would be using IP address from docker bridge instead of VM interface.
- As a last step, the website generator provided me the rendered k8s YAML manifest to apply to my cluster.
- After bootstrap I got Portworx pod running per k8s node
I created storage class with high priority and 3 replicas and then I could provision k8s pvc.
root@aks-agentpool-20273348-0:~# kubectl get storageclass -o yaml portworx-sc apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: creationTimestamp: 2019-01-28T21:10:28Z name: portworx-sc resourceVersion: “55332” selfLink: /apis/storage.k8s.io/v1/storageclasses/portworx-sc uid: 23455e40-2341-11e9-bfcb-a23b1ec87092 parameters: priority_io: high repl: “3” provisioner: kubernetes.io/portworx-volume reclaimPolicy: Delete volumeBindingMode: ImmediateAdvantages
- Easy to deploy — website configurator with detailed configuration.
- Configurator for AKS cluster without any additional steps needed as ceph or glusterfs.
- Cloud native storage — it can run on HW clusters as well as public clouds.
- Storage aware class-of-service (COS) and application aware I/O tuning
Disadvantages
- Closed source — Proprietary vendor solution.
GlusterFS Heketi
GlusterFS is a well known open source storage solution. It is along Ceph, one of the traditional open source storage backed by RedHat. Heketi is RESTful volume management interface for GlusterFS. It provides a convenient way to unleash the power of dynamically provisioned GlusterFS volumes. Without this access, you would have to manually create GlusterFS volumes and map them to k8s pv. You can read more about GlusterFS there.
How to get it installed on AKS?
I used the default Heketi quick start guide.
- First I created a topology file with disk and hostnames based on sample one.
- Since Heketi is developed and tested mainly on RHEL based OS, I had an issue on AKS with Ubuntu hosts with incorrect path to kernel modules. Here is a PR to fix this issue.
3. Another issue on AKS I hit was a non empty disk, so I used wipefs to clean up disk for glusterfs. This disk was not used before for anything else.
wipefs -a /dev/sdc
/dev/sdc: 8 bytes were erased at offset 0x00000218 (LVM2_member): 4c 56 4d 32 20 30 30 31
4. As last step I ran command gk-deploy -g -t topology.json, which deployed glusterfs pod on each node controlled by heketi controller.
root@aks-agentpool-20273348-0:~# kubectl get po -o wide NAME READY STATUS RESTARTS IP NODE NOMINATED NODE glusterfs-fgc8f 1/1 Running 0 10.0.1.35 aks-agentpool-20273348-1 glusterfs-g8ht6 1/1 Running 0 10.0.1.4 aks-agentpool-20273348-0 glusterfs-wpzzp 1/1 Running 0 10.0.1.66 aks-agentpool-20273348-2 heketi-86f98754c-n8qfb 1/1 Running 0 10.0.1.69 aks-agentpool-20273348-2Then I faced issue with dynamic provisioning. Heketi restURL was unavailable for k8s control plane. I tried kube dns record, pod IP and svc IP. Neither worked. Therefore I had to create manually volume via Heketi CLI.
root@aks-agentpool-20273348-0:~# export HEKETI_CLI_SERVER=http://10.0.1.69:8080 root@aks-agentpool-20273348-0:~# heketi-cli volume create –size=10 –persistent-volume –persistent-volume-endpoint=heketi-storage-endpoints | kubectl create -f – persistentvolume/glusterfs-efb3b155 created root@aks-agentpool-20273348-0:~# kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE glusterfs-efb3b155 10Gi RWX Retain Available 19sThen I had to map existing PV to PVC for my dbench tool.
More output from Heketi Gluster installation on k8s.
Advantages
- Proven storage solution
- Lighter than Ceph
Disadvantages
- Heketi is not designed for public managed k8s. It works well with HW clusters, where installation is easier.
- Not really designed for “structured data”, as SQL databases. However you can use Gluster to backup and restore the database.
Ceph Rook
I had experience with installing and running Ceph together with OpenStack private clouds. It had always required to design specific HW configuration, generate pg groups based on type of data, configure journal SSD partitions (before bluestore) and define the crush map. Therefore when I first time heard about using Ceph in 3 node k8s cluster, I could not believe that it could actually work. However I got pretty impressed by Rook orchestration tool, which did all that painful steps for me and together with k8s orchestration provided a very easy way to handle whole storage cluster installation.
How to get it installed on AKS?
In default installation Rook does not require any special steps and if you are not looking for advanced configuration, it is very smooth.
- I used Ceph quickstart guide available at https://github.com/rook/rook/blob/master/Documentation/ceph-quickstart.md#ceph-storage-quickstart
- I had to configure FLEXVOLUME_DIR_PATH specific for AKS, because they use /etc/kubernetes/volumeplugins/ instead of default Ubuntu /usr/libexec. Without this change pvc cannot be mounted by kubelet.
3. Then I had to specify, what device I want to use in deviceFilter. My additional disk was always on /dev/sdc
4. After installation I created Ceph block pool and storage class with following configuration
5 . At the end I checked the status via following deployment toolbox https://github.com/rook/rook/blob/master/Documentation/ceph-toolbox.md
Advantages
- Robust storage running in large production environment
- Rook makes life-cycle management much more simple.
Disadvantages
- Complex — it is more heavy and not even suitable to run in the Public Cloud. It is good to run only on HW clusters with right configuration.
AKS Testing Environment
I provisioned basic Azure AKS cluster with 3 VMs. To be able to connect managed Premium SSD I had to use at least VM size type E. Therefore I selected Standard_E2s_v3 with only 2 vCPU and 16GB RAM.
Every AKS cluster provisiones automatically second resource group (RG) MC_<name>, where you can find all VMs, NICs, etc. Inside of this RG I created 3x 1TB premium SSD managed disks and manually attached them to each VM.
This allowed me to get 1TB of empty disk in each instance dedicated to my tests. According to Azure, the estimated performance should be around 5000 IOPS and 200 MB/s throughput depending on VM and disk size. The real numbers are visible in last section.
Performance Results
IMPORTANT NOTE: The results from individual storage performance tests cannot be evaluated independently, but the measurements must be compared against each other. There are various way how to perform comparative tests and this is one of the simplest approaches.
To run our tests I decided to use existing load tester called Dbench. It is k8s deployment manifest of pod, where it runs FIO, the Flexible IO Tester with 8 test cases. Tests are specified in the entrypoint of Docker image:
- Random read/write bandwidth
- Random read/write IOPS
- Read/write latency
- Sequential read/write
- Mixed read/write IOPS
Full test outputs from all tests are available at https://gist.github.com/pupapaik/76c5b7f124dbb69080840f01bf71f924
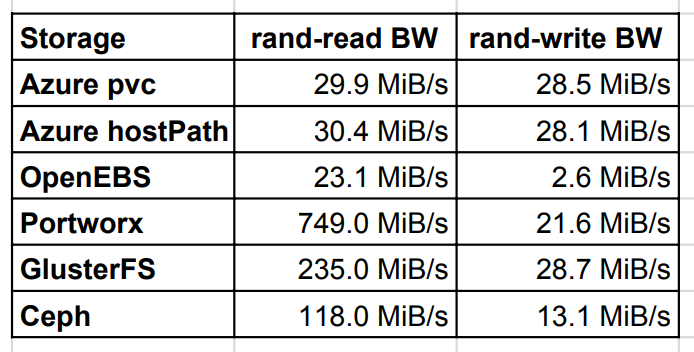
Random read/write bandwidth
Random read test showed that GlusterFS, Ceph and Portworx perform several times better with read than host path on AWS local disk. The reason is read caching. The write was the fastest for GlusterFS and Portworx, which got almost to the same value as a local disk.
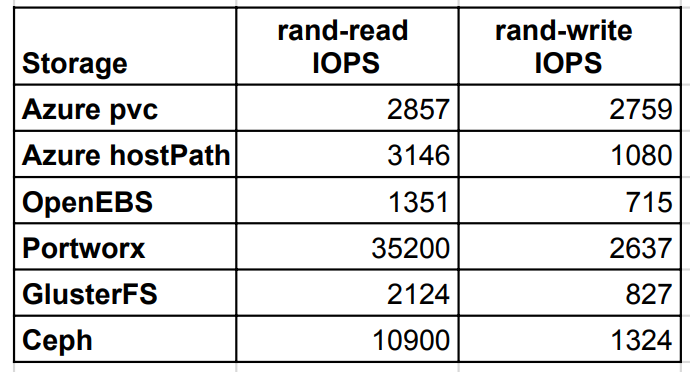
Random read/write IOPS
Random IOPS showed the best result for Portworx and Ceph. Portworx got almost same IOPS on write as native Azure pvc, which is very good.
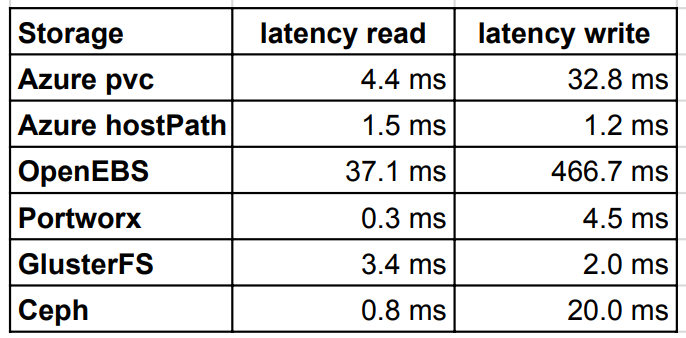
Read/write latency
Latency test returned interesting results, because native Azure pvc was slower than most of other tested storages. The best read speed was achieved Portworx and Ceph. However for the write,GlusterFS was better than Ceph. OpenEBS latency was very high compared to other storages.
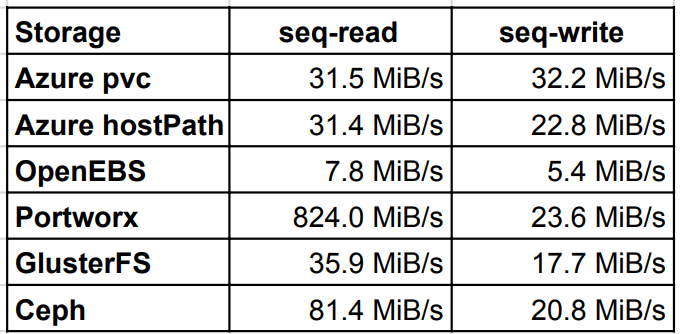
Sequential read/write
Sequential read/write tests showed similar results as random test, however Ceph was 2 times better on read than GlusterFS. The write results were almost all on the same level except the OpenEBS which performed very poorly.
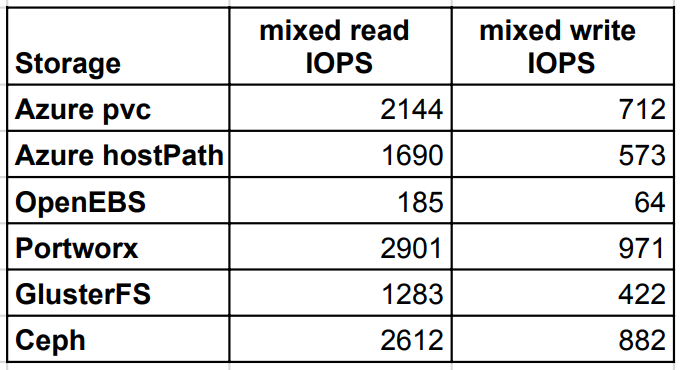
Mixed read/write IOPS
The last test case verified mixed read/write IOPS, where Portworx and CEPH delivered better IOPS than native Azure pvc even on write operations.
Conclusion
This blog showed simple storage engine comparison using single volume backed by various storage setups without any extra performance tuning. Please take the results just as one of the criteria during your storage selection and do not make final judgement just on my blog data.
If we ignore native Azure pvc or hostPath, we can conclude from the tests that:
- Portworx is the fastest container storage for AKS
- Ceph is the best open source storage backend for HW clusters. For public clouds there is too much operational complexity, which at the end does not add so much value comparing to the default cloud storage class.
- OpenEBS is a great concept, but requires more backend optimizations, which will be available soon.
It would be interesting to get also scaling performance data to see how those results change and what storage engine scales the best. Another interesting comparison would be on the consumed resources as CPU and RAM by individual storage engines. I will keep an eye on them and share more observations in the future.