Snowflake
随着Snowflake去年9月宣布GA on Microsoft Azure,很多基于Microsoft生态系统的客户开始表现出对Snowflake的强烈兴趣。说到Snowflake这款产品,可谓现今数据仓库解决方案市场上最火的香馍馍。在把战场从AWS烧到Azure之后,Snowflake俨然进一步定义了现代数据仓库的发展方向。我有幸在为一零售巨头客户的数据架构咨询服务中参与了Snowflake的部署,将原有的本地数据平台升级成为建立在在Azure和Snowflake上的现代云端解决方案。以下分享一些对Snowflake架构以及数据仓库未来的理解。
不同于传统的三类云服务,Snowflake提出了data-warehouse-as-a-service(DaaS)的概念。什么是DaaS?可以简单理解为原生于云端并专注于数据仓库的SaaS服务。
No hardware, no software, and completely maintained on cloud
注意Snowflake的云端原生性,和很多数据仓库提供商支持云端服务并非同一概念。传统大厂例如Oracle,Teradata,Netezza,乃至后来穿上马甲的AWS Redshift,都并非诞生在云时代的产品。尽管或多或少支持云端,因为本身产品架构的局限性,他们常常被证明并不能良好地解决很多现代企业面对的各种数据需求与问题。
用户要什么
数据的重要性不言而喻,但用户需要怎样的数据平台与服务却并不是三言两语就能说清的一件事。或者说,从Bill Inmon定义数据仓库之后至今50年,面对眼花缭乱的技术和产品,企业在数据仓库的解决方案中最需要的价值服务在哪里?
1、性能(Performance)
无论在什么行业,客户一定会要求:快!更快!性能是数据平台的准入门槛。如何在petabyte级别的海量数据量面前展现优秀的性能,同时尽可能的降低成本,是传统数据仓库的死穴。只有借助云端的资源才有可能在这个数量级上讨论这些问题。
2、并发性(Concurrency)
数据仓库的业务逻辑是提供给企业一个统一版本的数据层。当不同的用户同时访问同一数据时,如何保证性能不受影响是并发必须解决的问题。尤其在self-BI的时代,终端用户不用通过IT生成报表,数据要求越发实时性,安全需求更加复杂,都给数据仓库的建设提出新的挑战。
3、易用性(Simplicity)
传统数据库,乃至新兴的开源系统,都逃不出运维的魔咒。大部分的数据解决方案都建立在必须雇佣专业的admin进行调试和维护的假设上。事实上,企业不应过多投入到自己不擅长的技术领域,而应该专心于业务上的开发以创造价值。相反,数据平台则应该尽可能多地担任自动化的角色,涵盖底层服务,面对用户提供最简单易用的功能。
全新的底层架构
针对以上的需求以及现有技术的诸多局限性,Snowflake提出了独特的存储、计算以及管理服务分离的架构。这里我们要先提到一些传统架构以及其代表性的产品。

Shared-disk顾名思义,数据存储在同一位置,大家享用同样的资源。这种架构很容易在多用户访问的情况下导致系统崩溃,同时也难以满足高频读写、数据复制与迁移等需求。Oracle Exadata采用了这种传统的数据仓库架构,几乎在延展性和并发性上都落后于时代的发展。
Shared-nothing是近年来更主流的一种做法。系统通过优化规则将资源分摊到各个节点,而每个节点不共享任何数据。这样一来,数据的处理过程就不存在争抢资源的情况,从而提供更有效率的延展性和并发性。像Netezza,Teradata,以及Redshift都采用了这样的架构,这也是Hadoop工作的基本原理。这种架构对于数据仓库应用来说有独特的问题,那就是节点资源没有将存储和计算分开。举个例子,当升级或者扩容发生时,系统需要重新分配节点资源,那么数据本身就会面临大量的迁移。这样的操作不仅费时费力费钱,也会大概率降低甚至暂停数据的查询功能,给终端用户造成使用上的影响。
Snowflake在Shared-nothing的基础上提出了Multi-cluster, shared data的概念。这种架构的关键在于将存储和计算彻底分离,从本质上解决了传统架构的痛点。
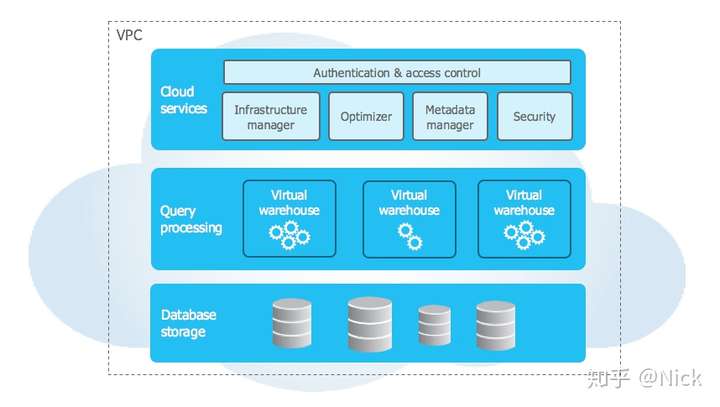
1、存储层(Storage)
存储层目前支持AWS S3和Azure Blob,相信Google Storage在可期的未来也会兼容。所有数据在存储层被全部加密以及columnar压缩,最大限度的优化存储效率。理论上讲,存储层可以在无关计算资源的情况下进行无限扩容,所以我们不需要加任何节点就能自动沉淀所有数据,这也是为什么Snowflake也可以作为data lake的原因。从表结构上讲,Snowflake将所有表自动划分为接近固定大小的micro-partition,用以支持更加高级的time travel和data sharing功能。举个例子,即使对数据库进行了clone,在逻辑上有了两个数据库,而底层的存储仍然只有一个版本。这也很好契合了数据仓库在并发性上的业务逻辑。
2、计算层(Compute)
计算层由诸多virtual warehouse组成,其本质就是处理数据的虚拟机节点。Snowflake很贴心地用T-shirt尺寸定义了算力,相比较其他云计算资源,极大地简化了provision的过程。由于计算层独立于存储层存在,我们可以想象出很多传统架构中遇到瓶颈的应用场景。譬如可以随时提高或降低计算资源以应对需求,可以在搬运数据的同时进行查询,可以给各个LOB提供合适的资源并独立出ETL和DevOps的处理需求。而最令人兴奋的是,这些不同计算资源看到的都是同一版本的数据。
3、服务层(Services)
服务层的独立是另一个我认为Snowflake走在正确道路上的原因。它由众多global services组成,涵盖了我们传统意义上数据仓库的诸多admin任务,包括operation management,optimization,tuning,security,availability,metadata,caching等等。这一层还有transaction management这个重要的使命,对所有计算层的virtual warehouse进行管理,保证不同的数据处理请求被高效稳定地应用在存储层的同一数据上。服务层解决了数据仓库易用性的问题,目前我还没有看到任何一款数据平台产品能够帮用户处理这么多的非功能性任务。即使是同为云数据仓库的Azure Data Warehouse,需要的管理和运维成本不可同日而语。
数据仓库的进化
Snowflake的架构完美诠释了数据仓库产品的进化史,它被设计成为精准的制导导弹用于解决众多的历史遗留问题。而Snowflake能做到这一点,自然是因为它诞生在云服务的企业化应用最成熟的时代。技术上,Snowflake可以一身轻松地摆脱底层引擎的限制,转而尽可能地借用现成的资源。无论是存储上用到的S3, Blob, 还是计算上的VM,都是最基础(也最便宜)的云端资源。这些资源对于企业来说就像我们生活中的水和电一样,而Snowflake则通过整合这些基础资源,制造出了电视机、洗碗机、微波炉这样解决具体业务问题的产品。
除了上文提到的那些传统数据仓库提供商,我们也能看到很多其他符合大数据和云服务气质的解决方案。例如Hadoop,Hive,Spark这样的开源大数据平台;或者是AWS Redshift, Azure Data Warehouse,Google BigQuery这样的云数据仓库。特别是AMG这三大主流云服务提供商,都具备自家成熟的云数据仓库服务,似乎在很大程度上和Snowflake形成了直接的竞争关系。尽管如此,我们在为客户做竞品分析的过程中,依然能发现这些产品服务在应用上的众多差别。除了技术上细节的讨论,我们应该注意到这其中策略上更有趣的问题。为什么Microsoft在力推Azure Data Warehouse的同时,还要和Snowflake这样的SaaS服务商合作来抢自己的生意呢?这里面的商业逻辑暂不深究,我们且谨记住,云计算对现代商业的性质已经变成了水和电。对服务提供商来说,重要的不是你买不买我家的电视机,重要的东西只有一个词:Consumption!
这些年做data analytics咨询也发现了一些有趣的现象。无论是对客户还是产品的提供方,传统的数据仓库(DW)和商业智能(BI)开始被疏远,大部分新的项目则来自与本地到云端的integration和migration的需求。在云计算和大数据的冲击下,成熟的数据仓库理论甚至成为了架构里的政治不正确。譬如我上一个服务过的软件公司,就明确表示过像EDW和ETL这样的字眼不能出现在市场定位中。
为什么大家开始对数据仓库讳莫如深呢?恐怕传统的数据仓库给人留下过许多不好的印象:花钱多, 灵活度低,令人头疼的运营管理等等。好在近年来,modern data warehouse这个概念火了起来,利用云计算的壳解释了现代数据仓库存在的合理性。而随着企业日新月异的数据需求和技术的进步,更新的架构层出不穷。有没有一种服务能提供把数据平台上的data lake, data mart, 以及semantic layer这些元素都取代的架构呢?未来的数据仓库又会在应用中扮演怎么样的角色呢?

在我看来,DaaS既是Function-as-a-Service (FaaS)的一种,也是SaaS的自然延伸,最终目的都是尽可能远离IaaS以及服务本身的运维,把资源最大限度地解放出来进行业务功能的开发。Snowflake是目前DW/BI领域最接近这种serverless概念的产品,也许它会成为云时代最好的数据仓库,那它会是数据仓库的终极形态吗?我们拭目以待。
DB-Engines 4 月份流行度排行已更新,基于 3 月份的整体数据变化。
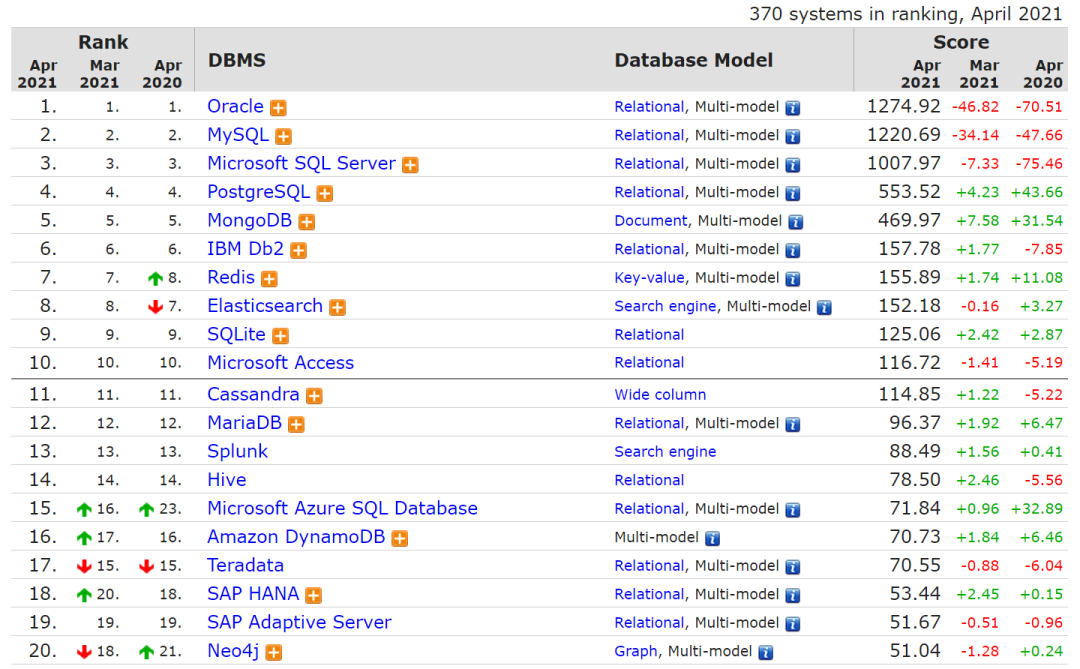
从总榜来看,前十数据库的排名和上个月保持一致。
虽然排名没有变动,但单个数据库的分数却变化不少。
稳居前三的 Oracle、MySQL 和 Microsoft SQL Server 分数出现了较大幅度的下跌,分别减少 46.82、34.14 和 7.33 分。
其中 SQL Server 分数已经连续下跌了两个月。若与去年同期的数据相比,三者下跌的分数平均已达到 64 分。
后起之秀 PostgreSQL 和 MongoDB 依旧保持着稳步上升的趋势,分数与上个月相比有小幅度增加,与去年同期相比也平均增加了 40 分左右。
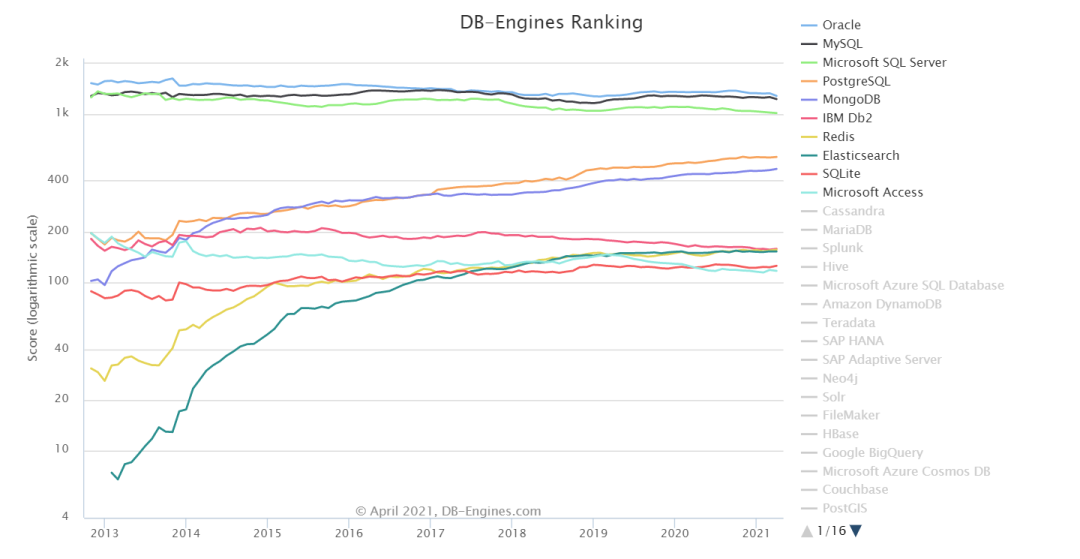
▲ 前十数据库的分数变化走向
对于排名 20 之后的数据库,以年为维度,排名显著上升的数据库有 Snowflake 和 Clickhouse,Snowflake 由去年同时期的第 100 名上升到现在的第 29 名,后者也从第 71 名上升至第 50 名。
两者都属于云数据仓库,Snowflake 的母公司去年上市后更是获得巴菲特青睐,股价飙升。相信这也是它排名上升的主要原因。

最后看看各类型数据库的排名情况。
关系数据库前 10 名

Key-Value 数据库前 10 名
文档数据库前 10 名
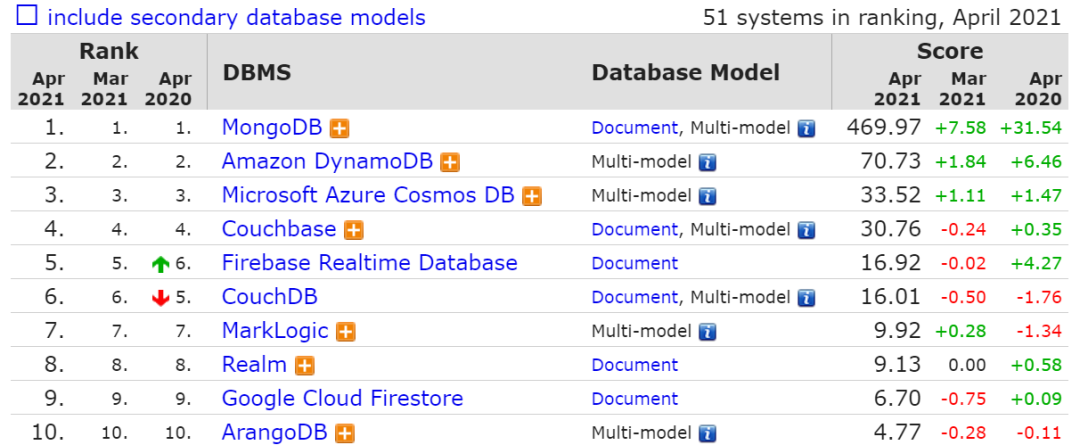
时序数据库前 10 名
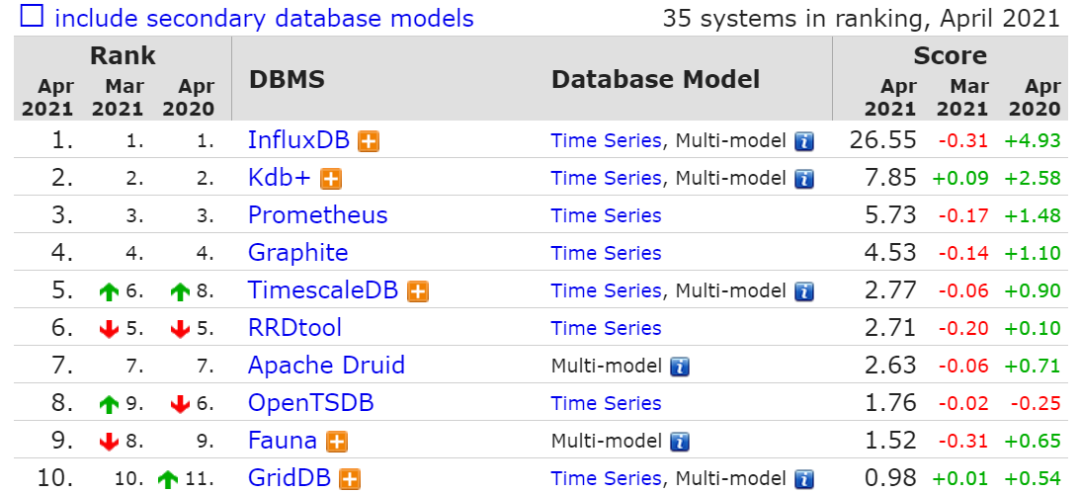
图数据库前 10 名
DB-Engines 根据流行度对数据库管理系统进行排名,排名每月更新一次。
排名的数据依据 5 个不同的指标:
- Google 以及 Bing 搜索引擎的关键字搜索数量
- Google Trends 的搜索数量
- Indeed 网站中的职位搜索量
- LinkedIn 中提到关键字的个人资料数
- Stackoverflow 上相关的问题和关注者数量
这份榜单分析旨在为数据库相关从业人员提供一个技术方向的参考,其中涉及到的排名情况并非基于产品的技术先进程度或市场占有率等因素。无论排名先后,选择适合与企业业务需求相比配的技术才是最重要的。