Network security for microservices with eBPF
https://medium.com/@beatrizmrg/network-security-for-microservices-with-ebpf-bis-478b40e7befa
Several open-source Kubernetes tools are already using eBPF. Mainly related to networking, monitoring, and security.
The intention of this post is not to provide complete coverage of all eBPF aspects, but rather tries to be a informational starting point guide, from the understanding of Linux kernel BPF concept, through the advantages and features that brings to microservices environments, to some known tools that currently make use of it, such Cilium or Weave.
Understanding eBPF
Berkely Packet Filters, short BPF, is an instruction set architecture that was first introduced by Steven McCanne and Van Jacobso in 1992, as a generic packet filtering solution for applications such as tcpdump, that was the first use case, and is long present in Linux Kernels.
BPF can be regarded as a minimalistic “virtual” machine construct. The machine it abstracts has only a few registers, stack space, an implicit program counter and a helper function concept that allows for side effects with the rest of the kernel.
This in-Kernel VM translates bpf byte-code to the underlying architecture and provides packet filtering.
Previous to this, packets needed to be copied to user space in order to be filtered, low efficiency and very expensive in resources.
A Verifier checks the program does not generate a loop and guarantees that the program comes to a halt.
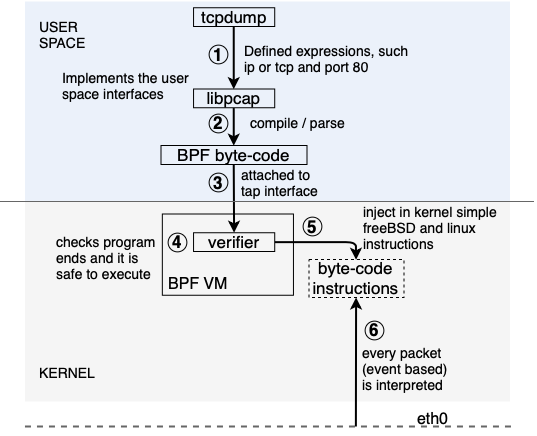
In recent years, the Linux community replaced the nowadays referred to as classic BPF (cBPF) interpreter inside the kernel, which was limited to packet filtering and monitoring, with a new instruction set architecture called eBPF.

Extended BPF brings more flexibility and programmability aspects and new use cases along with it such as tracing, bfp system call externally usable, secure access to kernel memory or faster interpretation, Just-In-Time (JIT) compiler has been upgraded too to translate eBPF for running programs with native performance.
Also the ability to attach bpf programs to other kernel objects (cBPF could only be attached to sockets for socket filtering). Some supported attach points are: Kprobes, Tracepoints, Network schedules, XDP (eXpress Data Path). This last one, together with shared data-structures (maps) can be used to communicate user space and kernel or sharing information between different BPF programs, a relevant use case for microservices.
Creating a BPF program
One important aspect of eBPF is the possibility of implementing programs from high-level languages such C. LLVM has an eBPF back end for emitting ELF files that contain eBPF instructions, front ends like Clang can be used to craft programs.
After a backend conversion to byte-code, bpf programs are loaded with bpf() system call and validated for safety. JIT compile the code to the CPU architecture and the programs are attached to kernel objects, being executed when events happen on those objects. For example when a network interface emits a packet.
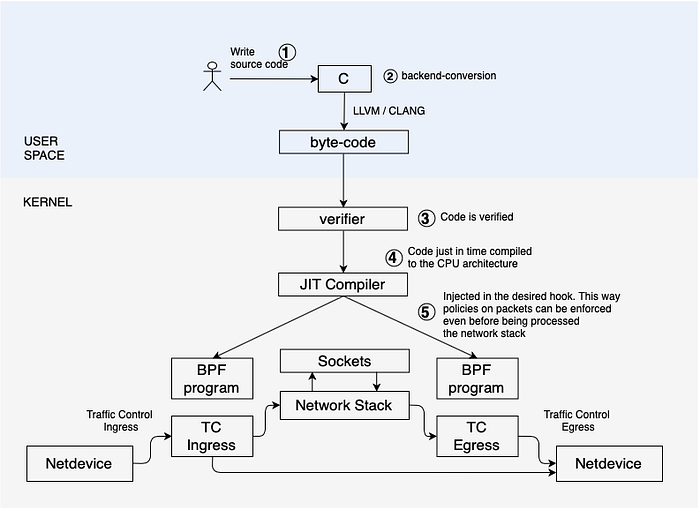
Policies dictated by BPF programs can be enforced even previous network stack is processed, this achieves the best possible packet processing performance since cannot get processed at an earlier point in software.
Already thinking in writing your own eBPF programs? These useful resources can get you to it:
- Using clang/LLVM to compile programs
- Go bindings for creating BPF programs
- Go library that provides utilities for loading, compiling, and debugging eBPF programs
Container security policies with IPTables
Historically containers runtimes such Docker, apply security policies and NAT rules per-container level by configuring IPTables rules in the docker hosts.
Notice that 5 hops of calls take place:
- connect() system call
- construct the packet
- forward packet through vETH pair
- apply iptables in host
- drop or forward
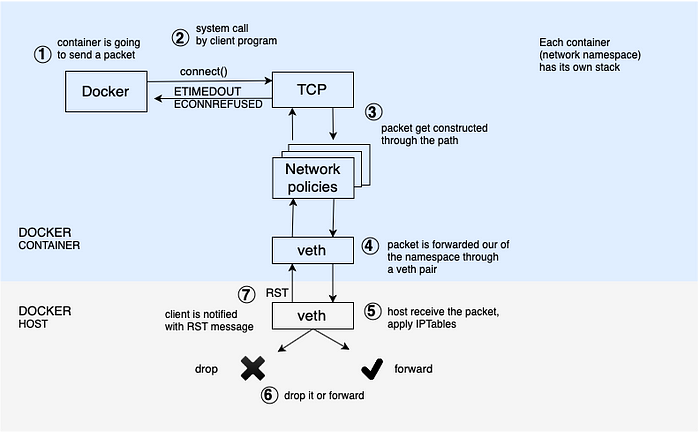
With iptables, policies can be applied for instance, but only based on layer 3 and layer 4 parameters. The construction of the whole packet is needed. And also forwarding is involved in order to reach to a decision.
Container security policies with eBPF
Without the limitations of using iptables, eBPF policies can be applied on the system call, before entering the stack or construct the packet.
As eBPF attaches to the container network namespace, all the calls are intercepted and filtered on the spot.
Also, it allows to apply security policies based on application level verbs. For each microservice we can work not only wit L3 and L4 policies, also L7 such REST GET/POST/PUT/DELETE or specific paths /service1, /restricted.

eBPF is replacing iptables
Learn from the hand of a linux kernel contributor why is the kernel community replacing iptables, problems face by Kubernetes kube-proxy or why the use of polices based on IP addresses and ports in the world of containers in which the IPs can change within seconds is not the right approach.
There are several open source Kubernetes tools benefiting from the high-performance and low-latency provided by eBPF. Specially in monitoring, security and networking fields.
Cilium: dynamic network control and visibility
Cilium networking project makes heavy use of eBPF to route and filter network traffic for container-based systems. It can dynamically generate and apply rules without making changes to the kernel itself.

Example of L3/L4 policy that would enable app1 accessible only from app2 but not from app3, and only if using port 80.
[{
endpointSelector: {matchLabels:{id:app1}},
ingress:[{
fromEndpoints:[
{matchLabels:{id:app2}}
],
toPorts:[{
ports:[{ports:80, protocol:tcp}]
}]
}]
}]
We can also apply tighter security and use policies on the call level, for example make calls to /public path available but not to /restricted path.
This is how Cillium project works
The Agent runs on each host, translating network policy definitions to BPF programs, instead of managing iptables. These programs are loaded into the kernel and attached to the container’s virtual ethernet device. When they are executed, rules applied on each packet that is sent or received.

Because BPF runs inside the Linux kernel, Cilium security policies can be applied and updated without any changes to the application code or container configuration.
Read more about Cillium:
- API-aware Networking andSecurity
- Component overview
- To learn more about how Cilium uses eBPF, take a look at the project’s BPF and XDP reference guide
How Cillium enhances Istio
There are multiple levels of integration between Cilium and Istio that make sense for both projects.
Improving Istio datapath performance and latency
The following image from a last year post in Cillium Blog, shows latency measurements for most common high performing proxies present in microservices environments.
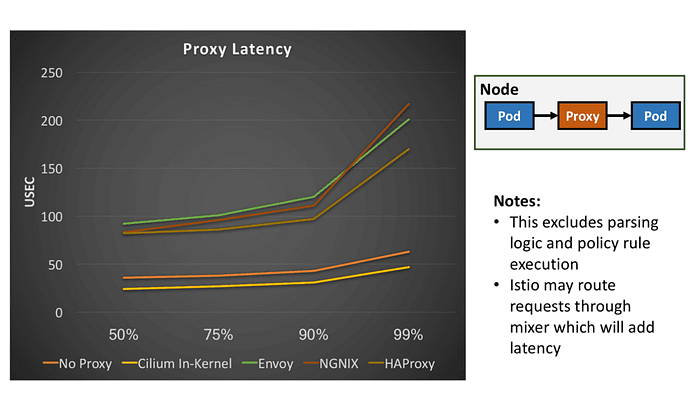
How is it possible that no proxy at all is not faster than using an in-kernel proxy? The difference is thus the cost of the TCP/IP stack in the Linux kernel.
With socket redirect, the in-kernel proxy is capable of having two pods talk to each other directly from socket to socket without creating a single TCP packet. This is very similar to having two processes talk to each other using a UNIX domain socket. The difference is that the applications can remain unchanged while using standard TCP sockets.
How else can Istio benefit from Cillium?
While the key aspect in which Istio can enrich from Cillium is the difference in datapath performance and latency, there are other aspects to consider.
The post Istio 1.0: How Cilium enhances Istio with socket-aware BPF programs, go into some of the details on how Cilium Increase Istio Security, Enable Istio for external services, and the already mentioned improve Performance.
A few more BPF use cases
- “kubectl exec” audit. Kubernetes audit allows administrators to log and audit events that take place in a K8s cluster, for example we could see that someone has used kubectl exec to enter a container, but it is not provided the level of visibility that would allow us to see which commands were executed. A BPF program could be attach to record any commands executed in the
kubectl execsession and pass those commands to a user-space program that logs those events. - Prometheus exporter for custom bpf metrics
- AWS Firecracker. Using Seccomp BPF to restrict system calls. Linux has more than 300 system calls available, seccomp (Secure Computing) is a Linux security facility used to limit the set of syscalls that an application can use. With the original implementation if an application attempted to do anything beyond reading and writing to files it had already opened, seccomp sent a
SIGKILLsignal. seccomp-bpf enables more complex filters, also custom ones applyed in the form of BPF programs. - Facebook’s BPF-based load balancer with DDoS
- Netflix has been utilizing BPF for performance profiling and tracing
- Sysdig and Falco recently announced a shift in their core instrumentation technology, adapting to take advantage of eBPF.
