chalstiaozheng
https://zhuanlan.zhihu.com/p/345143459
目标人群:没有微观数据库处理经验的人群
1 引言
每逢毕业季或中期检查前,总有一群人拿着官网申请的微观数据无从下手,一筹莫展,或困于陌生的问卷结构,或疏于操作STATA或SPSS软件,或在处理过程中被各类突发问题搞得猝不及防,甚至在第一步软件下载时破防,无奈之下不得不到橙色软件或海鲜市场花钱求助。
各大官方数据为同学们开展研究提供了极大便利,例如CHARLS中国健康与养老追踪调查、CGSS中国综合社会调查、CFPS中国家庭追踪调查、CHFS中国家庭金融调查、CMDS中国流动人口动态监测数据,以及CLDS、CLASS、CEPS、CHIP等大型数据库,以上数据本人均有处理经验。问题在于,如果想要合理处理数据完成论文,不仅需要熟悉问卷结构,还需要熟练使用STATA软件,根据研究设计清洗变量,如果遇到面板数据的处理问题,可能会涉及跨表合并、跨年合并、乱码转码等一系列困扰。
那么,我们该怎么快速学会清洗微观数据呢?由于北京大学的中国健康与养老追踪调查数据CHARLS的处理过程相对其他数据而言显得比较复杂,为很多使用数据的同学带来一定困扰,下面就以CHARLS为例,详细讲讲怎么清洗变量、合并数据和处理乱码。
2 准备工作
我们需要从官方渠道申请数据,CHARLS官网需要注册并进行认证,但是认证速度中等,一般能在3-5个工作日内完成,还是建议急于上手的同学尽早申请。
北京大学中国健康与养老追踪调查官网:
下载好数据之后,先新建三个文件夹:rawdata、workingdata、dofile和output,分别存储CHARLS原始数据、CHARLS工作数据、do文档和结果文档。这么复杂的准备工作是为了帮助在后续清洗过程中理清思路,不至于手忙脚乱,这一步看似鸡肋,实则在处理繁复的数据中尤为重要!
dofile:存放do文件,即stata的代码文件
rawdata:存放原始数据,此文件夹下的数据,只读不写
workingdata:存放工作数据,即对原始数据进行处理后生成的数据,分析通常直接读取工作数据
output:存放分析结果(图片、表格等)
3 常用数据清洗代码
3.1 导入数据
代码导入
import excel using "rawdata/wage.dta", firstrow clear界面导入
在界面分别依次点击 File→Import→excel spreadsheet
快捷键导入
ctrl+O,直接选择文件
3.2 浏览变量
/*--浏览数值类型、标签 --*/
describe
browse
browse if IQ > 130
browse in 1/10
/*--具体描述变量: range, unique, missing, mean, std, percentiles --*/
codebook
codebook wage
codebook medu if brthord ==.
/*--描述性统计: obs, mean, sd, min, max--*/
summarize
summarize wage
sum wage, detail
/*--分组描述 更常用--*/
tabstat educ, stat(mean min max)
tabstat educ, stat(mean min max) by(urban)
tabstat educ meduc feduc, stat(mean min max median variance n)
/*--改变变量在数据集中的位置 --*/
order feduc meduc //把关注的变量放在最前面
order IQ, last //把关注的变量放在最后面3.3 生成新变量
/*--用gen生成变量--*/
generate age_sq = age^2
gen logwage = log(wage)
gen hourly_wage = wage/hours
gen male = 1 if gender == "male"
replace male = 0 if gender == "female"
/*--生成变量: egen--*/
egen IQ_rank = rank(IQ) //Generate rank
egen urban_sum2 = mean(urban)
egen pedu = rowmax(medu fedu) //父母中教育较大的进行赋值
bysort educ: egen wage_max = max(wage) //每组教育程度群体中工资最大值为多少
bysort educ: egen wage_mean = mean(wage)
/*--给变量名添加标签--*/
label var age_sq "age square"
label var logwage "log wage"
/*--给变量值添加标签--*/
label define urbanlabel 1 "Urban" 0 "Rural"
label values urban urbanlabel
tab urban
tab urban, nolabel
/*--变量类型转换--*/
tostring ID, replace //把数值型变成字符型
destring ID, replace //把字符型变成数值型3.4 绘制图表
hist wage //绘制条形图
hist wage, bin(50)
hist wage, normal
scatter wage IQ
scatter wage IQ || lfit wage IQ //散点图和线图合并在一起
line wage_mean educ, xtitle(education) ytitle(wage)
graph export "output/wage_edu.png", replace //输出并保存图片3.5 回归
regress wage educ //Regress wage(y) on educ(x), OLS
regress wage educ, robust //Calculate robust standard error
predict wagehat //Get predicted value
predict uhat,r //Get residual
reg wage educ meduc age black, robust
reg wage i.educ meduc feduc age //i.group代表indicators for levels of group, 如果educ有n种取值,i.educ生成n-1个虚拟变量
3.6 相对复杂的处理语句
// 循环: forvalues, foreach
forvalues i =1/10 {
replace edu`i'=edu`i'+1
}
//把edu1-edu10这10个0-1虚拟变量转化为1-2变量
local varlist educ age black
foreach var of varlist `varlist' {
reg wage `var'
}
//foreach var of varlist 'varlist' 对var的循环,wage将与var中每一个变量进行回归
// 宏(macro)
global sum_var hours IQ educ age married //将后5个变量都包装进sum_var里3.7 储存回归结果及输出表格
/*
一般命令的结果存储在r()中, 例如sum, tabstat, ttest
回归估计的结果存储在e()中, 例如reg
*/
//输出e()结果,用esttab
eststo clear
eststo: reg wage educ
eststo: reg wage age educ
esttab using "output\reg.csv", replace
// 输出r()结果, 用estpost将r()转化成e(), 再用esttab输出
eststo clear
estpost summarize $sum_var //estpost可以把r()转换为e(),转换后便可用上面的命令处理)
esttab using "output\sum.csv", cells("mean sd min max") ///
replace4 跨表合并截面
单个表的变量并不能满足研究需求,需要进行跨表间的变量合并。这里以最常见的个人库(ID)与个人库(ID),家庭库(householdID)和个人库(ID)合并为例。
/*--个人库(ID)与个人库(ID)--*/
use "wage.dta", clear
merge 1:1 ID using "Cognition.dta", ///
keepusing(happiness) keep(1 3) nogen
/*--家庭库(householdID)和个人库(ID)--*/
use "wage.dta", clear
merge m:1 householdID using "Household_Income.dta", ///
keepusing(fincome1_per asset familysize agri finp) keep(1 3) nogen5 跨年合并面板
有时候截面数据并不能满足我们的研究需求,还需要进一步构造面板数据。这里以2015年和2018年为例构造非平衡面板。
use "data15.dta", clear
keep ID householdID urban marriage fincome familysize
gen year = 2015
save "data15.dta", replace
//对data18.dta重复上述操作并保存
/*--跨年合并非平衡面板--*/
use "data15.dta", clear
append using "data18.dta"
order ID year
xtset ID year
repeated time values within panel6 我曾遇到的问题
6.1 PSU乱码如何解决
https://zhuanlan.zhihu.com/p/46441447
6.2 CHARLS问卷中2013年和2011年数据中ID不一致
https://bbs.pinggu.org/thread-4522291-2-1.html
6.3 其他问题:城市信息、医保无法准确识别、家庭总收入、体检信息
https://www.zhihu.com/question/508229866/answer/2407378890
stata入门实操之描述性统计
基础理论
概念解释
何谓描述性统计,维基百科的定义是:“描述性统计是一种汇总统计,用于定量描述或总结信息集合的特征”。从这个定义,我们不难看出,描述性统计包含两个重要的特征,描述和总结。
通常情况下,我们把描述性统计分为两大类:离散趋势和集中趋势,两种分类常见的统计量如下:
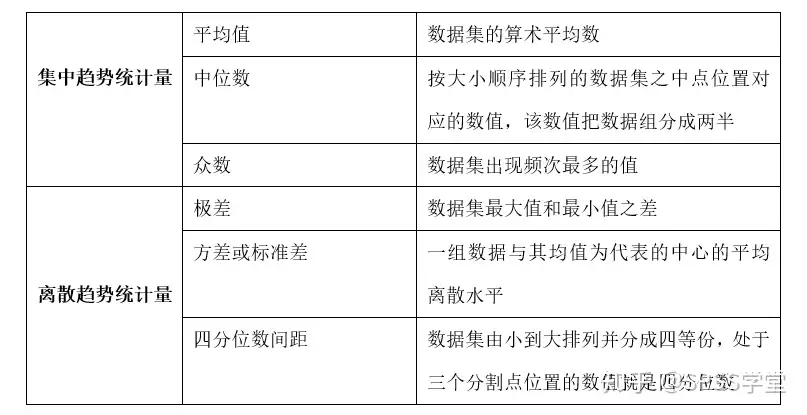
一般情况下,我们首先将收集到的大量数据归纳整理到一张表格,我们把这张表格称之为数据集,数据集一般包含很多类型的数据。通过描述性统计,我们可以根据自己的研究需要,从大量不同类型的数据中,筛选出具有代表性的数据来进行初步的研究分析。
stata软件实操
首先,导入数据集auto.dta
通过存储文件打开该数据的stata命令为:use “D:\你自己存放auto.dta文件的路径 \auto.dta”。
或者打开stata软件自带的数据集。相应的Stata命令为sysuse auto,clear
出现这样的结果表示数据导入成功。
数据导入成功以后,可先输入stata命令:describe查看数据集的大致信息
结果如下:
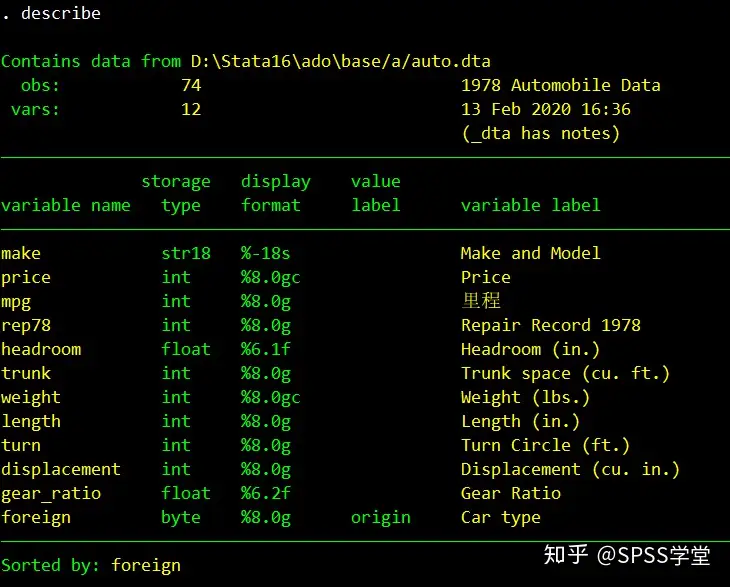
从上图我们可以发现,该数据集有74个数据(obs),12个变量(vars)。
接下来,我们根据自己的研究需要,选择具体的变量或者全部的变量进行描述性分析。
Stata的操作演示如下:
第一种方法,输入stata命令: summarize
summarize后可以跟具体变量的名称,如果不跟变量名称,则默认对全部变量进行描述性分析,两种结果如下:
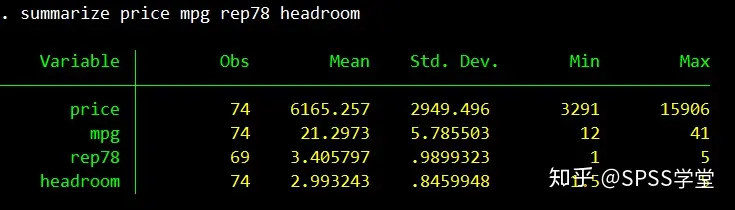
(1)输入命令:summarize,得到全部变量的描述性统计结果。
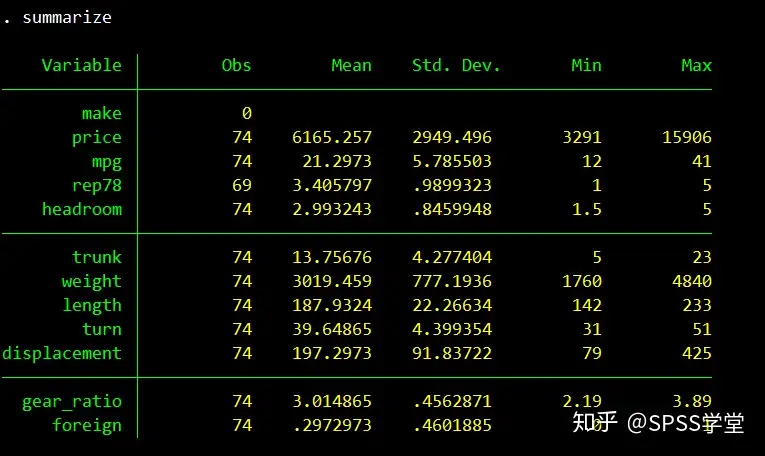
(2)输入命令:summarize price mpg rep78 headroom,得到部分变量的描述性统计结果。如下图所示。
导出结果到word
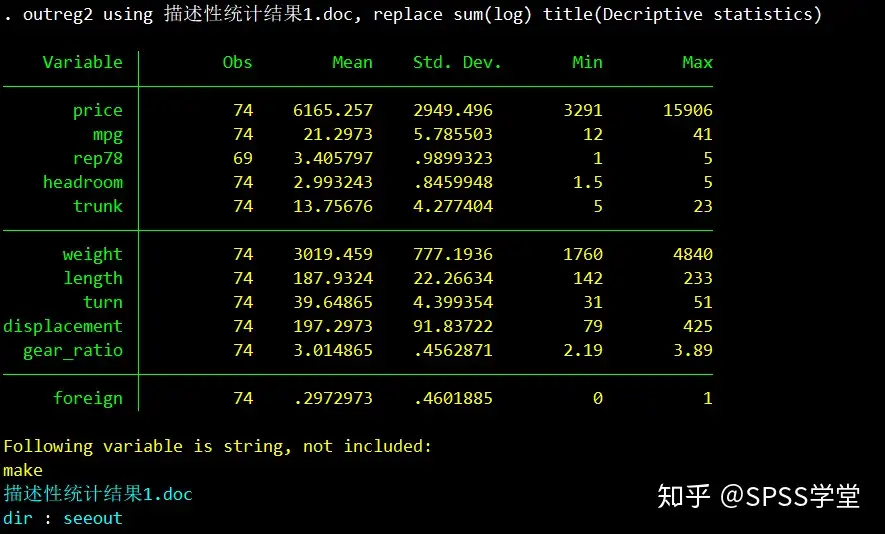
提示:如果没有outreg2的命令,需要先安装该命令,相应的安装命令为 ssc install outreg2。
导出描述性统计结果的Stata命令为:outreg2 using 描述性统计结果1.doc, replace sum(log) title(Decriptive statistics),得到下图。
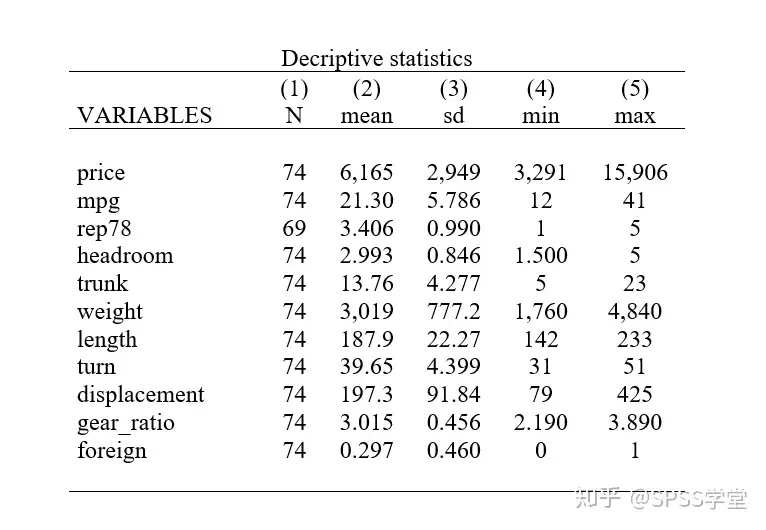
打开描述性统计结果1.doc文件,得到下图。
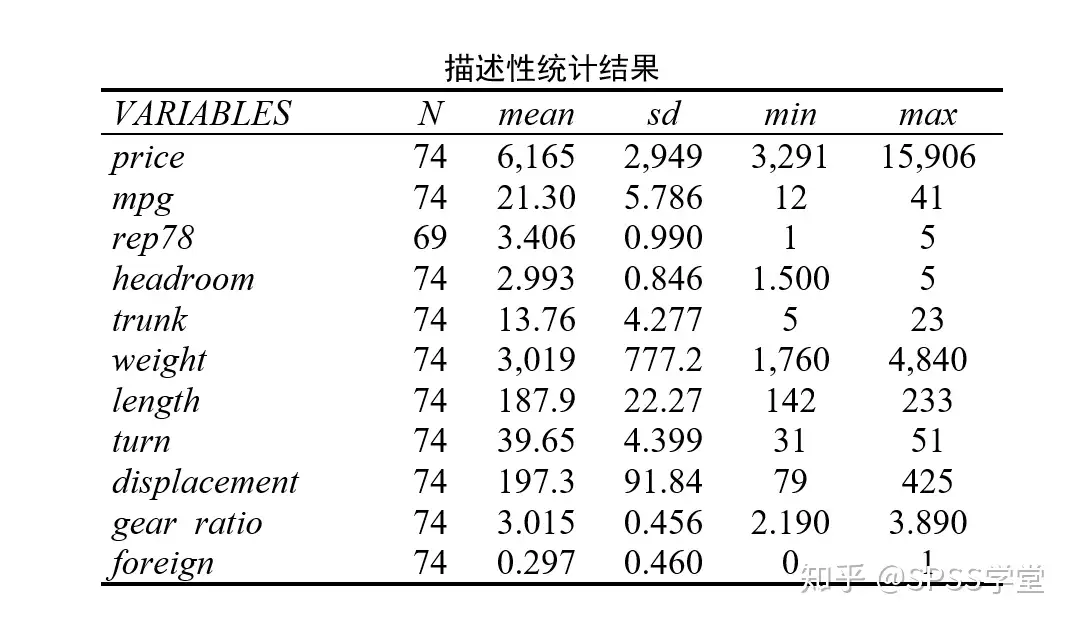
对其进行整理,使之符合论文的要求以及更美观,得到如下图
第二种方法
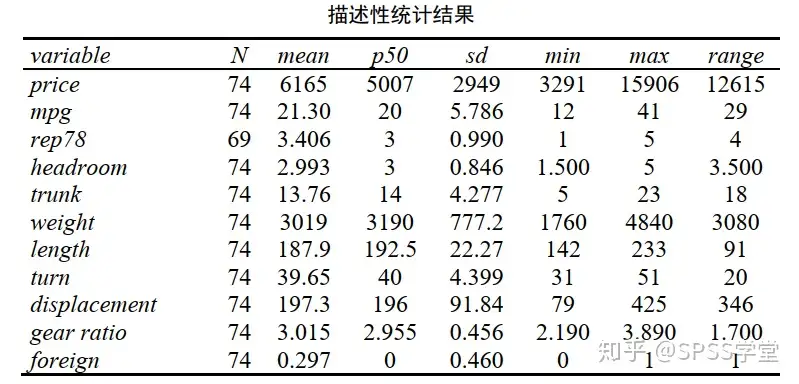
输入stata命令:tabstat price mpg rep78 headroom trunk weight length turn displacement gear_ratio foreign,s(N mean p50 sd min max) f(%12.3f) c(s)
结果如下:
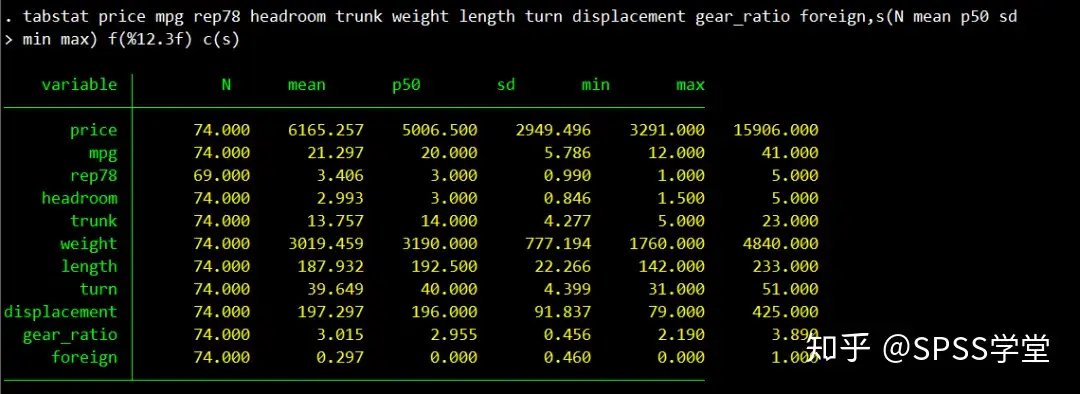
需要注意
s(N mean p50 sd min max)括号里面可以根据自己的需要增加删除相应的统计量,相应统计量的代码如下图所示:
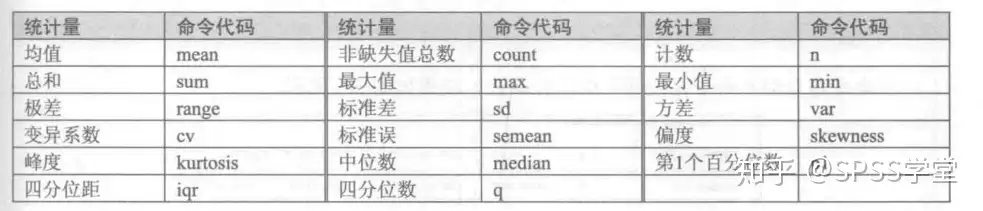
导出描述性统计结果到word
提示:如果没有logout的命令,需要先安装该命令,相应的安装命令为 ssc install logout
导入结果的命令如下:
logout,save(描述性统计结果2)word replace:tabstat price mpg rep78 headroom trunk weight length turn displacement gear_ratio foreign,s(N mean p50 sd min max range) f(%12.3f) c(s)。结果如下:
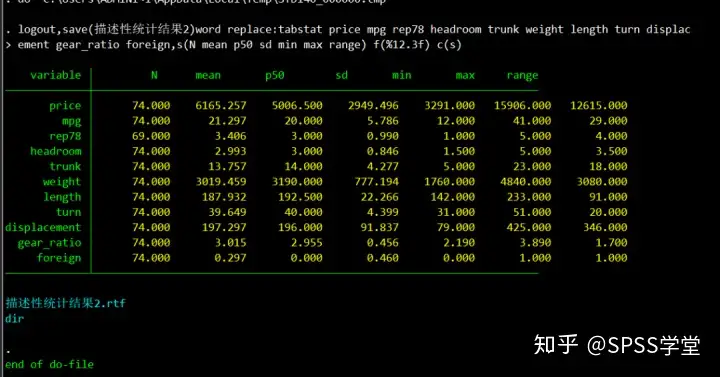
打开描述性统计结果2.rtf
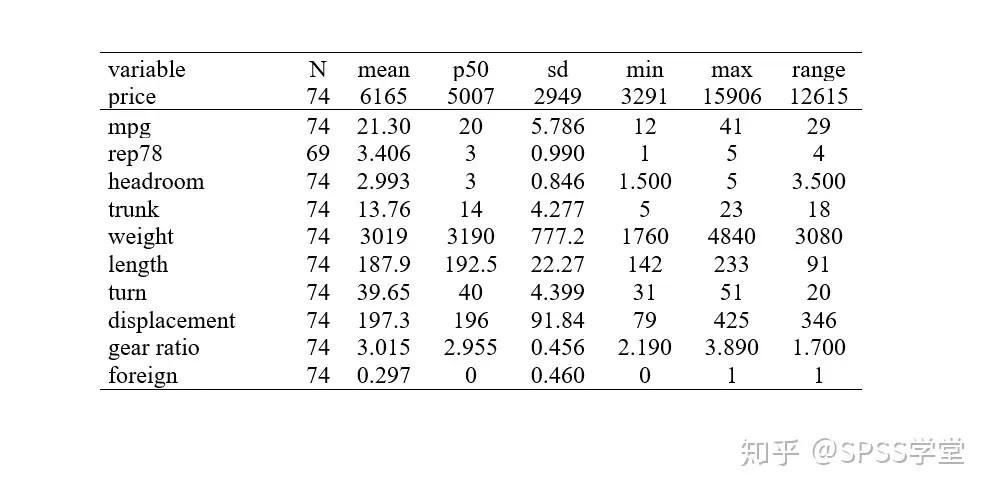
对其进行整理,使之符合论文的要求以及更美观,得到如下图:
graph
概要
本文涉及到的内容包括,在拿到一个数据集后:
- 如何使用list、describe命令,初步了解数据集;
- 如何使用codebook、summarize命令了解某一个变量x的缺失值、统计量,并使用stem、graph box、histogram命令画出茎叶图、箱式图以及柱状图;
- 如何使用twoway graphs来展示数值型变量x和y之间的关系,并画出散点图(scatter plot)、折线图(line plot)、带数据标记的直线图(connected plot)等多种图像;
- 如何使图像变得更加美观。
下面,我们通过例子来了解这些命令。本次使用的是1900-1999年美国期望寿命的数据,这是Stata 14.0自带的一个数据库。
提醒
(1) 使用Stata时,尽量不用命令框,而最好使用do file编写命令。这样可以保证操作的可重复性。
(2) 本文中,所有命令以黄色背景、粗体、蓝色字体显示。
(3) do file中命令末尾的双斜线//表示添加注释(例如,图0.1.1第6行set linesize 255后为注释),三斜线///表示换行(例如,图0.1.1从第8行到16行为一个完整的命令,其中使用///换行)。
1. 导入数据并观察
为了方便大家学习,我们在本教程中使用Stata自带的数据uslifeexp.dta,大家可以输入sysuse dir这行命令查看系统自带的数据库(图1.1.1)。若没有uslifeexp这个数据库,大家可以在http://www.stata-press.com/data/r9/uslifeexp.dta下载。

. sysuse uslifeexp
这一步的目的是导入该系统自带数据。屏幕显示的结果如下。

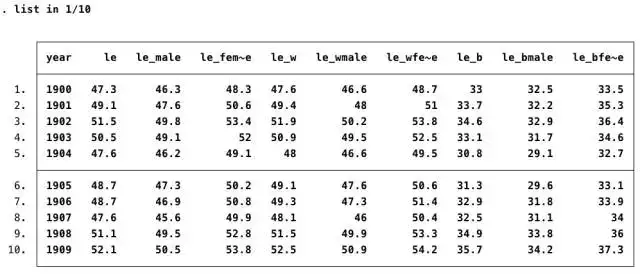
. list in 1/10
通过这个命令,我们可以查看该数据库第1到第10个数据,对数据有一个初步的了解。屏幕显示的结果如下。
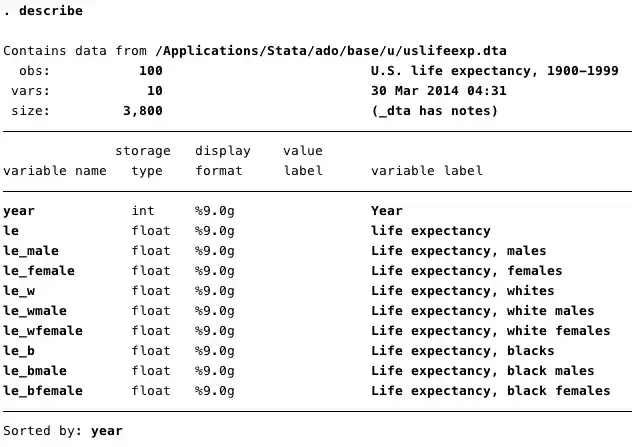
. describe
通过这个命令,我们可以查看这个数据集的简要介绍,包括了样本数量(obs:100)、变量数量(vars:10)、大小(size:3800)、以及每个标量的简要介绍。屏幕显示的结果如下。
2. 单变量探索以及作图
在这一小节中,我们一起来对某一个变量进行探索。我们会用到四个命令,分别是codebook、summarize、stem以及histogram。我们以数据集中的变量le (life expectancy)为例。这个变量是人均预期寿命。
2.1 Codebook
Codebook这个命令适合于我们初次接触一个数据集的变量。
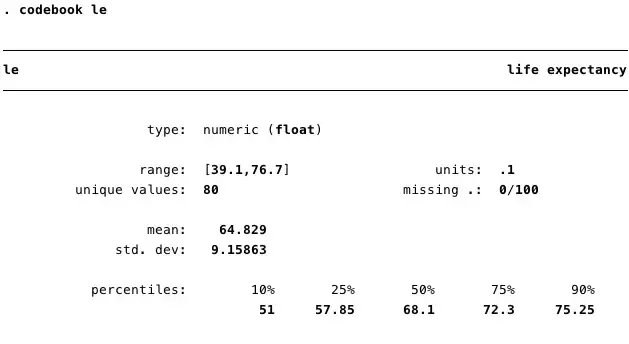
. codebook le
下图是codebook le这行命令给出的结果。我们可以看到,output给出了该变量的标签(life expectancy)、类型(numeric: float)、范围、单位、特异值、缺失值(0/100)、以及一些统计量。这样,我们对于该变量有一个初步的了解。
2.2 Summarize
Summarize这个命令可以让我们更加深入地探索变量的统计量。
. summarize le
下图是summarize le这行命令的结果,给出最常用的几个统计量。

而summarize le, detail这行命令则会给出更多的统计量。
. summarize le, detail
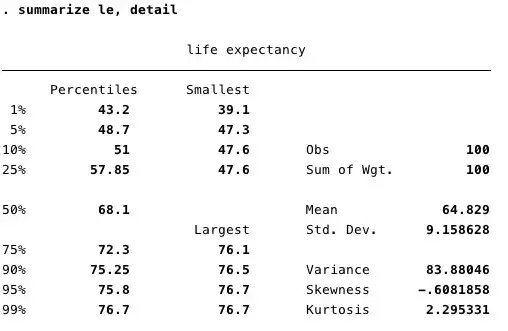
其中,smallest和largest代表了该变量最大和最小值,即预期寿命(le)的4个最高值和4个最低值。
2.3 其他图像
为了探索变量的分布,我们还可以使用茎叶图(stem plot)、箱式图(box plot)、直方图(histogram)等图像进行探索。
. stem le

. graph box le (左图)
. hist le (右图)
** hist是histogram的缩写。在Stata中,一些命令有缩写形式,如summarize可以缩写为sum。
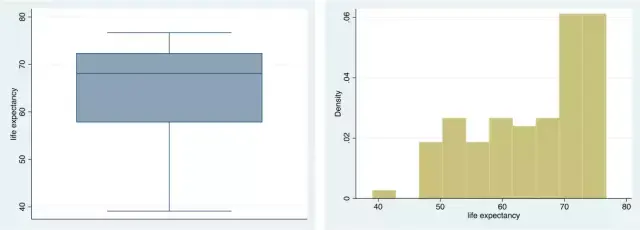
由于篇幅有限,对于这些图像,我们在此不做赘述。但是我们应该记住,茎叶图的茎宽、保留位数;直方图的组距、颜色、y轴是频率还是频数等都可以进行自定义,直到画出满意的图像。感兴趣的读者可以在命令行中输入help stem、help graph box、help histogram获取help文件。如还有不清楚的地方,可以联系小咖获取帮助。
3. 双变量作图
在这一小节中,我们对于双变量进行绘图。我们继续研究预期寿命(le)随年份(year)变化的规律。不同的是,我们使用le_male与le_female绘制2个y变量和x的图,使用le_wmale、le_wfemale、le_bmale、le_bfemale绘制4个y变量和x的关系。
. twoway plot [if] [in] [, twoway_options]
twoway的命令是twoway plot 变量 [if] [in] [, twoway_options],我们可以自己定义的主要是:
- plot:选择图像的种类,这里的plot可以改成scatter, plot, connected, area, bar等,我们可以绘制出相应的图。
- 变量:这里可以写一个或多个y变量,一个x变量。最后一个是x变量,之前的为y变量。
- [if] [in] [, twoway_options]等中括号内的命令是可选命令,如果不写,则表示默认值。
- if:定义所取某一个自变量的范围,例如if le > 40,即只画le>40的图
- in:定义所取观测值的范围,例如in 10/20,即只画第10到20个观测值的图
- twoway_options:可以定义图像的“美观”部分,例如坐标轴范围、标题、注释、标签等等。
3.1 一个y变量(预期寿命(le)随年份(year)变化的关系)
twoway plot y x,其中plot可以换为某种特定的图像,如scatter。
– 散点图
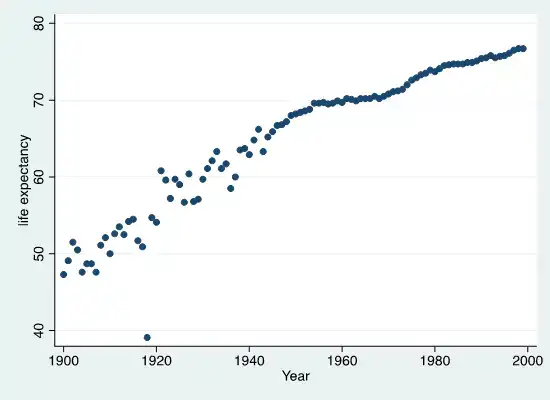
下图Stata代码:
. twoway scatter le year
– 折线图
. twoway line le year
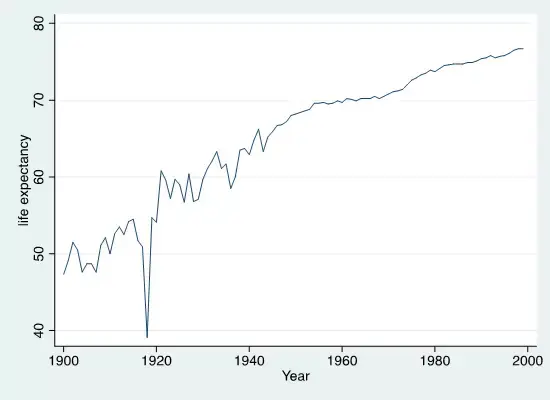
同理,我们还可以做出更多种的图。
. twoway connected le year (左上,带数据标记的折线图)
. twoway dropline le year (右上,垂直线图)
. twoway spike le year (左下,脉冲图)
. twoway lowess le year (右下,lowess图)
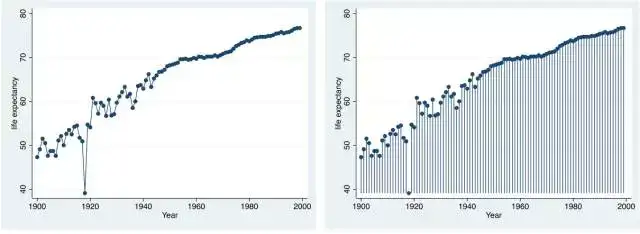
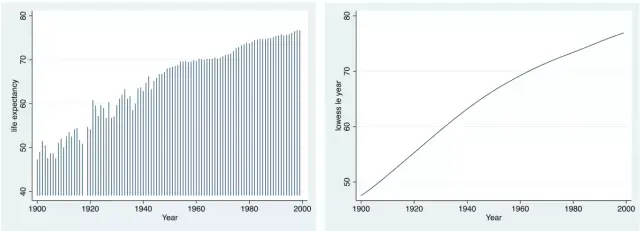
大家可以输入help graph_twoway,查看Stata都可以做出什么样的图。
3.2 多个y 变量
命令形式:graph twoway plot yvar1 yvar2 yvar3 … xvar
plot表示我们要画的是某种图,之后是变量的名字。
Stata会默认最后一个变量是x变量,plot和x变量之间则均为y变量。
下图Stata代码:graph twoway scatter le_male le_female year
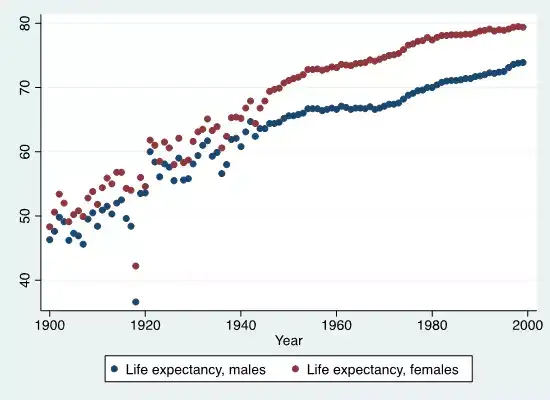
下图Stata代码:twoway line le_male le_female year
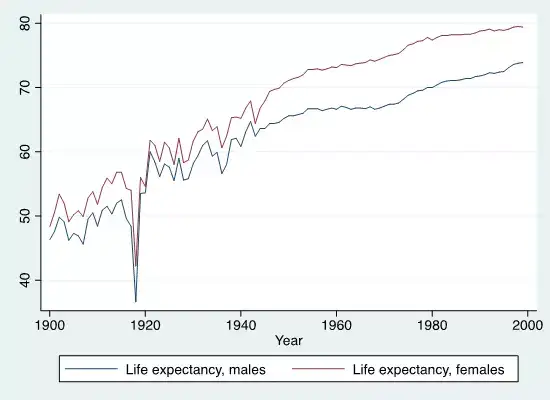
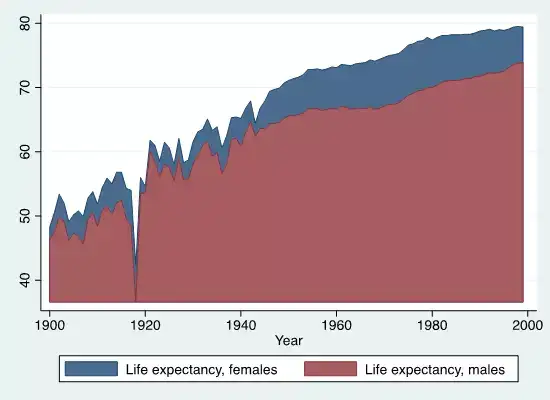
下图Stata代码:twoway area le_female le_male year
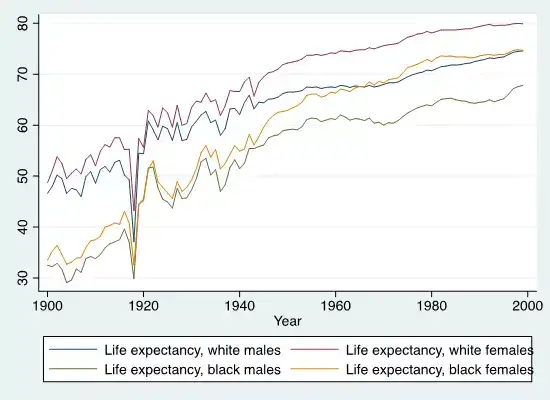
下图Stata代码:twoway line le_wmale le_wfemale le_bmale le_bfemale year
注意:
在Stata中,上述命令graph twoway plot yvar1 yvar2 yvar3 xvar和下列命令等价:
– graph twoway (plot yvar1 xvar) (plot yvar2 xvar) (plot yvar3 xvar)
– graph twoway plot yvar1 xvar || plot yvar2 xvar || plot yvar3 xvar
. twoway scatter le_m le_f year
. twoway (scatter le_m year) (scatter le_f year)
. twoway scatter le_m year || scatter le_f year
(以上3个命令等价,画出下图)
因此,我们完全可以在同一张图上画出不同y变量。

(以上1-4行为第一个命令,6-9行为第二个命令,两个命令等价,画出下图)
也可以将yvar1的两种不同的曲线画在同一幅图上。
. twoway (scatter le year) (lfit le year)
. twoway scatter le year || lfit le year
(以上2个命令等价,画出下图)
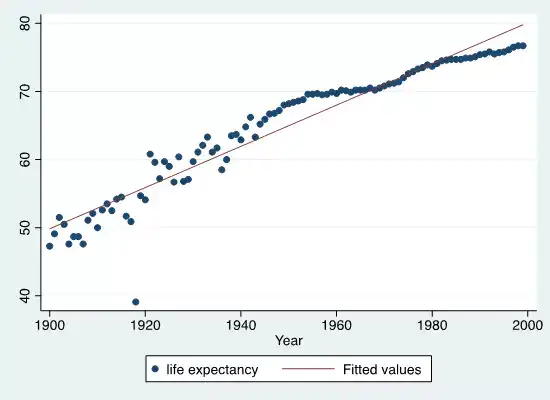
1 twoway – scatter + lfit 散点图+拟合线
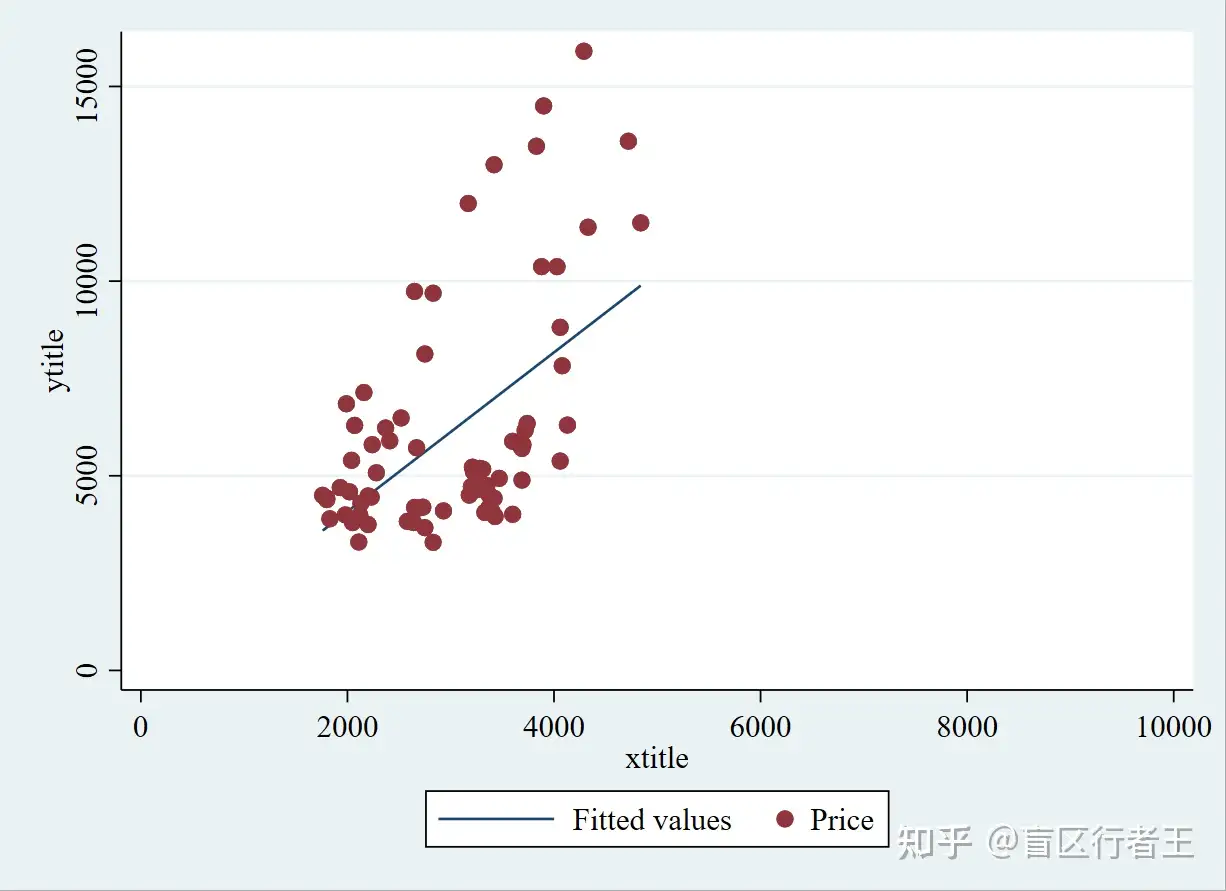
twoway(lfit price weight) (scatter price weight), xtitle(xtitle) ytitle(ytitle) ///
xscale(range(1 10000)) xlabel(#5) ylabel(#5)
twoway(lfit y x if m<2) (lfit y x if m>3),xtitle(xtitle) ytitle(ytitle) ///
xscale(range(1 5)) xlabel(#10) ylabel(#10)
// m为调节变量,两个子样本可以不连续,图的结果可以用来判断斜率是否一致。最终判断调节变量是否有用
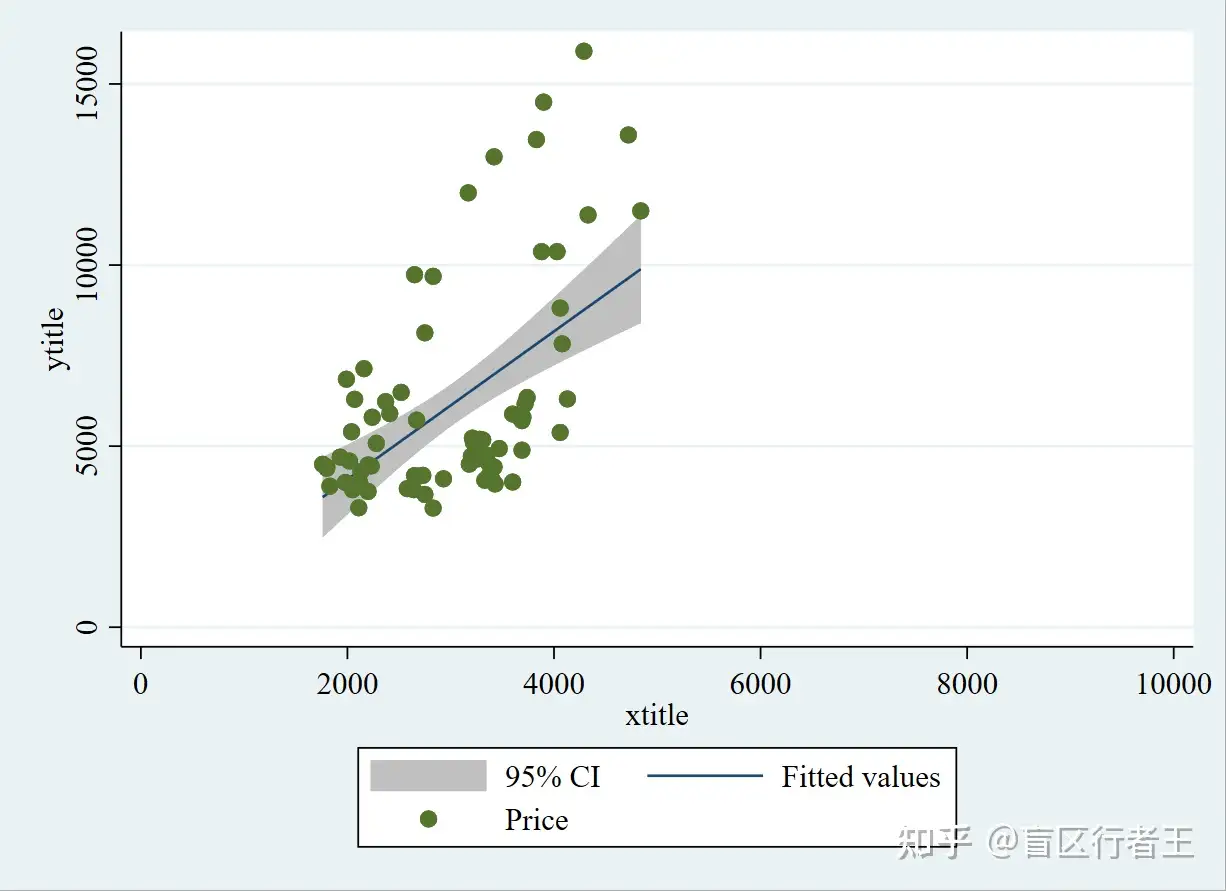
如果把lfit换成lfitci,可在线形拟合图加上CI置信区间。
2. qreg & graph 分位数回归和画图
. set seed 1898
. bsqreg price rep78, reps(1000) q(0.5)
. grqreg, ci ols olsci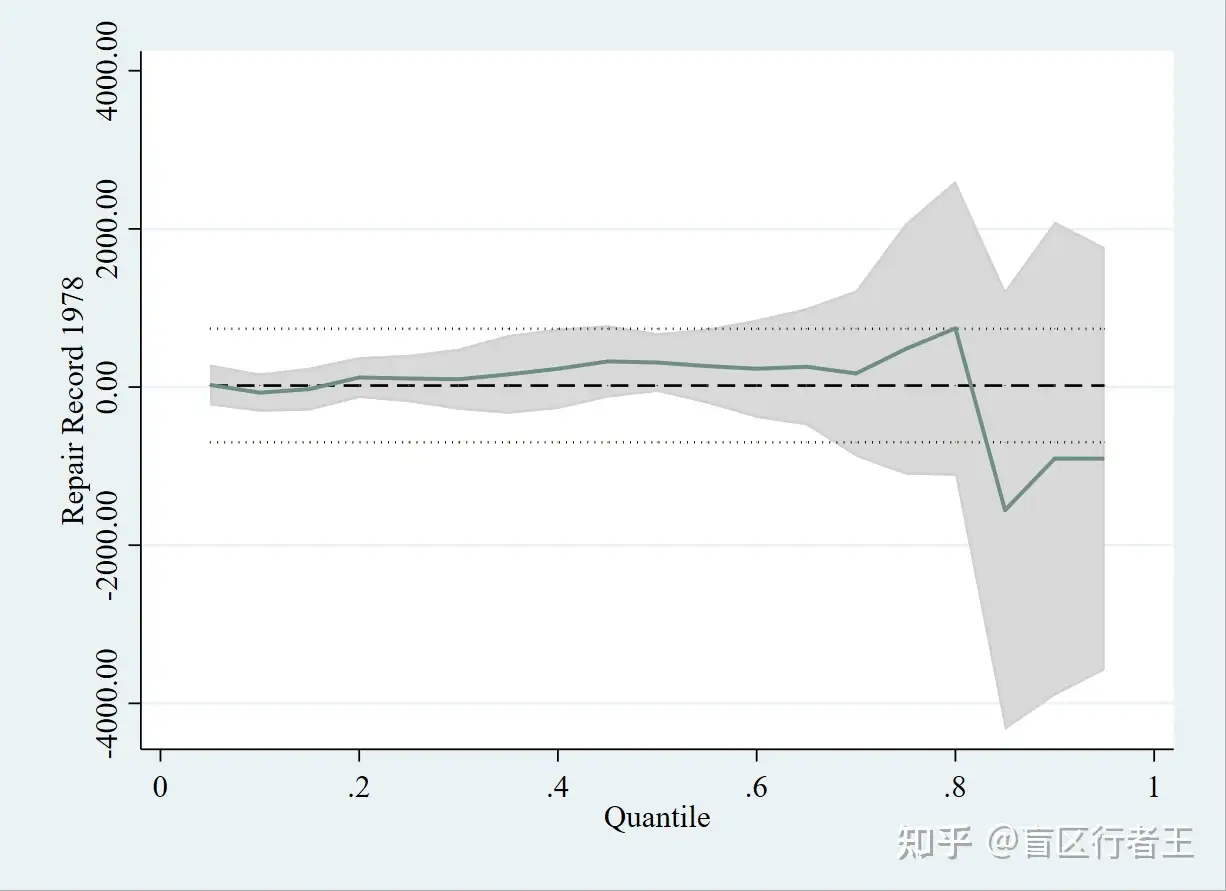
3. Scatter Plot 散点图
Y-股票收盘价,X-日期
. sysuse sp500.dta, clear
. scatter close date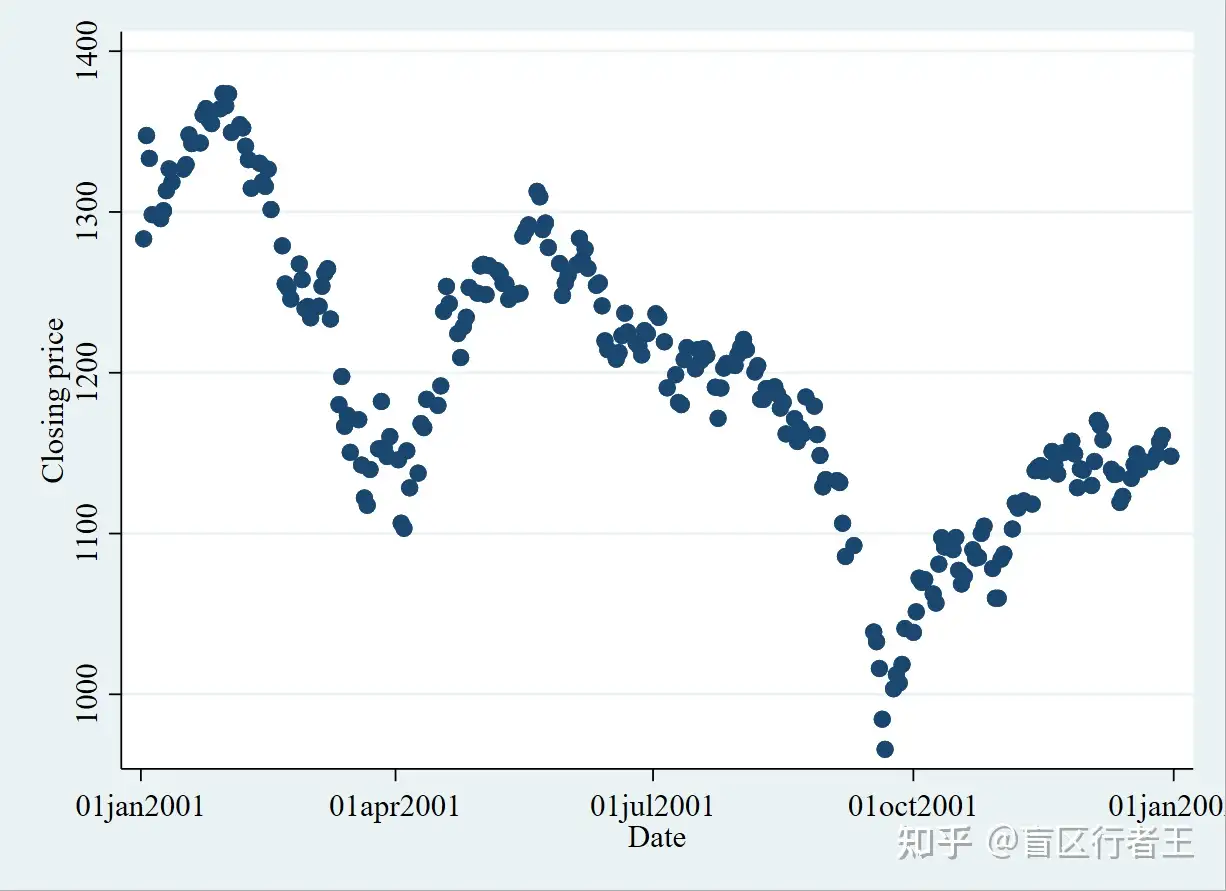
. sysuse auto.dta, clear
. scatter price length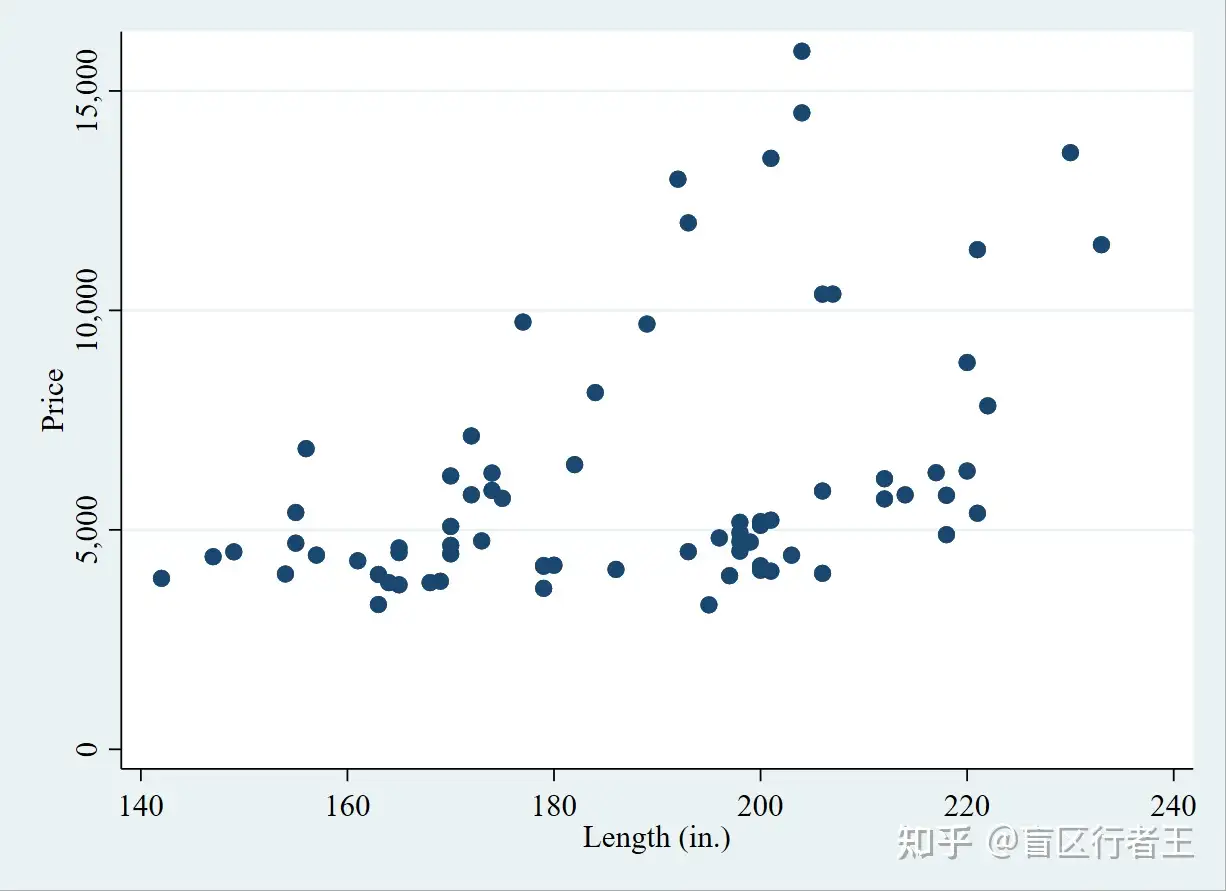
4. Line Plot 线形图
. sysuse sp500.dta, clear
. line close date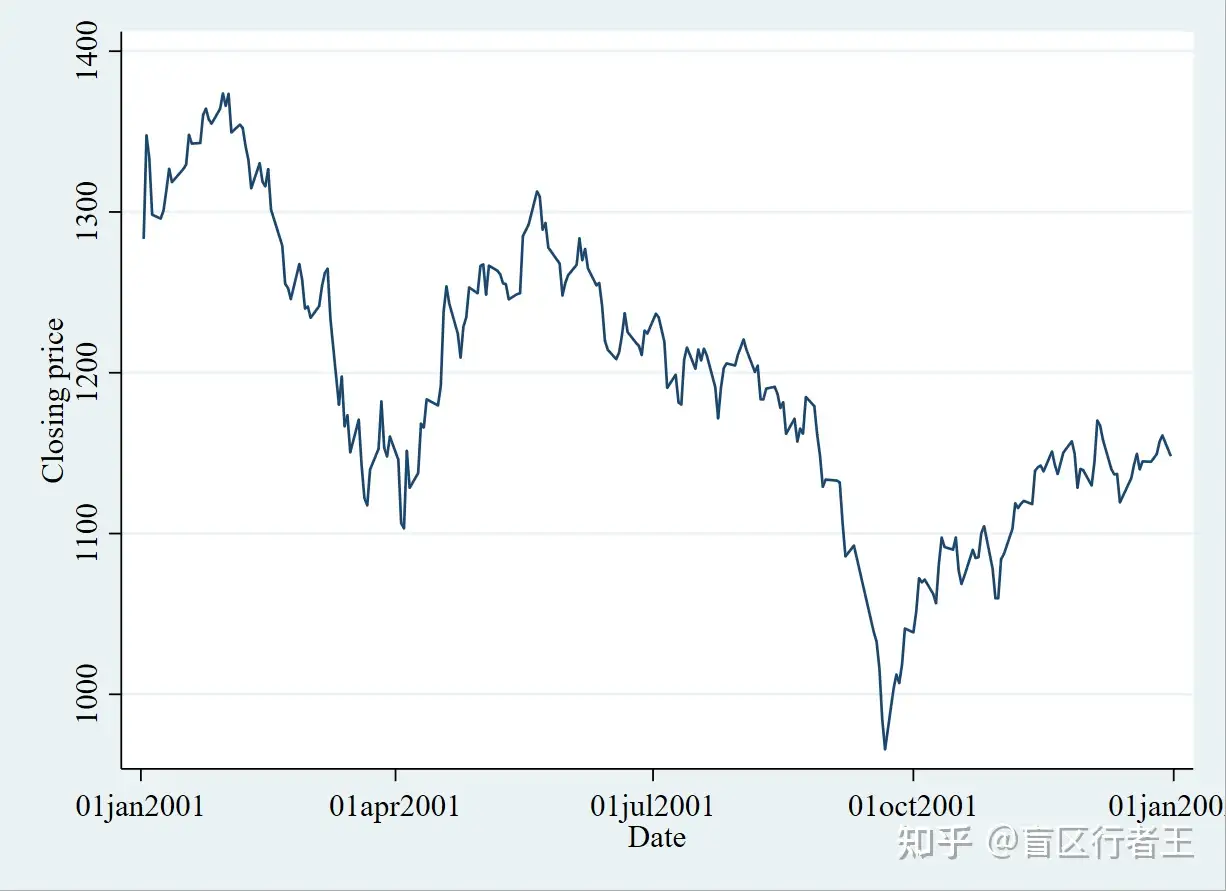
** connected line plot
. graph twoway connected close date //这里不能用命令缩写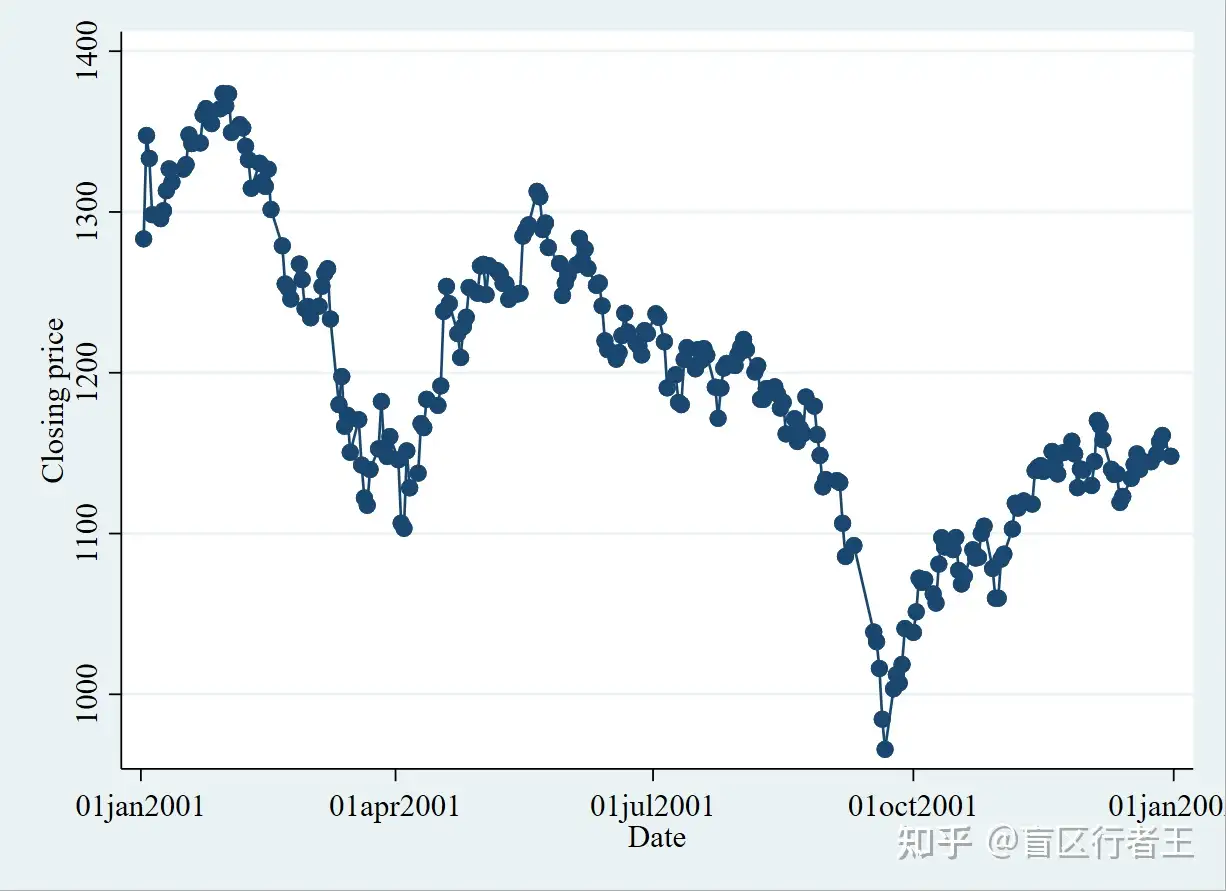
使用immediate scatterplot 加上数据标签。
graph twoway (scatter close date) ///
(scatteri 965.8 15239 (3) "最低价, 9月21日, 965.8" ///
1373.7 15005 (3) "最高价, 1月30日, 1373.7", msymbol(i) )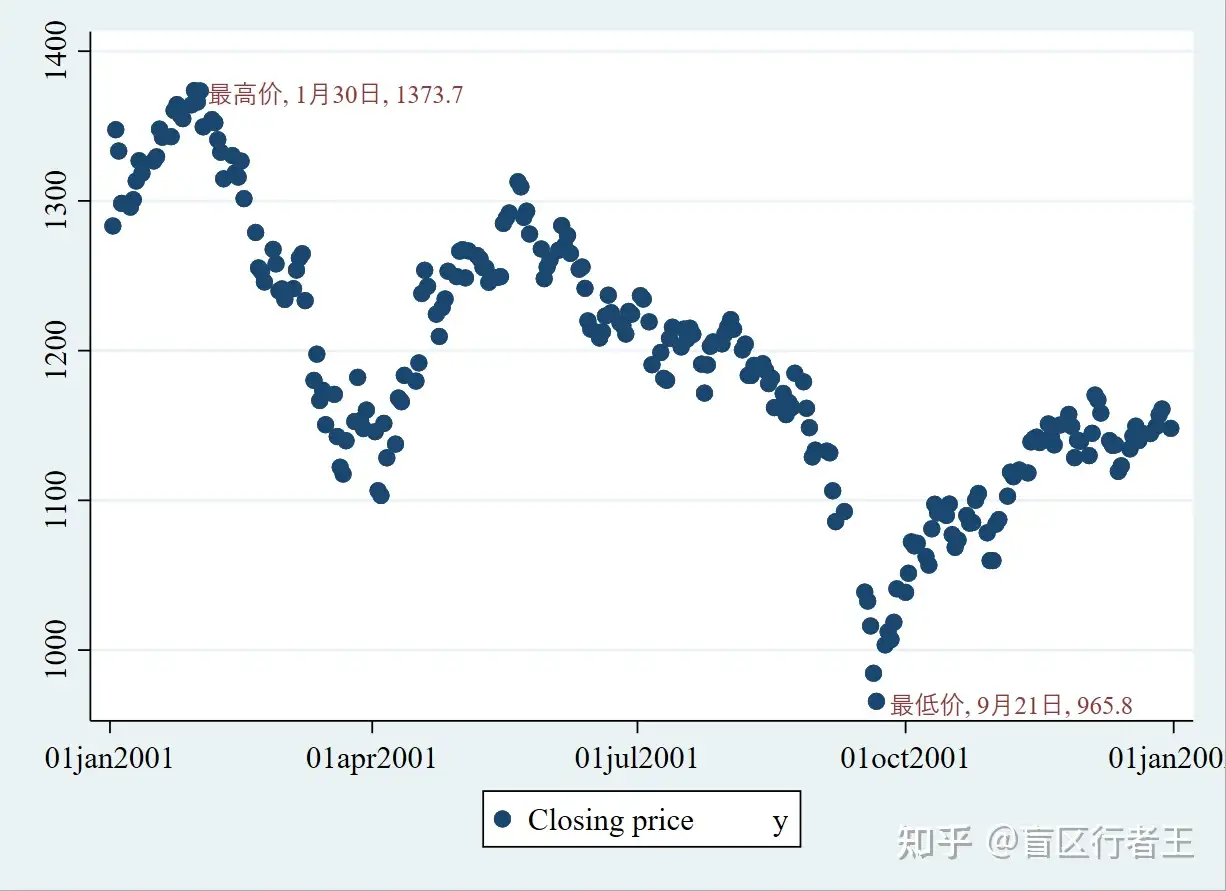
5. Area graph 面积图
. graph twoway area close date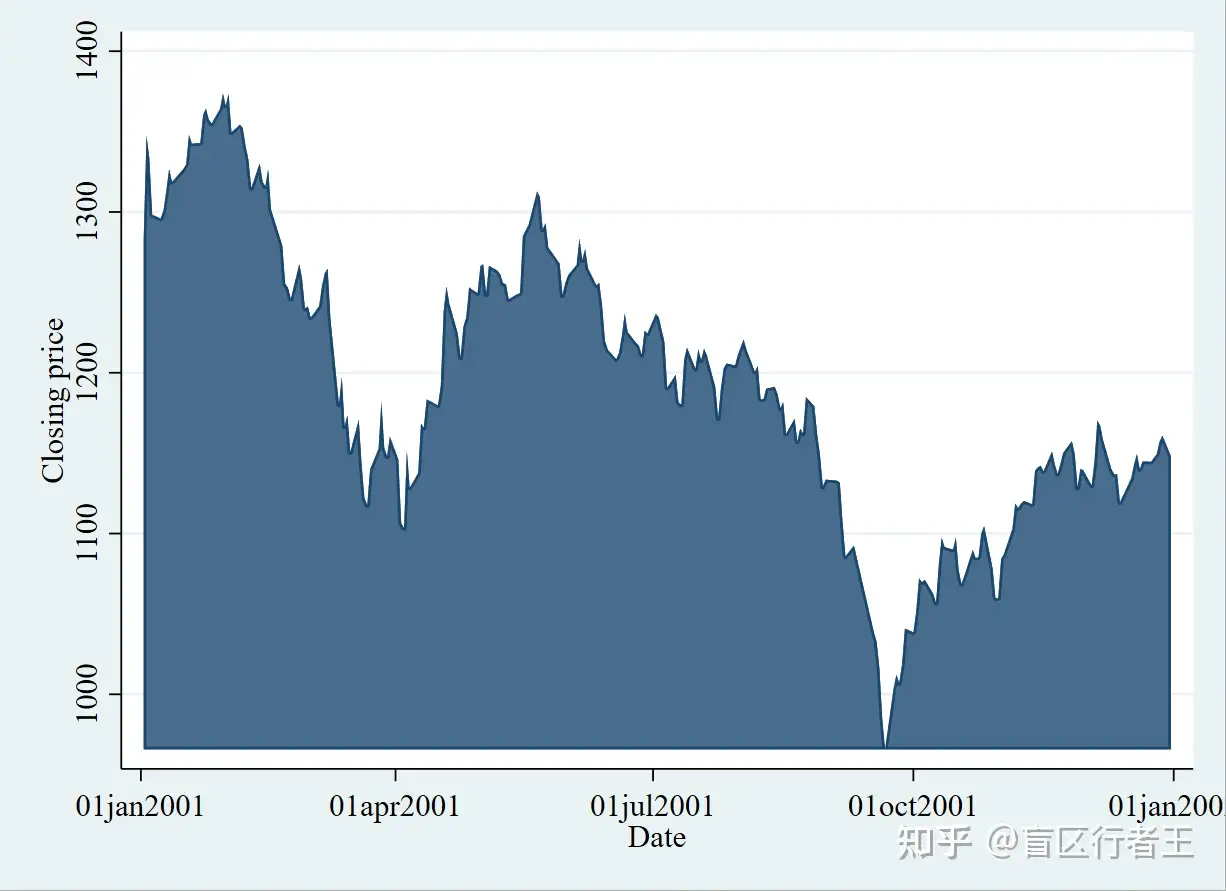
6. Bar plot 条形图
. graph twoway bar close date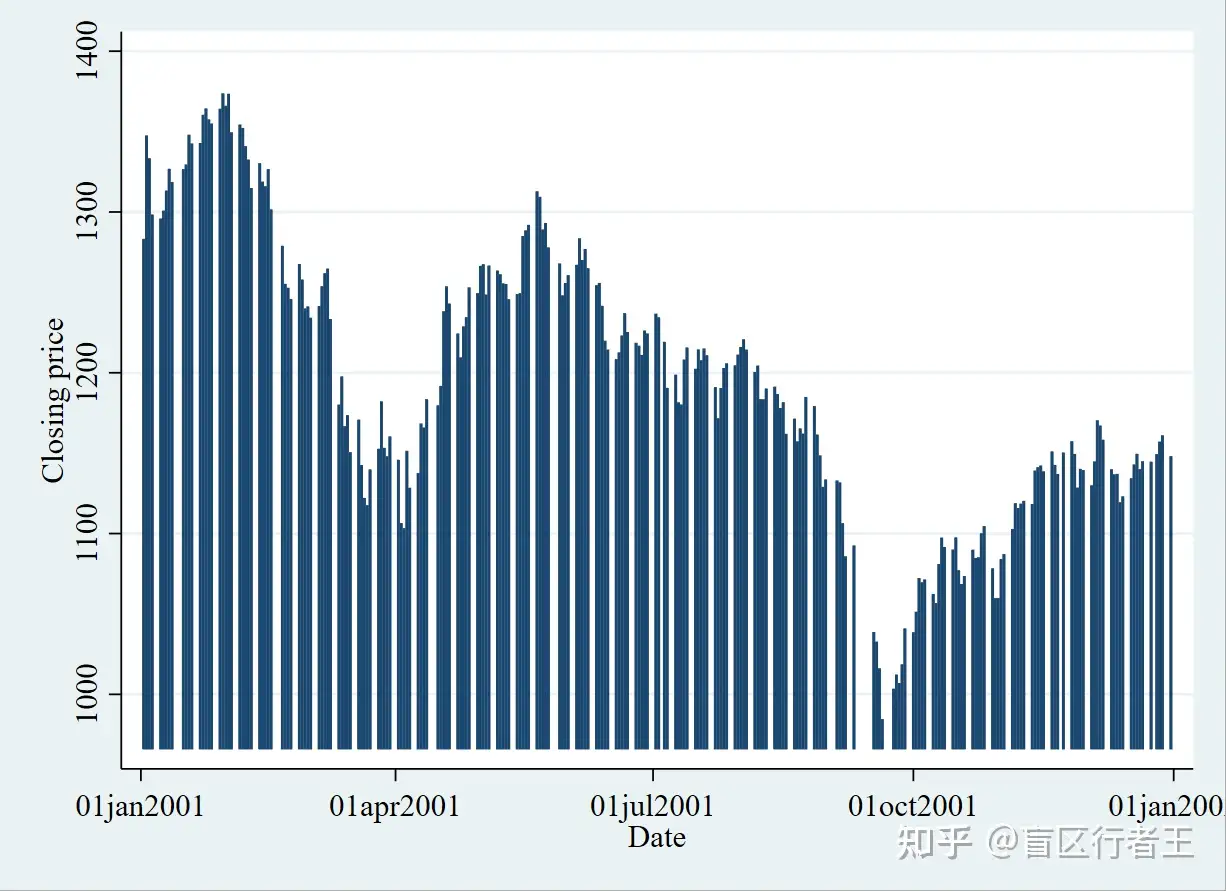
7. Spike plot 刺形图
. graph twoway spike close date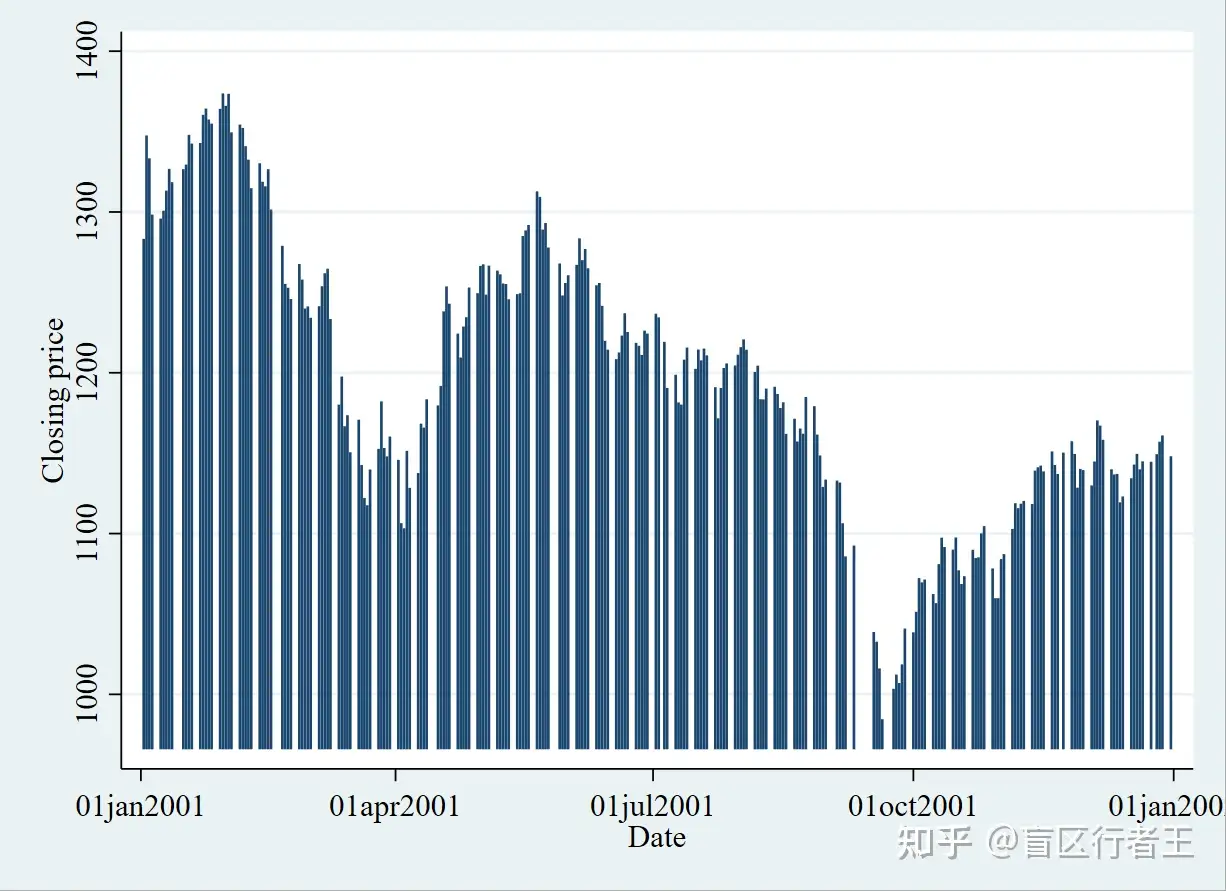
8. Range plot with area shading 范围阴影图
. graph twoway rarea high low date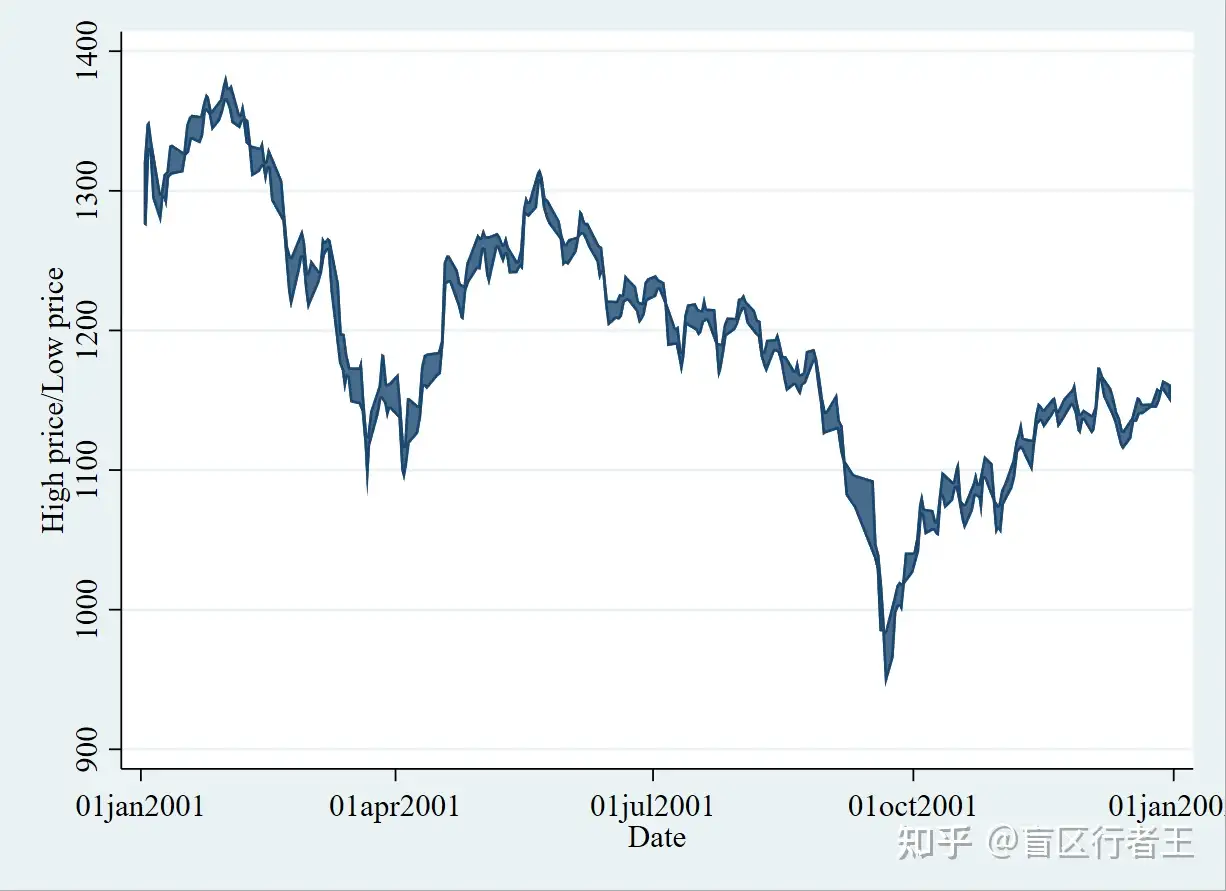
类似地,可以把阴影
- 换成条形:graph twoway rbar high low date;
- 换成刺形:graph twoway rspike high low date;
- 换成线形:graph twoway rline high low date;
- 换成带帽的刺形:graph twoway rcap high low date;
- 换成带帽带符号的刺形:graph twoway rcapsym high low date;
- 换成线形+marker:graph twoway rconnected high low date。
9. Spline line plot 平滑线形图
. sysuse auto, clear
. graph twoway mspline price weight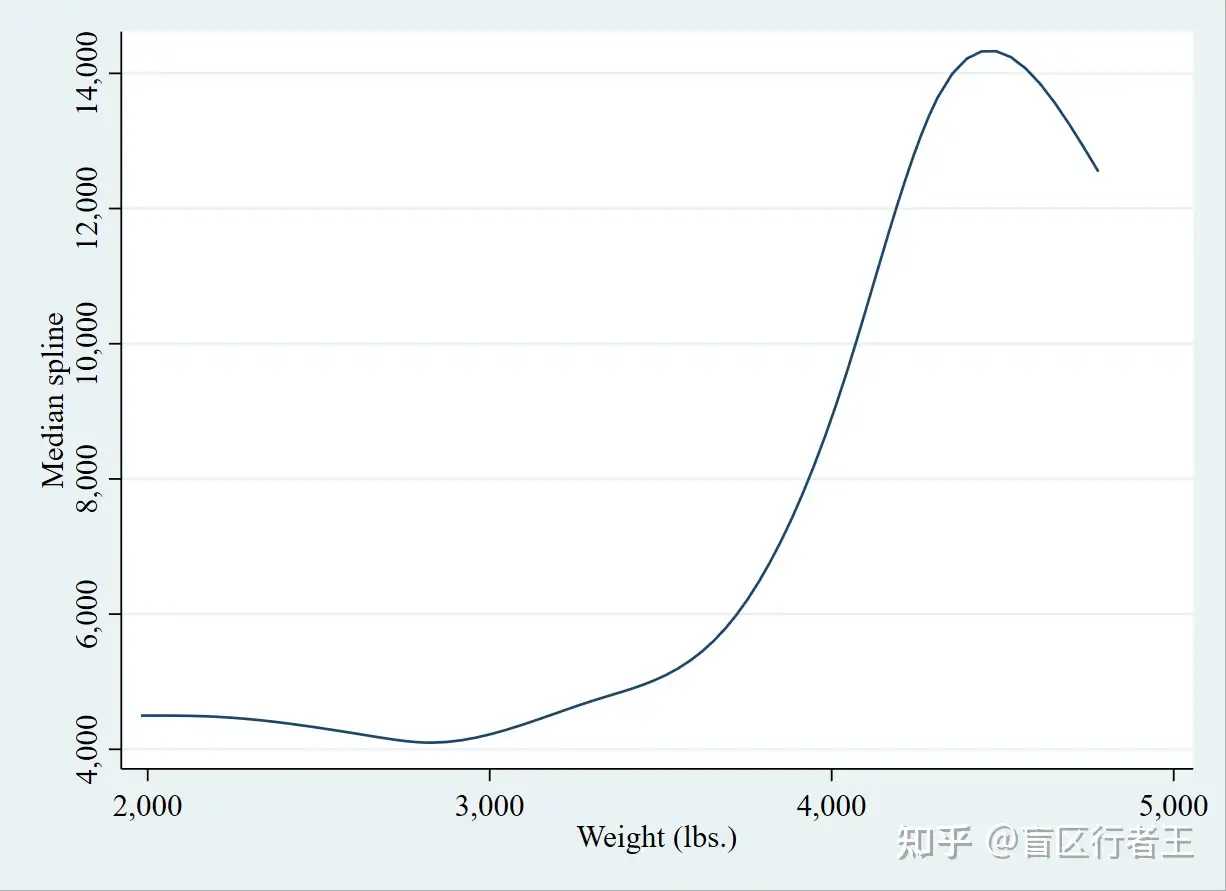
10. LOWESS line plot LOWESS线形图
. graph twoway lowess price weight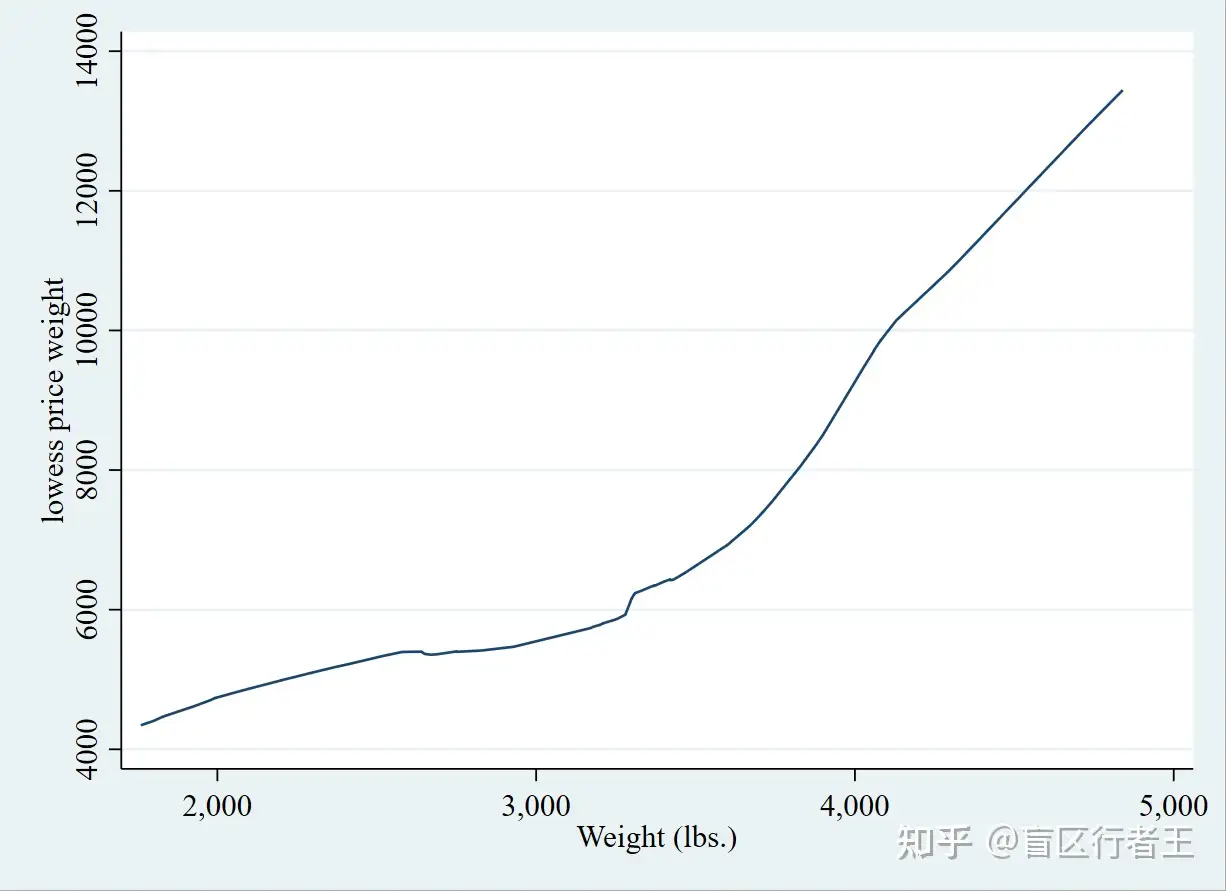
(持续更新中)