面板数据:混合回归、随机效应、固定效应和双固定效应的介绍和选择
https://zhuanlan.zhihu.com/p/433936964 简单易懂的说明
1. 数据类型
在了解什么是面板回归之前,需要知道什么叫面板数据,而这则需要从数据类型说起。我们常用的数据,一般分为三种:时间序列数据、截面数据和面板数据。其区别主要在于用时间还是个体划分样本,具体来说:
- 时序数据(Time Series):同一个体(中国)不同时间(近30年)的状态构成的数据集,如
中国近30年的GDP水平 - 截面数据(Cross Sectional):不同个体(各省)同一时间(2021年)的状态构成的数据集,如
中国各省2021年的GDP水平 - 面板数据(Panel):不同个体(各省)不同时间(近30年)的状态构成的数据集,如
中国各省近30年的GDP水平
需要说明的是:这里默认的时间分割都是以年为单位,即1年看做1个时间点;对于时间以其它如月份作为单位划分的情况(此时1年会有12个月也就是12个时间点),可以认为各省(不同个体)在2021年(不同时间)的状态也属于面板数据。
在以往的研究中,在省级或地级市层面的研究通常使用截面数据(我在前边的介绍中主要也是以截面数据为主),而对国家整体情况的研究多用时间序列数据(这些研究往往伴随着高端、复杂的计量模型)。而现在主流的研究,都还是尽可能的在使用面板数据,并且控制时间和个体的双固定效应,因此,这也属于一种常见并且基本的计量方法。
2. 概念解释
在最开始接触面板数据的回归模型的时候,我们会接触到各种各样以前没见过的“词汇”。最常出现的应该是随机效应和固定效应;有的时候我们时不时还会看到双固定效应。在面板数据回归之前,我们首先需要知道这些词说的到底是什么样一个意思,然后才是知道应该如何进行操作才能得到我们想要的结果。
2.1 混合OLS
不知道大家是怎么想的,反正我最开始接触面板数据的时候,没有想太多,给我的感觉是:不就是多了很多个样本点吗?还不是进行OLS回归,和其他的有啥区别吗?这是一个很朴素的想法,以至于在很长一段时间内,我都是这样用的,后来我正式学习计量经济学过后才明白,原来我这样的操作专业的叫法叫做混合OLS回归。因此,我们可以认为:
混合OLS:将样本中的所有数据一视同仁,进行OLS回归。
此时,面板数据和截面(时序)数据唯一的区别在于其有更大的样本量
2.2 固定和随机效应
如果要简单的说固定效应和随机效应模型,可以先看看这个方程:
Y_{it}=\alpha+\beta x_{it}+ \gamma_{i} + (\varepsilon_{it}) \\ Y_{it}=\alpha +\beta x_{it}+ (\gamma+\varepsilon_{it})
其中, i 表示不同的个体, t 表示不同的时期, \alpha 和 \beta 为常规的截距和斜率项。第一个公式为固定效应模型,第二个为随机效应模型。仔细观察可以发现,固定效应中的遗漏的个体特征变量( \gamma_{i} )是一个随个体( i )改变但不随时间( t )改变的变量,算入解释变量中;而随机效应中的遗漏的个体变量( \gamma )是一个既不随个体( i )又不随时间( t )改变的变量,算入随机误差项中。
如果感觉抽象,可以根据一个实际例子进行理解:现在我们想探究企业规模和企业产值之间的关系 其中: Y_{it} 为第 i 个企业第 t 年的产值, x_{it} 为第 i 个企业第 t 年的规模, \varepsilon_{it} 则为随机误差项。而 \gamma 表示企业的某些个体特征(比如说企业类型,管理者特质,享受政策等…),但是不同之处在于固定效应中认为这些个体特征为与个体有关,且不随时间改变,记为 \gamma_{i} ;但是随机效应中则认为,这些特征属于随机误差项,和个体以及时间都无关,记为 \gamma 。
所以说,固定效应模型和随机效应模型的差别在于:遗漏的个体特征变量,究竟是算作解释变量,还是算作随机误差项?其中固定效应模型认为个体特征变量属于解释变量,随机效应模型则将个体特征变量考虑到随机误差项中。也正是如此,固定效应模型中的解释变量可以与个体特征变量相关,但是随机效应中不能。
这是因为,解释变量不能与随机误差项相关,但是在一定程度上可以与其他的解释变量相关。也就是说,随机效应需要有更强的假设条件。
如果大家不是很清楚其中的道道的话,其实也不影响我们的实际操作,因为在现在学界的经济学实证论文,多半都遵守这样的一个情况:除非不能使用,其他全用固定效应模型,换句话说,如果是做论文我们就无脑的使用固定效应模型就对了。
3. 模型选择
对于面板数据,可以使用混合OLS(POLS)、随机效应(RE)和固定效应(RE)三种模型,如果是写论文,一般直接无脑使用固定或双固定模型。但是如果是写大作业,或是老师要求检验,才需要对混合OLS、随机效应和固定效应的选择进行检验。这里我们使用stata官方的nlswork数据进行实例演示:
clear all // 清楚所有内存
webuse nlswork // 导入官方数据集 -- 需要联网,时间可能有点久
xtset idcode year // 定义idcode为个体变量 year为时间变量使用这个数据,我们研究工资水平(ln_w)和工作经验(ttl_exp)之间的关系,变量列表定义如下:
global Y ln_w // 被解释变量
global X age // 解释变量
global X_CON grade tenure not_smsa south // 控制变量如果忘记了这些操作及意义,可以看看我关于stata的基础介绍。
3.0 固定效应如何固定?
固定效应模型,之所以叫做“固定”,是因为它可以控制住遗漏的个体特征变量。而控制的方法,其实就是减去个体的组内均值,或是增加个体虚拟变量(具体操作可见当时写的关于stata基础操作的文章)两种方式。其实也很好理解,既然个体特征是与个体( i )相关,且不随时间( t )改变的,那么可以通过一定的手段处理掉个体特征( \gamma_{i} ),比如说:
- 进行差分处理: Y_{it} – Y_{it-1} = (\alpha + \beta x_{it} + \gamma_{i} + \varepsilon_{it}) – (\alpha + \beta x_{it-1} + \gamma_{i} + \varepsilon_{it-1}) = \beta(x_{it} – x_{it-1}) + (\varepsilon_{it} – \varepsilon_{it})
- 进行去心处理: Y_{it} – \overline{Y}_{it} = (\alpha + \beta x_{it} + \gamma_{i} + \varepsilon_{it}) – (\alpha + \beta \overline{x}_{it} + \gamma_{i} + \overline\varepsilon_{it}) = \beta(x_{it} – \overline{x}_{it}) + \varepsilon_{it}
- 设置虚拟变量: Y_{it}=\alpha+\beta x_{it}+ \gamma_{i} + \varepsilon_{it},其中\gamma_{i} 为个体虚拟变量,在样本为个体 i 时, \gamma_{i} = 1 ,其余情况 \gamma_{i} = 0 。
我们可以发现,使用三种不同的方法,都可以得到同样的回归系数 \beta ,可以利用数据进行验证。
keep if mod(idcode,50) == 0 // 只保存编号能被50整除的个体
* ↑↑ 个体太多设置为虚拟变量会导致运行时间过长(此处仅为演示,正常情况不用加这句)
reg $Y $X $X_CON i.idcode // 使用idcode进行回归 -- 个体太多的时归会很慢
est store reg_dum
areg $Y $X $X_CON, absorb(idcode) // 对idcode进行去心
est store reg_abs
xtreg $Y $X $X_CON, fe // 固定效应模型
est store reg_fe
local results "reg_dum reg_abs reg_fe" // 汇总结果
// 若报错:command esttab is unrecognized --> 说明缺少外部命令
// 则运行:ssc install estout
esttab `results', mtitle(`results') replace ///
nogap compress b(%6.3f) s(N r2_a) se ///
star(* 0.1 ** 0.05 *** 0.01) ///
addnotes("*** 1% ** 5% * 10%")运行程序后我们可以的得到这样的结果:
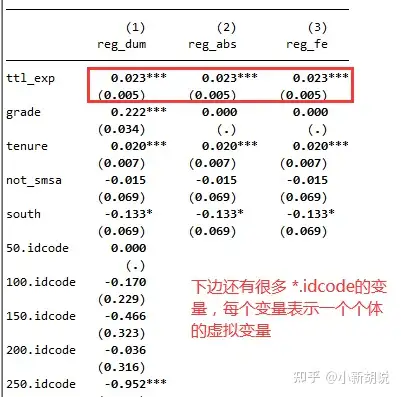
其中第(1)列为构建虚拟变量回归的结果,第(2)列则是对idcode进行了组内去心处理,第(3)列是面板固定效应的回归结果。若我们只关注核心解释变量(ttl_exp),不难发现其系数(0.023)和标准差(0.005)其实都是相同的,说明了这三种方式,其实从结果上并没有太大的区别。
但是如果细心的话,可以发现年级变量(grade)在第(2)和(3)中显示为空,这是因为。这也是一个与个体相关,但和时间无关的变量(至少在所选取的时间阶段内不发生变化),因此在组内去心的时候成为了常数0,自然没有回归系数和标准差一说。
如果前边看得不是很明白的,只需要记住:当我们需要固定某个变量(可能是个体、时间、行业、地区..等离散的变量)的时候,可以通过两种方法实现,
1. 虚拟变量法:reg $Y $X $X_CON i.变量
2. 组内去心法:areg $Y $X $X_CON, absorb(变量)
3.1 混合OLS还是变系数模型
首先我们要判断到底使用混合OLS回归还是变系数模型(随机和固定效应模型都属于变系数模型),
reg $Y $X $X_CON // 混合OLS
xtreg $Y $X $X_CON, re // 随机效应
xttest0 // B-P检验 P < 0.05 则选择变截距运行完之后,可以得到这样的结果:
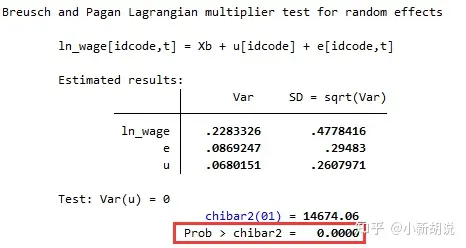
在回归的结果中,我们重点关注回归的P值(Prob > chibar2),由于此处的原假设是Var(u) = 0(也就是选择POLS),当Prob > chibar2小于0.05的时候,可以Var(u)不为0,认为选择变截距模型。
3.2 随机效应还是固定效应
在确定使用变系数模型之后,我们还需要判断到底应该使用随机还是固定效应模型。其实从刚才的理论分析我们可以知道,随机效应需要的假设比固定效应更强(因为要求解释变量和个体遗漏特征不相关),但是相比之下,固定效应却有更多的自由度损失(因为待估参数更多),因此我们需要对这二者进行取舍。而取舍的标准就是,如果两个模型的结果相差不大,就选择随机效应,如果两个模型的结果相差较大,就选择固定效应。当然,这里的大或者不大,都是统计学意义上的,我们需要构造一个统计量来判断两个模型之间的差异是否够大,这通常通过豪斯曼检验(hausman)实现。
首先,我们需要执行如下代码,进行随机效应和固定效应的回归和hausman检验:
xtreg $Y $X $X_CON, re // 随机效应
est store re // 记录结果
xtreg $Y $X $X_CON, fe // 固定效应
est store fe // 记录结果
hausman fe re // hausman检验 P < 0.05 则选择固定效应运行程序之后我们会得到这样的结果:
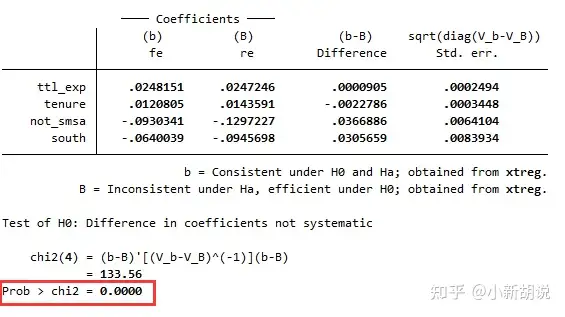
同样,我们还是重点关注这里的Prob > chi2,此处的原假设是接受随机效应,当Prob > chi2小于0.05的时候,认为应该选择固定效应模型。
3.3 固定效应还是双固定效应
在上边其实已经说过,所谓个体固定效应,其实就是(通过虚拟变量或组内去心的方式)控制住了随个体改变,但不随时间改变的变量。按照这个思路,我们还可以做各种各样的固定效应,常见的双固定效应,是时间和个体的固定效应。但是stata中只设定了可以通过, fe的可选项对个体效应进行固定。对时间效应固定则需要通过刚开始介绍的设置虚拟变量和组内去心的方式实现。
xtreg $Y $X $X_CON, fe // 个体固定
xtreg $Y $X $X_CON i.year, fe // 时间固定 + 个体固定此处使用更常用的虚拟变量法进行演示,如果要同时对多个变量进行组内去心,则需要通过areg命令的升级版,reghdfe命令来实现。
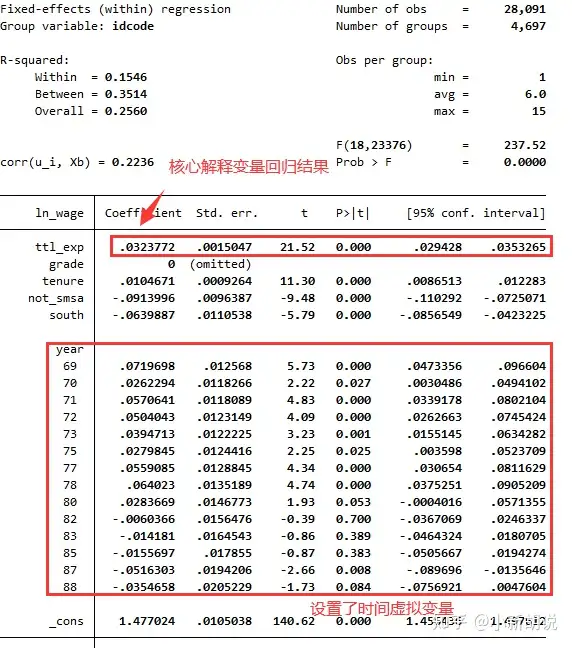
回归结果的读法和普通的回归类似,不多介绍。
至于到底应该选择固定效应还是双固定效应,我个人的观点是:固定时间过后相当于加入了更多的控制变量,在一定程度上可以减少遗漏变量所带来的问题,如果加进去过后没有特别大的负面作用,那么自然是能固定就固定。但是如果加进去过后会导致比较严重的后果(比如说核心解释变量回归系数不显著),那么需要斟酌怎么调整,但是如果只固定个体不固定时间,或是只固定时间不固定个体,都需要做好面对审稿人和评委老师质疑的准备。
4. 完整代码
下边列出完整的回归代码:
clear all // 清楚所有内存
webuse nlswork // 导入官方数据集 -- 需要联网,时间可能有点久
xtset idcode year // 定义idcode为个体变量 year为时间变量
global Y ln_w // 被解释变量
global X ttl_exp // 解释变量
global X_CON grade tenure not_smsa south // 控制变量
* -- 固定效应的本质
/*
keep if mod(idcode,50) == 0 // 只保存编号能被50整除的个体
reg $Y $X $X_CON i.idcode // 使用idcode进行回归 -- 个体太多的时归会很慢
est store reg_dum
areg $Y $X $X_CON, absorb(idcode) // 对idcode进行去心
est store reg_abs
xtreg $Y $X $X_CON, fe // 固定效应模型
est store reg_fe
local results "reg_dum reg_abs reg_fe" // 汇总结果
// 若报错:command esttab is unrecognized --> 说明缺少外部命令
// 则运行:ssc install estout // 注意:不是esttab!
esttab `results', mtitle(`results') replace ///
nogap compress b(%6.3f) s(N r2_a) se ///
star(* 0.1 ** 0.05 *** 0.01) ///
addnotes("*** 1% ** 5% * 10%")
*/
* -- 混合 or 变截距
qui reg $Y $X $X_CON // 混合OLS
qui xtreg $Y $X $X_CON, re // 随机效应
xttest0 // B-P检验 P < 0.05 则选择变截距
* -- 随机 or 固定
qui xtreg $Y $X $X_CON, re // 随机效应
est store re // 记录结果
qui xtreg $Y $X $X_CON, fe // 固定效应
est store fe // 记录结果
hausman fe re // hausman检验 P < 0.05 则选择固定效应
* -- 固定 or 双固定
qui xtreg $Y $X $X_CON, fe // 个体固定
xtreg $Y $X $X_CON i.year, fe // 时间固定 + 个体固定https://zhuanlan.zhihu.com/p/356250433 乱码部分看原网站
众所周知,经济数据有截面数据(cross sectional data)、时序数据(time series data)和面板数据(panel data)三种类型。截面数据是A和B比,时序数据是以前的A和现在的A比,这两种数据都是一维的。而面板数据是二维数据,既有截面维度(n个个体),也有时间维度(T个时期)。比如所有公司所有年份的财务报表数据,再比如知乎这篇文章[1]举的例子:
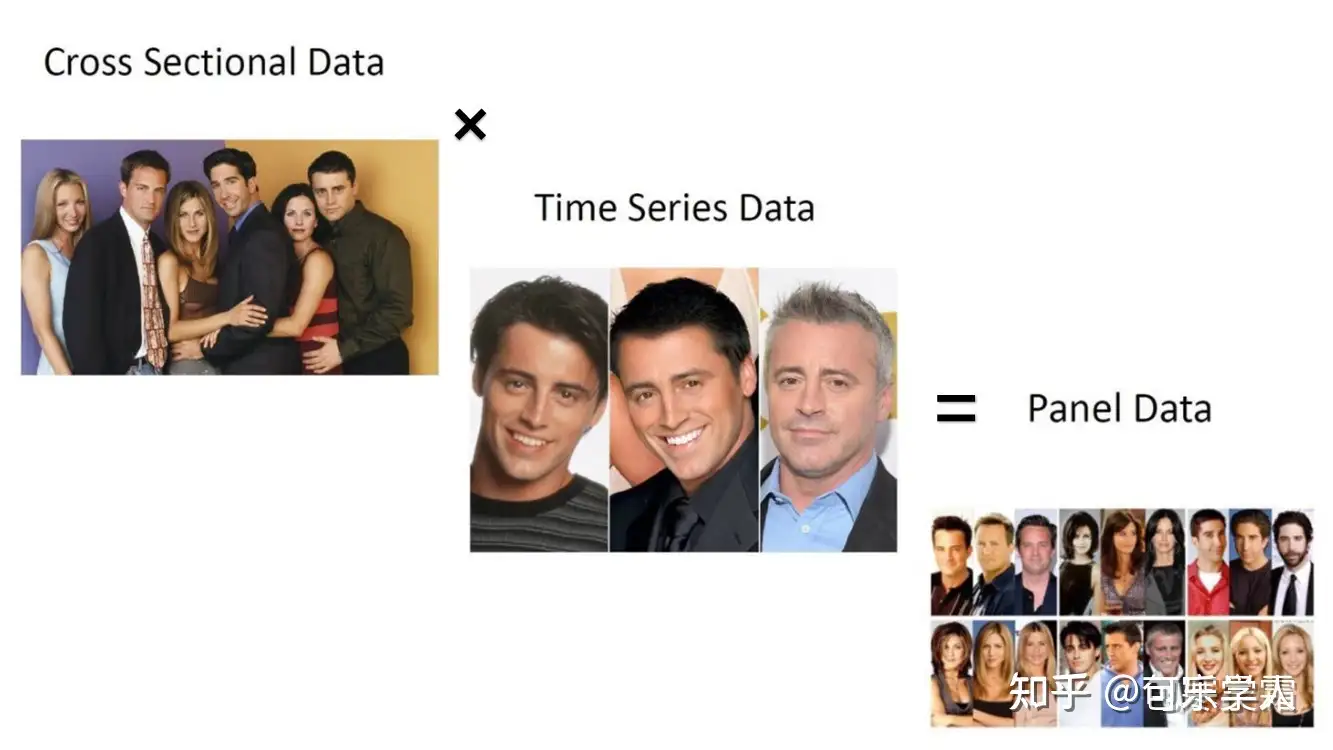
每个个体在不同时间的数据称为一组数据,比如老友记这个例子里面有六个人,所以就有六组数据。同一时点不同个体的差异叫组间差异,不同时点同一个体的差异叫组内差异。说得更直白点,组间差异是Chandler和Joey的颜值差异,组内差异是Chandler不同时期的颜值差异。在面板数据模型中,为了准确地进行参数估计,我们需要同时考虑这两种差异。
面板数据有多种分类方法,今天的笔记只关注最常见的“静态短面板”数据,先讲一讲面板数据的基础设定,然后分别讲一下混合效应、固定效应和随机效应三种估计策略,最后对不同估计方法做个比较。希望大家都有所收获!
这篇文章首发于我的学习笔记类公众号“可乐学人”,欢迎赏脸关注。
静态指解释变量(x)不包含被解释变量(y)的滞后值,短面板指个体(n)多时期(T)少。至于动态面板和长面板,害,能力有限,用到的时候再说吧。
一、模型设定
1. 个体效应模型
先回顾一下截面数据回归时的线性模型形式,�表示第�个个体:
��=��′�+��(�=1,⋯,�)
给截面数据加入时间维度后,线性模型设定如下,�表示第�个时期:
���=���′�+��+���(�=1,⋯,�;�=1,⋯,�)
这种模型叫“个体效应模型”(individual-specific effects model),与截面数据模型的区别在于多了一项��。��是不可观测和量化的随机变量,代表了个体异质性。
比如要研究老友记主角颜值的变化,可以选择主角的收入、是否双眼皮、是否为圆脸等可以观测的因素作为解释变量���,但是性格、习惯等因素也可能对颜值产生影响,而这些数据难以观测和量化。��正是考虑了这种“不随时间变化但随个体变化”的因素。
2. 三种估计策略
面板数据有三种估计策略,区别在于对个体效应��的假定不同。
首先,考虑到个体效应多数情况下难以观测和量化,因此第一种估计策略就是忽略个体效应,直接把所有数据混合到一起进行回归,这种方法叫混合效应模型(Pooled model),也叫混合回归(Pooled regression)。此时,所有个体的回归方程都是一样的,即,截距项和斜率项都一样。
固定效应模型(Fixed effect model)和随机效应模型(Random effect model)则考虑到了个体效应。这两类模型的共同点是模型设定相同,个体差异反映在异质性截距��上,即,不同个体的斜率相同但截距不同。两类模型的区别在于模型假设不同,FE假设异质性截距是非随机的,而RE假设异质性截距是随机的;FE假设��与某个解释变量相关,而RE假设��与所有解释变量均不相关。
接下来我先详细介绍一下三类估计策略,然后再进行细致的比较。
二、混合效应
混合回归假定不存在个体效应,所有个体都拥有一样的回归方程,此时可以把所有数据混在一起,像截面数据一样回归。
然而,因为面板数据结合了截面和时序的特点,所以面板数据的扰动项之间的相关性很有意思:
- 截面特点 → 不同个体之间的扰动项相互独立
- 时序特点 → 同一个体不同时期的扰动项自相关
这样的样本数据可以理解成聚类(cluster)样本,每个个体不同时期的所有观测值构成一个聚类:
- 同一聚类的观测值互相相关
- 不同聚类之间的观测值不相关
此时要用聚类稳健的标准误(cluster-robust standard error),形式上也是夹心估计量。具体可以参考我在异方差和自相关一文中的介绍。
混合回归忽略了个体之间不可观测的异质性,这种异质性很可能与解释变量相关而导致估计不一致。
三、固定效应
1. 个体固定效应模型
个体效应模型的形式如下:
���=���′�+��+���(�=1,⋯,�;�=1,⋯,�)
固定效应模型假设��与某个解释变量相关,也就是复合扰动项��+���与解释变量相关,所以直接进行OLS会导致估计不一致。这种假设下的模型实际上相当于每个个体的截距项不同,而且这种截距的异质性是非随机的,反映在��的不同上。
估计固定效应模型有两大思路。一是通过模型变换消除个体效应��,具体又分为离差变换和差分变换两种,二是通过最小二乘虚拟变量(Least Square Dummy Variable, LSDV)法,为每个个体添加一个虚拟变量,从而反映异质性截距。
实际中估计个体固定效应模型用的最多的方法是离差变换法。首先在方程两边对时间取平均,然后再将原方程减去平均以后的方程,就可以得到离差方程:
���−�¯�=(���−�¯�)′�+(���−�¯�)
可以看到离差方程中没有��,新扰动项与解释变量不相关,所以对这个方程进行OLS的估计是一致的。
离差变换消去了不同个体的组间差异,保留了每个个体的组内差异,因此这种方法的估计结果也称为组内估计量。同时要注意的是,同一个体不同时间的扰动项可能相关,即可能存在组内自相关,所以还需要使用以每个个体为聚类的聚类稳健标准误。
2. 双向固定效应模型
个体固定效应指的是“不随时间而变,但随个体而变”的效应,比如企业文化;与此类似的,时间固定效应指的是“不随个体而变,但随时间而变”的效应,比如企业经营的宏观经济环境。
同时包含个体固定效应和时间固定效应的模型称为双向固定效应(Two-way FE)模型,直接在个体固定效应模型中加入时间固定效应��:
���=���′�+��+��+���(�=1,⋯,�;�=1,⋯,�)
其中,��刻画时间固定效应,��刻画个体固定效应。
时间固定效应模型一般通过最小二乘虚拟变量(Least Square Dummy Variable, LSDV)来估计。对每个时期定义一个虚拟变量,把(�−1)个时间虚拟变量包括在回归方程中:
���=�+���′�+∑�=2�����+��+���
因为虚拟变量的存在,所以每个时间�的截距项都不同,这就体现了时间固定效应。
3. 固定效应模型小结
固定效应模型的相关内容可以总结为以下三点:
- 假定:个体效应��与解释变量相关,每个个体都有非随机的截距项
- 估计:主流估计策略为“双向固定效应+聚类稳健标准误”
- 结果:可以得到一致估计
四、随机效应
1. 模型设定
随机效应模型和固定效应模型的回归方程一样,都是之前提到的个体效应模型:
���=���′�+��+���(�=1,⋯,�;�=1,⋯,�)
不过随机效应模型假定��与解释变量不相关,也就是说,异质性截距反映在随机的扰动项里。在这种假设下,OLS估计一致,但是因为同一个体不同时期的扰动项中都存在��项,所以一定存在自相关,导致估计不有效。
回想线性回归的模型设计中介绍的线性回归模型六大经典假定可知,随机效应模型的设定违背了球形扰动项假定。
球形扰动项(spherical disturbance)是指扰动项的协方差矩阵与单位矩阵成正比,异方差和自相关是常见的违背球形扰动项假定的情形。
Var(�|�)=E[��′∣�]=�2��
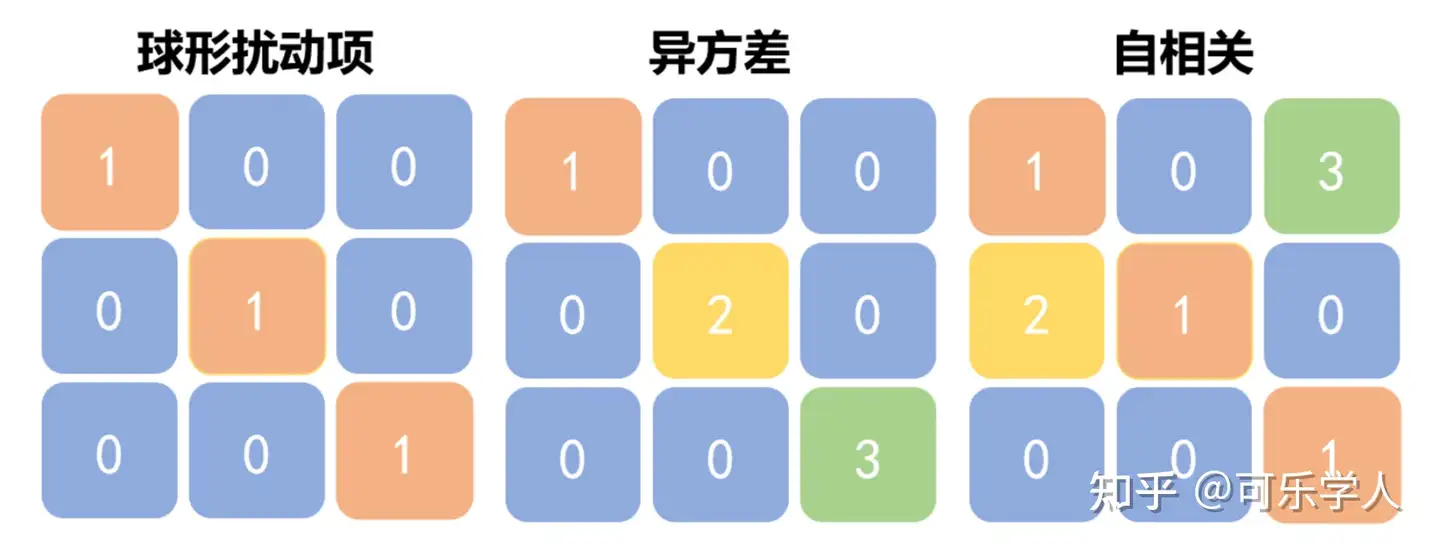
根据随机效应模型的设定,不难得出随机效应模型的扰动项协方差阵不与单位阵成正比:
- 同一个体扰动项的协方差阵可以写成:
Σ=(��2+��2��2⋯��2��2��2+��2⋯��2⋮⋮⋮��2��2⋯��2+��2)�×�
- 整个样本扰动项的协方差阵为块对角矩阵(block diagonal matrix):
Ω=(Σ⋯0⋮⋮0⋯Σ)��×��
2. 估计方法
回顾我在异方差和自相关一文中的介绍,广义最小二乘法方法通过变量转换,可以使变换后的模型满足球形扰动项的假定。实践中,可以先用样本数据估计出未知参数,然后使用GLS,这个估计方法称为可行广义最小二乘法(Feasible GLS)。
作为不搞理论计量的人,这些估计方法最重要的是理解和应用,所以下面写的这几行,了解了解就行了。
首先定义:
�=1−��(���2+��2)1/2=1−(��2���2+��2)1/2
接着,将原方程两边对时间进行平均,并在两边同时乘以�,再将原方程减去新方程,可以得到广义离差(quasi-demeaned)模型:
���−��¯�=(���−��¯�)′�+(1−�)��′�+[(1−�)��+(���−��¯�)]
可以证明,广义离差方程的扰动项不再有自相关,对广义离差方程进行OLS估计,即为GLS估计量。
另外,因为�通常未知,所以要先估计�^:
- 因为OLS一致,OLS的扰动项为��+���,所以可以用OLS的残差估计��2+��2
- 因为FE一致,FE的扰动项为���−�¯��,所以可以用FE的残差估计��2
3. 随机效应模型小结
随机效应模型的相关内容可以总结成如下三点:
- 假定:个体效应��与解释变量不相关,异质性截距反映在随机扰动项中
- 估计:估计策略与截面数据处理自相关类似,用广义最小二乘法
- 结果:满足假定时,可以得到一致且有效的估计
五、估计策略比较
1. 混合效应 vs 个体效应
混合效应模型,所有个体的回归方程相同,即,截距和斜率都相同。
个体效应模型,同时考虑个体的共性和异质性,共性表现在斜率相同,异质性表现在截距不同。
比如,橙色和蓝色的点分别表示两类个体,混合回归是将所有个体一起回归得到绿色的线,固定效应模型则用异质性截距考虑到了个体差异:
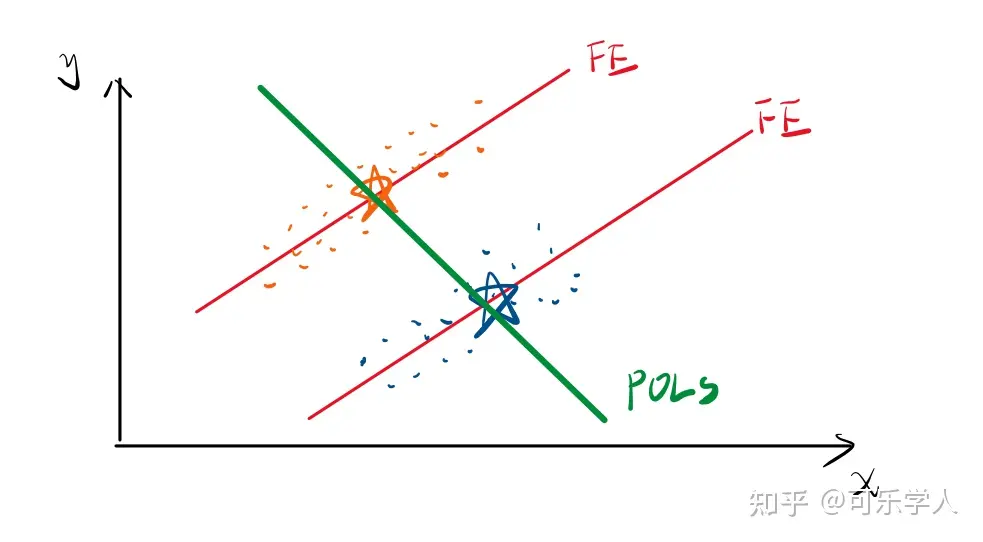
2. 固定效应 vs 随机效应
固定效应,异质性截距与自变量相关;随机效应,异质性截距与自变量无关。
固定效应模型的假定下,OLS不一致,解决方法是通过转换模型消去��,从而获得一致估计;而随机效应时,OLS一致,但因为��的存在,球形扰动项假定不满足,解决方法是用广义最小二乘法将扰动项变为同方差,从而获得有效估计。
用豪斯曼检验(Hausman,1978)可以判断到底使用FE还是RE。原假设是“随机效应模型为正确模型”,即检验原假设“�0:��与���不相关”。注意到:
- 原假设成立时,FE与RE都一致,但RE更有效
- 原假设不成立时,FE一致,而RE不一致
也就是说,原假设成立时FE与RE都一致,这就意味着二者的估计量将共同收敛到真实的参数值:两者之差(�^��−�^��)依概率收敛到零。如果两者差距过大,就倾向于拒绝原假设。
以二次型度量这个距离,并使用Wald统计量的形式(Wald检验只考虑无约束估计量,LM检验只考虑有约束估计量,LR检验同时考虑无约束和有约束估计量),就可以检验这个原假设。
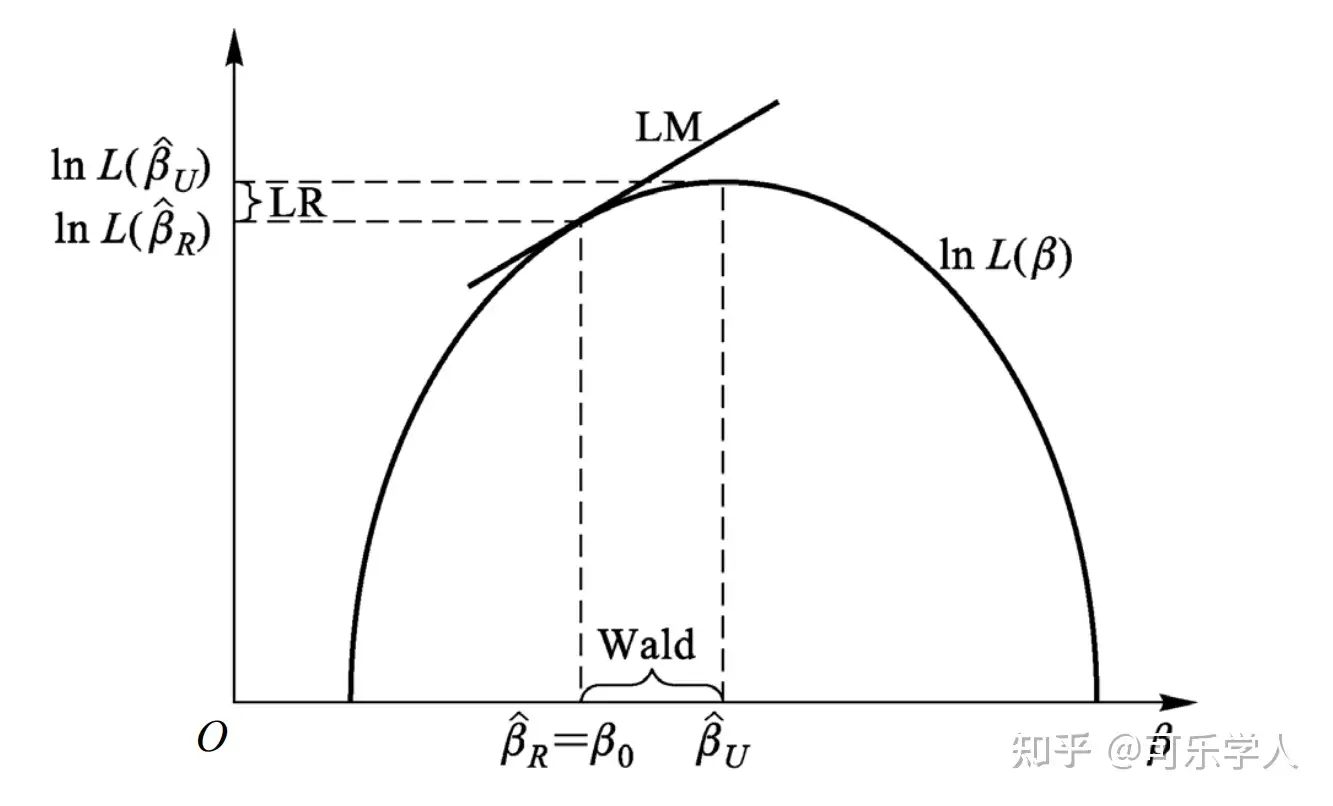
不过,传统的豪斯曼检验的缺点在于不适用于异方差的情形,需要使用bootstrap hausman检验法或异方差稳健的Hausman检验。这里就不再赘述了,具体可以参考陈强老师的教材或者连玉君老师的文章[2]。
总结
今天的文章讲了静态面板数据的模型设定和估计策略。在经济学领域,最常用的模型是固定效应模型,最主流的估计方法是“双向固定效应+聚类稳健标准误”,对应的两种等价stata命令为:
xtreg y x1 x2 i.year, fe robust
reg y x1 x2 i.id i.year, vce(cluster id)另外,实证文章中用到双向固定效应模型时常常会使用要求没那么严苛的行业和年份固定效应,或者地区和行业固定效应。因为个体效应相当于每个个体截距项都不同,而行业固定效应则只需要给每个行业设置不同的截距项就可以了。“行业年份双向固定效应+行业聚类稳健标准误”的stata命令为:
reg y x1 x2 i.industry i.year, vce(cluster industry)最后推荐一点有助于我学习面板数据的资料。首先还是强推陈强老师的教材《高级计量经济学及Stata应用》,废话少,而且偏应用,没那么枯燥;其次是连玉君老师的网站连享会[3],很多教材里没有的细枝末节问题里面都有讨论;最后是知乎的一篇文章[4],不同学科对FE和RE的理解不同,这篇文章详细讨论了方差分析、元分析、面板数据模型中FE和RE的区别。
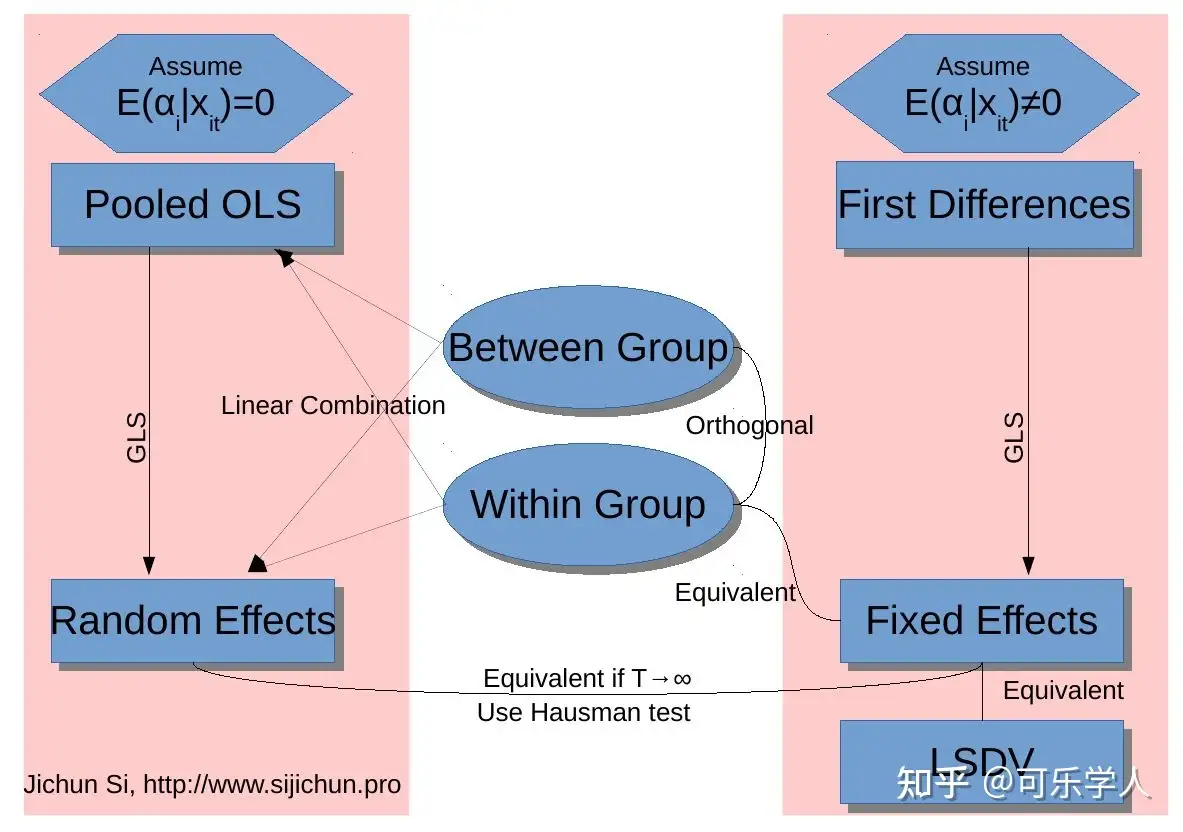
最最后,知乎大神慧航有这么一幅图总结了面板数据分析里各种估计量的关系,Pooled OLS、Fixed Effects和Random Effects就分别对应了本文中提到的混合效应、固定效应和随机效应。First Differences是估计固定效应模型时的一阶差分法,Between Group和Within Group分别代表的是组间估计量和组内估计量。背后的证明没必要自己徒手去证,从整体上了解到各个方法之间实际上是有内在联系的,这就够了。
以上,就是本次分享的所有内容,如有错误欢迎批评指正,如果对你有帮助,可千万别忘了夸一声可乐最酷啊。我也超爱你们的!
参考资料
[1] 统计学中的「固定效应 vs. 随机效应」: https://zhuanlan.zhihu.com/p/60528092
[2] 面板数据模型一文读懂: https://www.lianxh.cn/news/bf27906144b4e.html
[3] 连享会网站: https://www.lianxh.cn/
[4] 统计学中的「固定效应 vs. 随机效应」: https://zhuanlan.zhihu.com/p/60