OPEN-FLACON—PROMETHEUS—ZABBIX—NIGHTINGALE
‘对比’
Zabbix 是过去二十年里开源监控系统的代表作,有着广泛的用户基础,如果没有原生和微服务架构的流行,Zabbix 本可以连续代表下一个二十年。作为 Zabbix 忠实用户的你,或许正经历着传统架构往云原生架构转型,当你选择在容器架构下,把众多微服务的监控数据往 Zabbix 数据模型上套,削足适履,会发现非常辛苦,甚至于很多时候根本都行不通。
Zabbix的优点
- 功能较为全面、官网提供详细的文档,网络及社区相关资料较多。
- 对基础设施、网络等设备兼容性较强,简单配置即可接入。
- 丰富的模板和协议支持,可根据设备类型搜索导入即可使用。
- 灵活的采集和处理方式,可自定义脚本采集并通过预处理对数据进行二次处理。
- 完善的API可灵活实现数据及系统的对接及调用。
- 代码全部开源,社区资源活跃,商业化技术支持丰富完备。
Zabbix的不足
- 相对固定的数据模型,导致数据表达能力有限,难以适应现代微服务架构监控。
- 系统容量有限,不仅仅表现在趋势数据存储压力大,标签数据存储更是挑战。
- Dashboard 配置较为麻烦,告警策略配置复杂,门槛较高。
- 架构设计耦合严重,代码实现复杂,对系统本身进行二次开发较难。
- 功能丰富众多,对运维人员能力要求较高,不利于多人协作。
显然,老架构用 Zabbix,微服务架构用 Prometheus,多云监控用云厂商各自提供的云监控,工程师被迫维护和使用多套监控系统,并不是大家期望的最佳局面。那么,有没有一个现代化的、简单好用的监控产品,既可以满足传统架构的监控需求,又可以适用K8s时代微服务架构的监控、混合云的监控?
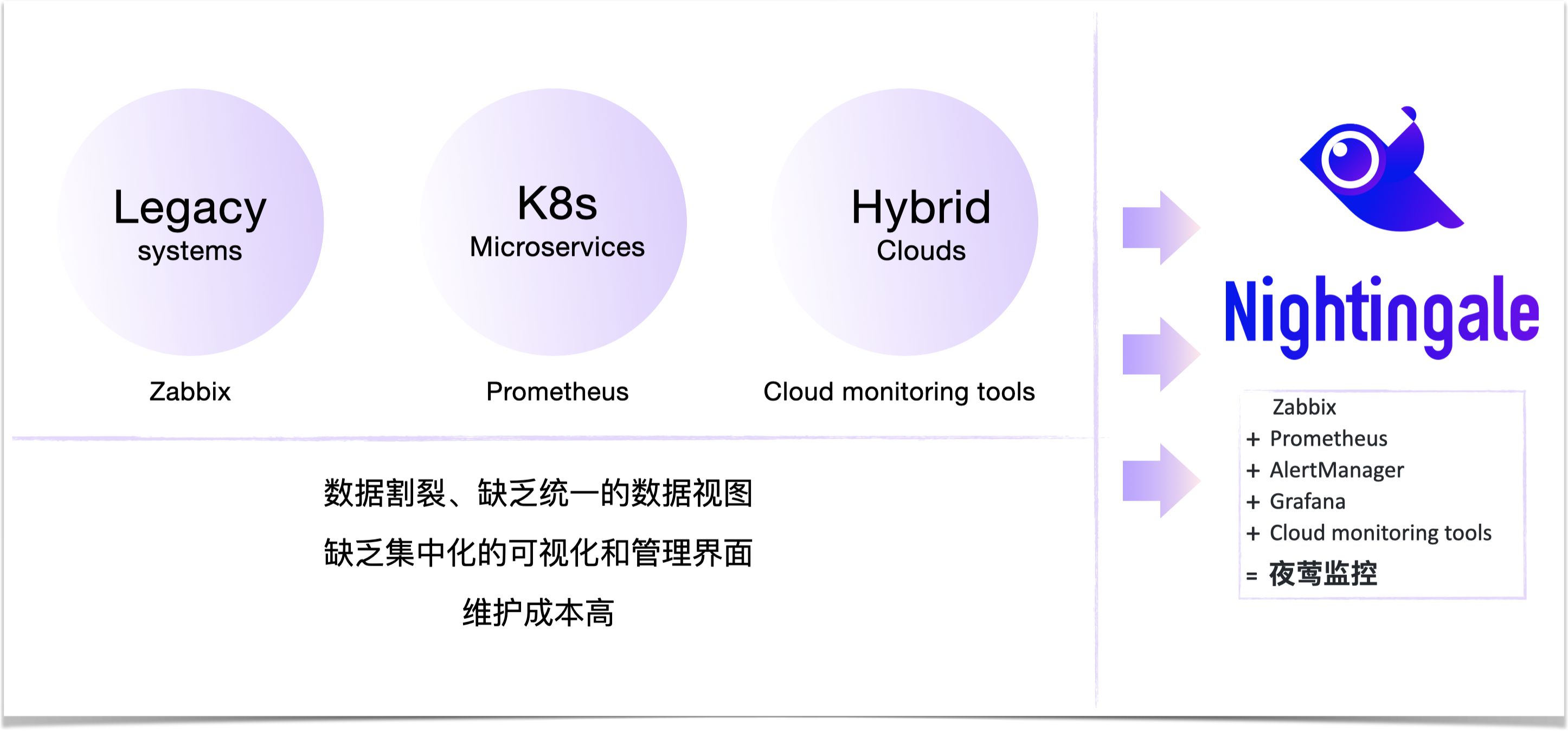
今天给大家详细介绍一款现代化的开源监控解决方案—夜莺监控 | Nightingale。夜莺监控,采用 All-in-one 的产品化设计理念,集数据采集、可视化、监控告警、故障协同处理于一体,与云原生生态紧密集成,提供开箱即用的企业级监控分析和告警能力。于 2022 年 5 月 11 日,捐赠予中国计算机学会开源发展委员会(CCF ODC),为 CCF ODC 成立后接受捐赠的首个开源项目。
夜莺监控的设计目标
- 好看、简单、功能全面:
- 自研数据采集器Categraf,采什么、怎么采、采了数据怎么用,全部开箱即用;
- 告警功能十年沉淀,业界首选;
- 自研可视化引擎,媲美 Grafana;
- 支持告警聚合、收敛、排班,协同处理(需要对接 SaaS 应用);
- 同时适合传统架构 & 云原生架构 & 混合云架构;
- 多数据源架构设计,适应灵活多变的部署环境和生态;
- 可扩展架构设计,水平扩展;
- 兼顾中心化部署和边缘设备集群管理;
- Go语言开发,架构设计简洁,适合二次开发;

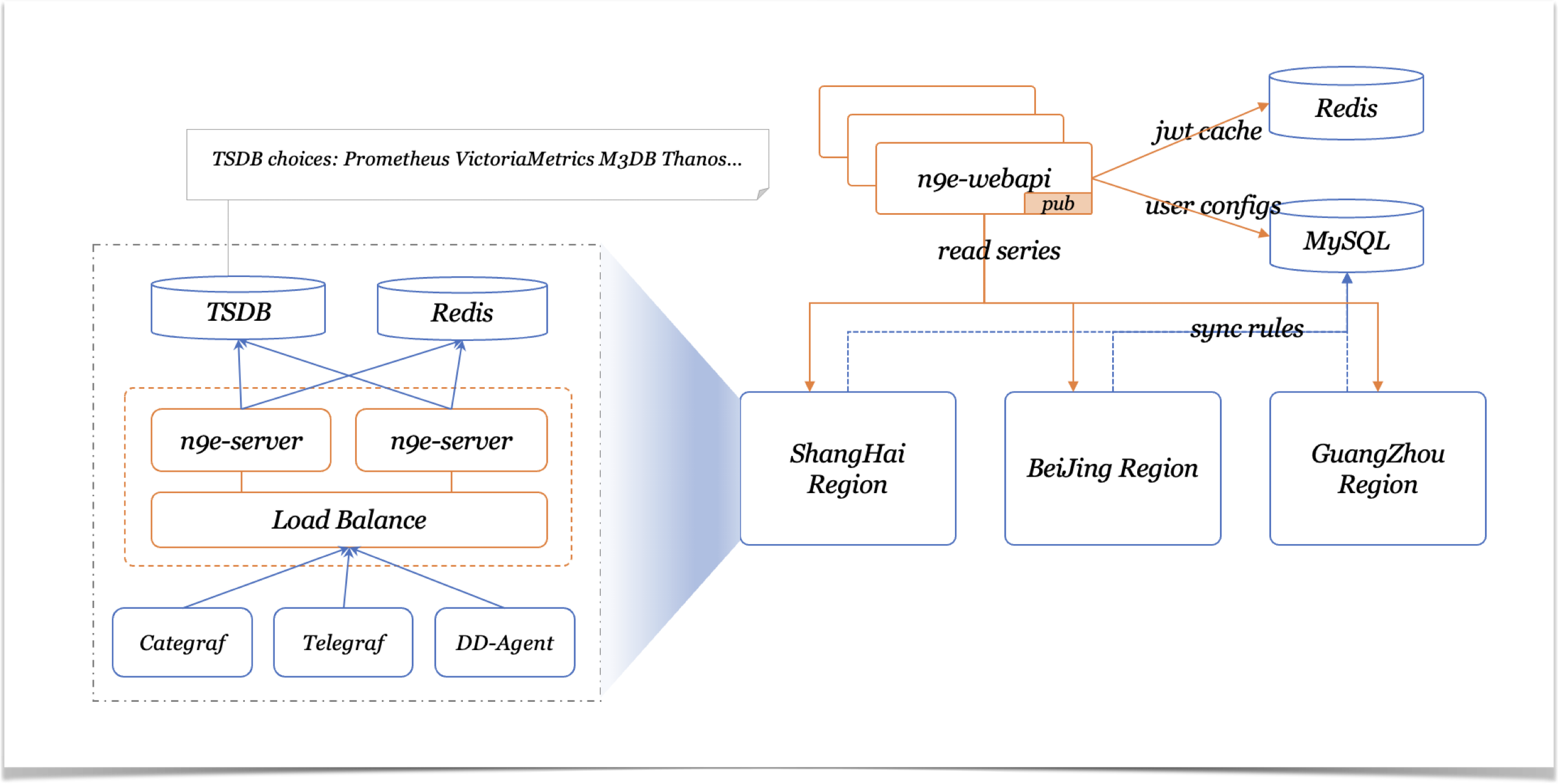
夜莺监控架构
夜莺监控由数据采集器、告警分析引擎、可视化引擎、告警自愈引擎构成。夜莺的设计非常简单,核心是 server 、webapi、frontend三个模块。
webapi 无状态,中心端部署,承接前端frontend的请求,将用户配置写入数据库,同时对外提供API 供frontend 使用;server 是告警引擎,也承担数据处理、转发功能,一般伴随着时序数据库部署,一个时序库就对应一套 server,每套 server 可以只启动一个实例,也可以启动多个实例组成集群。server 可以接收 Categraf、Telegraf、Grafana-Agent、Datadog-Agent、Falcon-Plugins 等多种数据采集器上报的数据,写入后端时序数据库,并周期性从数据库同步用户配置的告警规则,查询时序库进行告警判断。此外每套 server 依赖一个redis作为队列,比如产生的告警事件会进入到不同的队列。
自研数据采集器Categraf,开箱即用
夜莺默认的数据采集器 Categraf,有以下特点:
- All-in-one:所有的采集工作使用一个 agent 来解决,包括 metrics、logs、 traces 和 events ,并从数据采集的源头建立起数据间的关联关系,保障好数据的质量。
- 开箱即用:覆盖支持上百种采集对象,包括K8s、中间件、服务器、交换机等,针对常用的采集对象,在提供采集能力的同时,配套有默认的监控仪表盘模板和告警规则模板,用户可以直接导入并使用。
- 部署方式灵活:支持在 K8s 集群中以 Daemonset 或者 Sidecar 运行,支持公有云产品的数据采集,也支持独立运行在宿主机上。
- Go语言开发:安全、易分发、易安装维护,插件化。

告警功能十年沉淀,业界首选
- 支持多数据源告警,Prometheus、Victoriametrics、M3DB、Thanos,ElasticSearch、SLS;
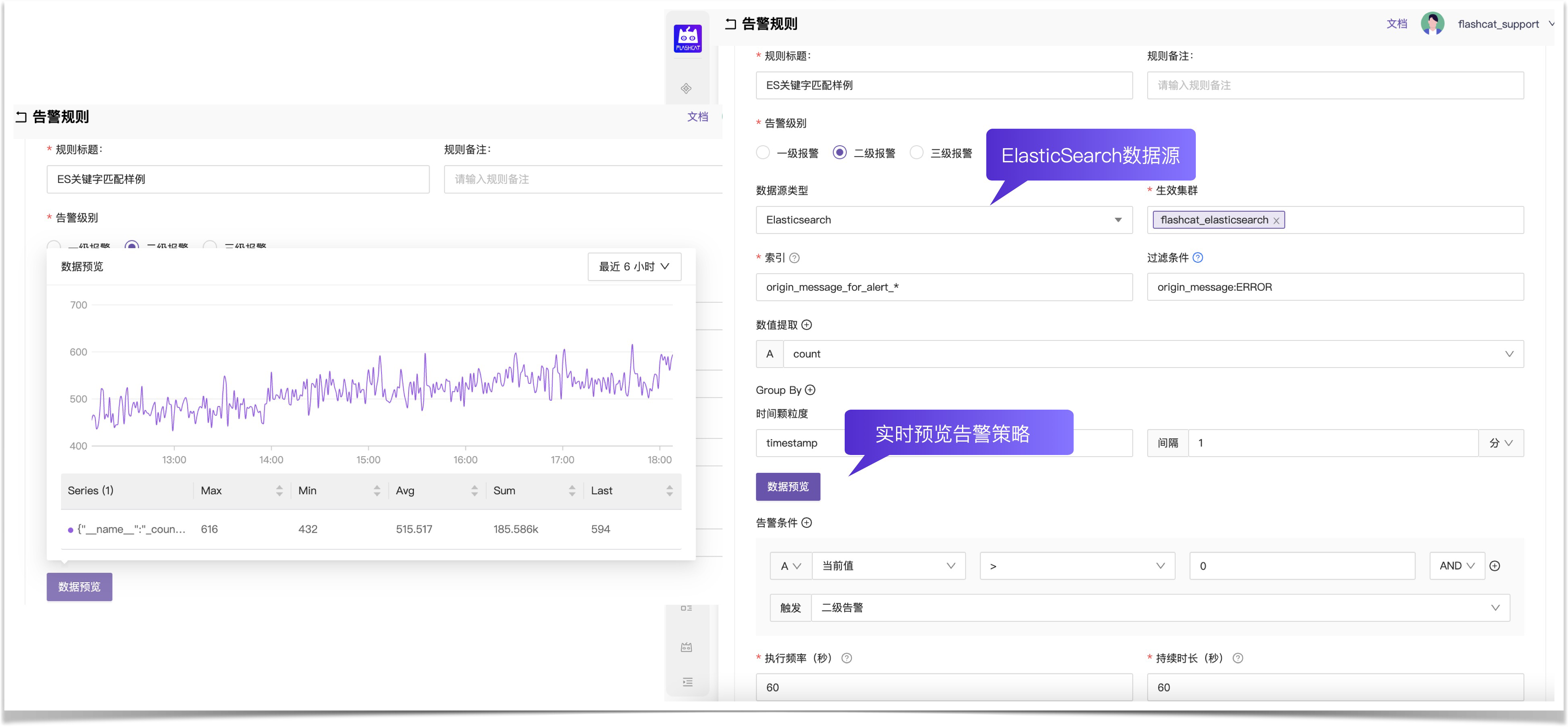
- 多种告警判定策略,多条件策略,生效周期,产品化配置和管理;
- 多通知渠道和自定义通知模版;
- 支持故障自愈和告警 Webhook;
- 支持告警聚合、收敛、排班、协同(需要对接Flashcat SaaS应用);
自研可视化引擎,媲美Grafana
一图胜千言,夜莺监控的 Dashboard 不仅从功能、设计上可以媲美 Grafana,同时也兼容 Grafana,要是你觉得 Grafana 某个 Dashboard 非常有用,甚至可以直接导入到夜莺监控中使用。
此外,夜莺监控的 Dashboard 支持多种数据源,比如时序数据库 Prometheus、Victoriametrics、M3DB、Thanos,又比如日志数据源 ElasticSearch、SLS 等。
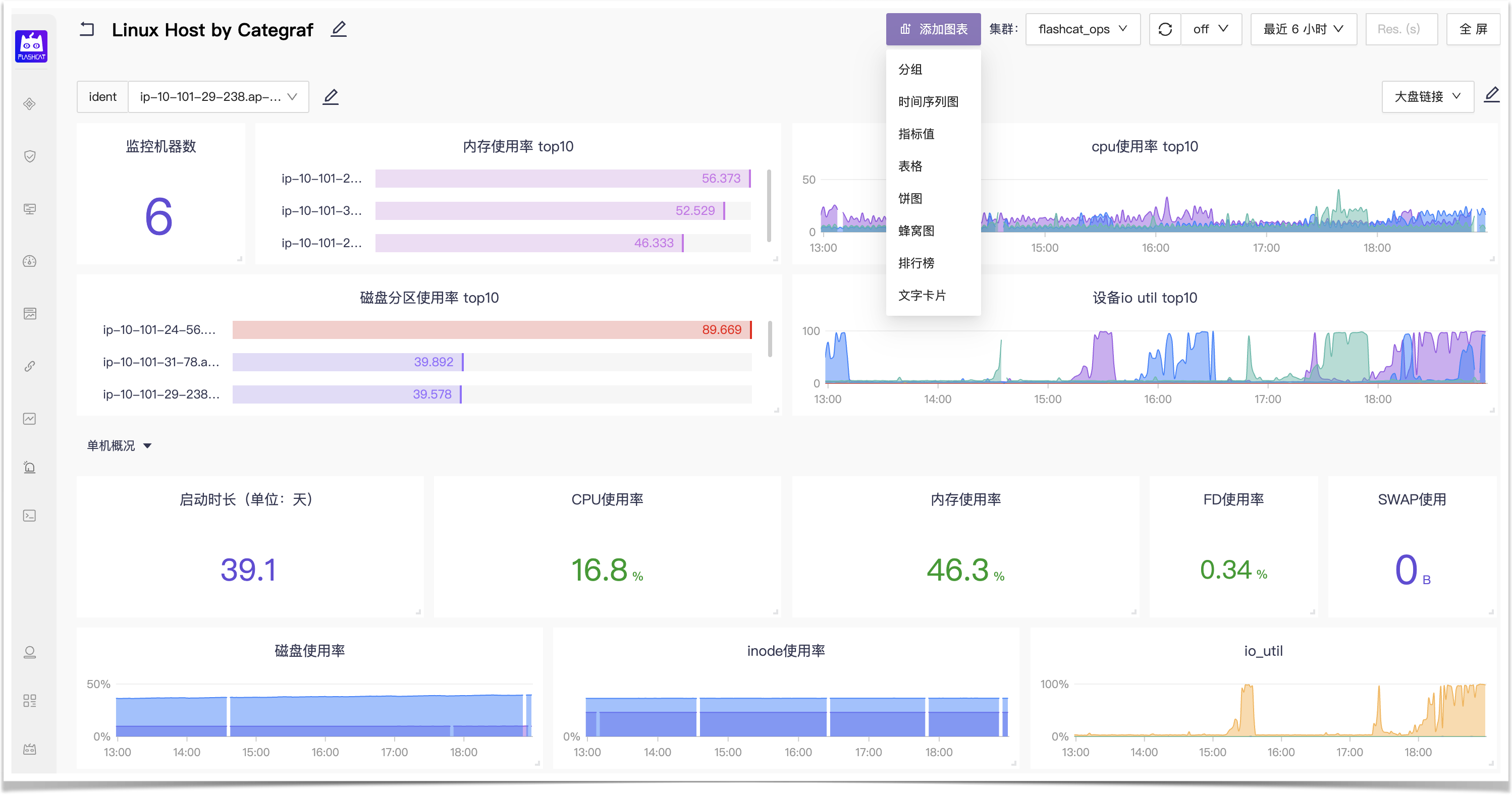
下载使用
你可以通过多种方式,安装和使用夜莺监控:
- 使用 Docker Compose 方式,快速体验:https://n9e.github.io/docs/install/compose/
- 使用 Helm Chart 方式快速安装夜莺到你的 K8s集群:https://n9e.github.io/docs/install/helm/
- 使用二进制:https://n9e.github.io/docs/install/server/
- 通过源码编译:https://github.com/ccfos/nightingale/blob/main/Makefile
欢迎各位 Zabbix 小伙伴,包括但不限于以下方式参与到夜莺开源社区:
- 在 Github Issue 中积极参与讨论,参与社区活动;
- 提交代码补丁;
- 翻译、修订、补充和完善文档;
- 分享夜莺监控的使用经验,积极布道;
- 提交建议 / 批评;
夜莺监控社区资源:
- 夜莺监控项目文档站点:https://n9e.github.io
- 欢迎大家在 Github 上 Star 夜莺项目:
云原生监控的十大特点和趋势
laiwei2022年5月25日
Open-Falcon 从写下第一行代码,应该是在 2012 年的冬天,开源于 2014 年。Open-Falcon 在设计之初,沉淀的主要是互联网公司在运维大规模物理机时代的优秀方法论,在简单易用、扩展性、性能方面倾注了较多的心思,凭借于此,开源之后迅速成为国内开源监控系统的首选,服务了上千家企业用户,并影响了国内互联网运维圈子一个阶段对于监控系统系统的设计思路。
然而在过去的十年,微服务架构与 Cloud-Native,相伴相生,各自在最好的时间遇到了最好的对方,并相互促进发展。微服务和云原生,给服务和系统的可维护性,带来了巨大的挑战,系统的整体复杂度和系统之间的相互依赖程度更高,可观测性被提到了 IT 系统有史以来重要的位置,成为系统设计天然不可分割的有机组成部分。而 Prometheus 无疑已成为该领域的事实标准。
Open-Falcon,算起来是和 Prometheus 同岁。当初的产品定位(以及后续的投入),已然埋下了今天的差距的伏笔。在这里我仅以 Open-Falcon 数据模型中两个字段的定义,管中窥豹,来说说当时设计思路的一些纠结和折中。
{
metric: load.1min,
endpoint: open-falcon-host,
tags: srv=falcon,idc=aws-sgp,group=az1,
value: 1.5,
timestamp: `date +%s`,
counterType: GAUGE,
step: 60
}
在上面的 data model 定义中,tags 字段和 Prometheus 中的 labels 字段是同样的效果,而 labels 是云原生监控系统数据模型的灵魂,从这个点上可以看出,Open-Falcon 的设计是不落后于同时代的最先进的理念的。
但是 Open-Falcon 在 tags 字段之外,定义了一个特殊的标签,即 endpoint,endpoint 在物理机场景下一般会被设定为 hostname 或者 ip:port;在物联网场景下,一般是设备名称;在容器场景下,一般会是容器的 ip。为什么在当初要定义一个 endpoint 这样的一等公民标签呢?这个标签又有什么特殊性呢?说到底是在系统设计上犯了一个核心的错误:定位不明确。既要又要,既想要满足当时处于主流的物理机运维模式(在物理机场景下,hostname 是最重要的一个『维度』),又想兼顾未来物联网、容器场景。后来的事实证明了,定位不明确、不聚焦是行不通的。
相反的,Prometheus 从第一天起,就是单机版,并没有把重心放在什么扩展性的问题上;从第一天起,就从 data model 定义上,抛弃了 hostname ,完全围绕着 metric 字段,结合 label 形成灵活、普适的表达形式,以及进而形成了灵活的监控数据检索标准 PromQL ;从第一天起,就咬定了 Kubernetes ,聚焦在云原生场景,抓住主要矛盾,做标准,建生态。至于什么性能,什么扩展性,什么易用性,这些问题都交由强大的生态伙伴,在后来去解决的,也从另一个角度印证了「过早的优化是万恶之源」。
着眼未来,云原生监控的发展,呈现出以下十个特点:
1、infra 层面监控数据比重变小,app 层面监控数据比重快速增加
有别于物理机时代,更多在关注主机、系统层面的 metrics,在今天,Mesh、Pod、App、Business 层面,所产生的 metrics 占到了更大比重,以生产实践中的统计为例,占比达到了 80% 上下。
2、监控产品的使用对象发生了变化,从专职运维人员拓展到人数众多的研发和运营群体
云原生时代,监控系统的使用群体发生了变化,从面向规模较小的,具备专业能力的专职运维工程师群体,变成了更广大的研发、测试、运营人员群体,监控产品的体验好坏、入门门槛足够低、是否能够开箱即用,变得极为重要,监控系统有往指标中台方向演进的趋势。
3、监控数据的采集原则发生了变化,应用对自身运行状态的自描述成为主流,数据应收尽收,治理前置成为指导原则
数据的采集、存储、计算的成本在下降,数据的重要性在凸显,此消彼长,数据应收尽收,治理前置,成为了应用和系统开发人员的埋点原则。eBPF 技术的发展和普及,使得数据捕获和应用层更解耦,在网卡、网络协议栈、内核等环节更高效的进行埋点和数据解析,并形成系统的、普适的解决方案。
4、监控数据模型的维度变得更丰富
Label 作为云原生 Metrics 监控数据模型的灵魂,Open Metrics 成为事实上的云原生 metrics 标准。数据维度更多,对监控系统的架构设计、扩展性、产品交互体验,提出了挑战。
5、Metrics 的生命周期变得更短
在微服务和云原生架构下,Pod 的生命周期不再是长期的,其状态变化的频率也更高。这使得对于监控数据的连续性追踪和关联分析变得更困难。
6、针对监控数据的 Ad Hoc 查询需求变大
在微服务和云原生架构下,单个 Pod 的状态监控重要性下降,用户更关心以 App 维度,或者其他 Label 维度的聚合查询,此类 Ad Hoc 查询的灵活度和性能,如何在产品设计和系统架构设计上取得折中,变得非常关键。
7、Metrics 与 Logs、Traces 的相互打通以及建立关联关系重要性凸显
由于微服务和云原生架构的复杂度和封装,使得系统管理员和研发人员,很难再去到具体的机器和案发现场,通过查询日志等方式来 debug。如何在监控系统层面,将 metrics、logs、traces 相关信息打通,对于研发、运维和运营人员,能提供更多的便利。
OpenTelemetry 试图从数据采集层面解决该问题,通过定义和提供一组 APIs、SDKs、工具集以及对相关生态的集成,以便于实现对metrics,logs,traces数据的创建和管理。
OpenTelemetry提供了一个中立的实现,可以通过配置把可观测数据发送到各种流行的开源可观测系统,譬如Jaeger,Prometheus,ElasticSearch。但是到此为止,OpenTelemetry 并不会大包大揽,去实现一个后端的诸如 Jaeger 或者 Prometheus 那样的后端存储、计算、可视化的系统。
8、基于数据而高于数据的 Insight & Knowledge 成为评价监控产品的能力标准之一
在数据应收尽收的背景下,数据多,如果缺乏有效的洞察手段和数据处理手段,那么数据多反而会变成一种干扰和负担。如何提供全局统一的数据视图,建立有效的信息系统,把知识沉淀、赋能,对于监控产品的用户可以发挥更大价值。
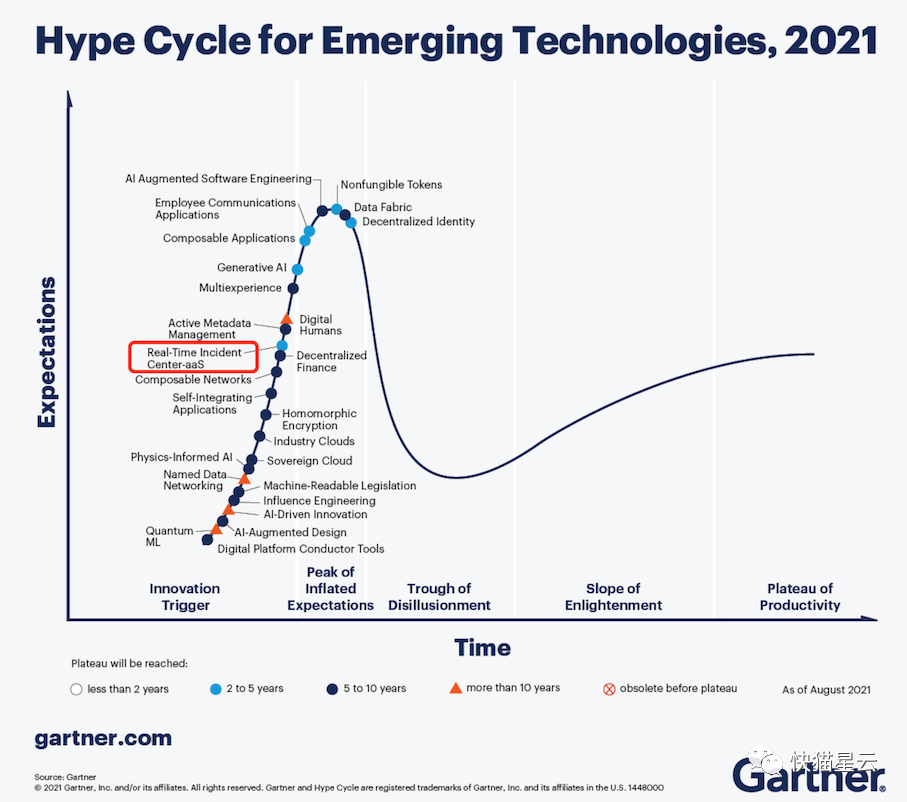
Real-Time Intelligent Incident Center 是搭建该信息系统的一个有效手段。Gartner 在 Hyper Cycle for Emerging Technologies, 2021 中,也对此做出了预测,Real-Time Incident Center 将在未来的 2 到 5 年到达成熟期。
9、OaC / API-Driven 获得开发者青睐
体验优秀的交互设计和Web UI,对于扩大用户使用群体,降低系统的使用门槛帮助很大,也能够有效减少监控产品维护人员的客服成本,但是也容易被工程师诟病这种 ClickOps 的方式效率太低,不利用自动化、缺乏重复执行的一致性。
在工程师的群体内,对于云计算资源/服务的申请、使用、销毁等工作,以 git pull-request 来追踪版本变化和 change review,以 pipeline 高度自动化运行,正在成为一种更高效和流行的文化,OaC 就是监控在这个流行趋势的产物之一,这背后是靠监控产品良好的 API 抽象所驱动的。
Terraform 开源项目作为目前 IaC 领域的事实标准,本质上相当于把各个云所提供的能力和服务,透过其 API,换了一种形式,以 code 的方式方法,对其进行了表达和管理。code 最大的优势是一次编写,可重复的运行并保证一致性,这使得对于 infra 和相关服务的上下线、扩缩容、加减配置、修改监控等操作,都可以高度自动化。
10、监控系统本身也要云原生:)
监控系统自身的部署架构是否支持容器化,以 binary、sidecar、daemonset 等多种方式运行,是否支持 opentelemetry / open metrics 相关标准,是否支持 service discovery,是否兼容 PromQL 等 Query Language,是否可以方便的通过 docker-compose、helm chart、k8s operator 等方式运行管理。这些都是作为一个云原生监控系统本身要先自我革新的方面。
如前所述,Prometheus 虽然已成为该领域的事实标准。但是,Prometheus 重心是在定标准,打造基础能力,构建生态,这个定位和认知,无限加强了其在监控的基础能力和标准层面的影响力,但也制约了其在企业级产品化方向上的发展,肌肉记忆造成的强大惯性使然。
Prometheus 在企业级监控的产品特性上,仍然有很大的痛点至今未被很好的满足,比如入门门槛高易用性的问题,扩展性的问题,企业较大范围用户使用时协同的问题,all-in-one开箱即用的问题等等。
经过 Open-Falcon 的经验积累和认知迭代,结合云原生监控的趋势特点分析,2020年,我们和滴滴技术团队推出了企业级云原生监控系统 Nightingale v5 开源新版本,重点聚焦在云原生场景,在 Prometheus 的生态基础上,重点加强其企业级特性提升、产品化的创新以及解决方案的落地。
简而言之,如果在架构云原生监控的过程中,有以下的一个或多个困扰,那么请毫不犹豫的联系我们一起探讨:
- 如果您对 Prometheus、Alertmanager、Grafana 等多个系统的割裂和上手难有怨言;
- 如果您对通过修改配置文件来管理 Prometheus、Alertmanager 的方式有痛点;
- 如果您对因为数据量过大而无法扩展您的 Prometheus 感到有困扰;
- 如果您在生产环境运行多套 Prometheus 集群面临管理和使用上的不便;
- 如果您在企业数字化转型过程中对于如何架构适合您的云原生监控方案有困惑;
Nightingale v5 支持的新特性一览:
- 好用和实用的开源告警功能和事件中心;
- 原生内置 dashboard、故障自愈、Resource管理功能;
- 支持多 Prometheus 数据源管理;
- 支持 Prometheus、M3DB、VictoriaMetrics、Influxdb 多种时序库;
- 原生支持 PromQL;
- 原生支持 Exporter 数据采集;
- 支持 Telegraf 做监控数据采集;
- 原生支持 Grafana;
一个典型的 Nightingale 企业级部署架构(以VictoriaMetrics作为时序数据库为例): 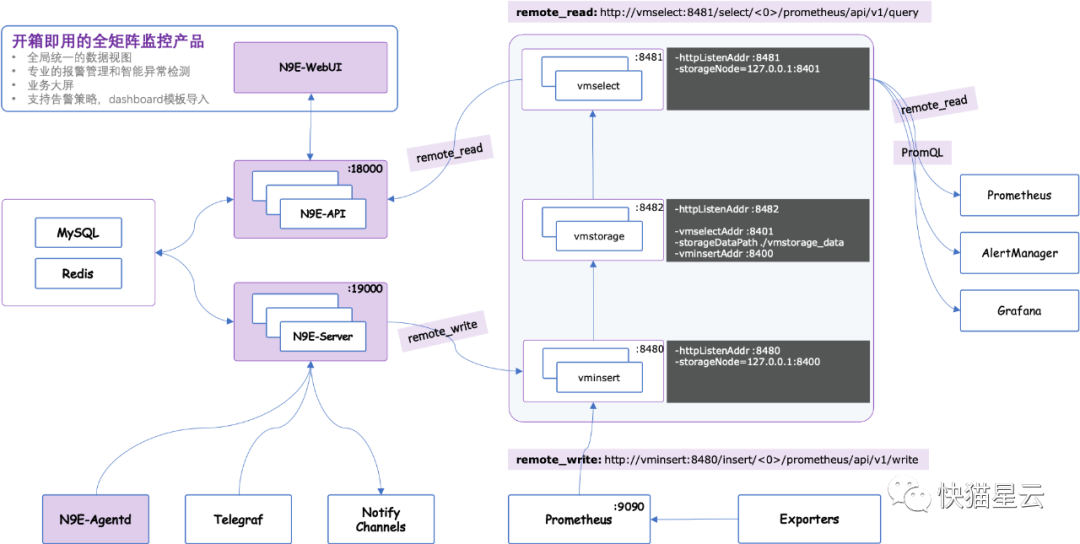
最后,关于十大特点中提到的,Gartner 所预测的 Real-Time Intelligent Incident Center,大家可以参考快猫星云 Flashcat 解决方案(https://flashcat.cloud)。
关于夜莺监控 – Nightingale
夜莺监控是一款开源云原生监控分析系统,与云原生生态紧密集成,提供开箱即用的企业级的监控分析和告警能力,已有众多企业选择将 Prometheus + AlertManager + Grafana 的组合方案升级为使用夜莺监控。
- Github:github.com/ccfos/nightingale
- Proposal & Issues: github.com/ccfos/nightingale/issues
- Docs: n9e.github.io