从Reasoning 思考到agentic思考范式的转变
来自林俊旸的博客
The last two years reshaped how we evaluate models and what we expect from them. OpenAI’s o1 showed that “thinking” could be a first-class capability, something you train for and expose to users. DeepSeek-R1 proved that reasoning-style post-training could be reproduced and scaled outside the original labs. OpenAI described o1 as a model trained with reinforcement learning to “think before it answers.” DeepSeek positioned R1 as an open reasoning model competitive with o1.
That phase mattered. But the first half of 2025 was mostly about reasoning thinking: how to make models spend more inference-time compute, how to train them with stronger rewards, how to expose or control that extra reasoning effort. The question now is what comes next. I believe the answer is agentic thinking: thinking in order to act, while interacting with an environment, and continuously updating plans based on feedback from the world.
1. What the Rise of o1 and R1 Actually Taught Us
The first wave of reasoning models taught us that if we want to scale reinforcement learning in language models, we need feedback signals that are deterministic, stable, and scalable. Math, code, logic, and other verifiable domains became central because rewards in these settings are much stronger than generic preference supervision. They let RL optimize for correctness rather than plausibility. Infrastructure became critical.
Once a model is trained to reason through longer trajectories, RL stops being a lightweight add-on to supervised fine-tuning. It becomes a systems problem. You need rollouts at scale, high-throughput verification, stable policy updates, efficient sampling. The emergence of reasoning models was as much an infra story as a modeling story. OpenAI described o1 as a reasoning line trained with RL, and DeepSeek R1 later reinforced that direction by showing how much dedicated algorithmic and infrastructure work reasoning-based RL demands. The first big transition: from scaling pretraining to scaling post-training for reasoning.
2. The Real Problem Was Never Just “Merge Thinking and Instruct”
At the beginning of 2025, many of us in Qwen team had an ambitious picture in mind. The ideal system would unify thinking and instruct modes. It would support adjustable reasoning effort, similar in spirit to low / medium / high reasoning settings. Better still, it would automatically infer the appropriate amount of reasoning from the prompt and context, so the model could decide when to answer immediately, when to think longer, and when to spend much more computation on a truly difficult problem.
Conceptually, this was the right direction. Qwen3 was one of the clearest public attempts. It introduced “hybrid thinking modes,” supported both thinking and non-thinking behavior in one family, emphasized controllable thinking budgets, and described a four-stage post-training pipeline that explicitly included “thinking mode fusion” after long-CoT cold start and reasoning RL.
But merging is much easier to describe than to execute well. The hard part is data. When people talk about merging thinking and instruct, they often think first about model-side compatibility: can one checkpoint support both modes, can one chat template switch between them, can one serving stack expose the right toggles. The deeper issue is that the data distributions and behavioral objectives of the two modes are substantially different.
We did not get everything right when trying to balance model merging with improving the quality and diversity of post-training data. During that revision process, we also paid close attention to how users were actually engaging with thinking and instruct modes. A strong instruct model is typically rewarded for directness, brevity, formatting compliance, low latency on repetitive, high-volume enterprise tasks such as rewriting, labeling, templated support, structured extraction, and operational QA. A strong thinking model is rewarded for spending more tokens on difficult problems, maintaining coherent intermediate structure, exploring alternative paths, and preserving enough internal computation to meaningfully improve final correctness.
These two behavior profiles pull against each other. If the merged data is not carefully curated, the result is usually mediocre in both directions: the “thinking” behavior becomes noisy, bloated, or insufficiently decisive, while the “instruct” behavior becomes less crisp, less reliable, and more expensive than what commercial users actually want.
Separation remained attractive in practice. Later in 2025, after the initial hybrid framing of Qwen3, the 2507 line shipped distinct Instruct and Thinking updates, including separate 30B and 235B variants. In commercial deployment, a large number of customers still wanted high-throughput, low-cost, highly steerable instruct behavior for batch operations. For those scenarios, merging wasn’t obviously a benefit. Separating the lines allowed teams to focus on solving the data and training problems of each mode more cleanly.
Other labs chose the opposite route. Anthropic publicly argued for an integrated model philosophy: Claude 3.7 Sonnet was introduced as a hybrid reasoning model where users could choose ordinary responses or extended thinking, and API users could set a thinking budget. Anthropic explicitly said they believed reasoning should be an integrated capability rather than a separate model. GLM-4.5 also publicly positioned itself as a hybrid reasoning model with both thinking and non-thinking modes, unifying reasoning, coding, and agent capabilities; DeepSeek later moved in a similar direction with V3.1’s “Think & Non-Think” hybrid inference.
The key question is whether the merge is organic. If thinking and instruct are merely co-located inside one checkpoint but still behave like two awkwardly stitched personalities, the product experience remains unnatural. A truly successful merge requires a smooth spectrum of reasoning effort. The model should be able to express multiple levels of effort, and ideally choose among them adaptively. GPT-style effort control points toward this: a policy over compute, rather than a binary switch.
3. Why Anthropic’s Direction Was a Useful Corrective
Anthropic’s public framing around Claude 3.7 and Claude 4 was restrained. They emphasized integrated reasoning, user-controlled thinking budgets, real-world tasks, coding quality, and later the ability to use tools during extended thinking. Claude 3.7 was presented as a hybrid reasoning model with controllable budgets; Claude 4 extended that by allowing reasoning to interleave with tool use, while Anthropic simultaneously emphasized coding, long-running tasks, and agent workflows as primary goals.
Producing a longer reasoning trace doesn’t automatically make a model more intelligent. In many cases, excessive visible reasoning signals weak allocation. If the model is trying to reason about everything in the same verbose way, it may be failing to prioritize, failing to compress, or failing to act. Anthropic’s trajectory suggested a more disciplined view: thinking should be shaped by the target workload. If the target is coding, then thinking should help with codebase navigation, planning, decomposition, error recovery, and tool orchestration. If the target is agent workflows, then thinking should improve execution quality over long horizons rather than producing impressive intermediate prose.
This emphasis on targeted utility points toward something larger: we are moving from the era of training models to the era of training agents. We made this explicit in the Qwen3 blog, writing that “we are transitioning from an era focused on training models to one centered on training agents,” and linking future RL advances to environmental feedback for long-horizon reasoning. An agent is a system that can formulate plans, decide when to act, use tools, perceive environment feedback, revise strategy, and continue over long horizons. It is defined by closed-loop interaction with the world.
4. What “Agentic Thinking” Really Means
Agentic thinking is a different optimization target. Reasoning thinking is usually judged by the quality of internal deliberation before a final answer: can the model solve the theorem, write the proof, produce the correct code, or pass the benchmark. Agentic thinking is about whether the model can keep making progress while interacting with an environment.
The central question shifts from “Can the model think long enough?” to “Can the model think in a way that sustains effective action?” Agentic thinking has to handle several things that pure reasoning models can mostly avoid:
- Deciding when to stop thinking and take an action
- Choosing which tool to invoke and in what order
- Incorporating noisy or partial observations from the environment
- Revising plans after failures
- Maintaining coherence across many turns and many tool calls
Agentic thinking is a model that reasons through action.
5. Why Agentic RL Infrastructure Is Harder
Once the objective shifts from solving benchmark problems to solving interactive tasks, the RL stack changes. The infrastructure used for classical reasoning RL isn’t enough. In reasoning RL, you can often treat rollouts as mostly self-contained trajectories with relatively clean evaluators. In agentic RL, the policy is embedded inside a larger harness: tool servers, browsers, terminals, search engines, simulators, execution sandboxes, API layers, memory systems, and orchestration frameworks. The environment is no longer a static verifier; it’s part of the training system.
This creates a new systems requirement: training and inference must be more cleanly decoupled. Without that decoupling, rollout throughput collapses. Consider a coding agent that must execute generated code against a live test harness: the inference side stalls waiting for execution feedback, the training side starves for completed trajectories, and the whole pipeline operates far below the GPU utilization you would expect from classical reasoning RL. Adding tool latency, partial observability, and stateful environments amplifies these inefficiencies. The result is that experimentation slows and becomes painful long before you reach the capability levels you are targeting.
The environment itself also becomes a first-class research artifact. In the SFT era, we obsessed over data diversity. In the agent era, we should obsess over environment quality: stability, realism, coverage, difficulty, diversity of states, richness of feedback, exploit resistance, and scalability of rollout generation. Environment-building has started to become a real startup category rather than a side project. If the agent is being trained to operate in production-like settings, then the environment is part of the core capability stack.
6. The Next Frontier Is More Usable Thought
My expectation is that agentic thinking will become the dominant form of thinking. I think it may eventually replace much of the old static-monologue version of reasoning thinking: excessively long, isolated internal traces that try to compensate for lack of interaction by emitting more and more text. Even on very difficult math or coding tasks, a genuinely advanced system should have the right to search, simulate, execute, inspect, verify, and revise. The objective is to solve problems robustly and productively.
The hardest challenge in training such systems is reward hacking. As soon as the model gets meaningful tool access, reward hacking becomes much more dangerous. A model with search might learn to look up answers directly during RL. A coding agent might exploit future information in a repository, misuse logs, or discover shortcuts that invalidate the task. An environment with hidden leaks can make the policy look superhuman while actually training it to cheat. This is where the agent era becomes much more delicate than the reasoning era. Better tools make the model more useful, but they also enlarge the attack surface for spurious optimization. We should expect the next serious research bottlenecks to come from environment design, evaluator robustness, anti-cheating protocols, and more principled interfaces between policy and world. Still, the direction is clear. Tool-enabled thinking is simply more useful than isolated thinking, and has a far better chance of improving real productivity.
Agentic thinking will also mean harness engineering. The core intelligence will increasingly come from how multiple agents are organized: an orchestrator that plans and routes work, specialized agents that act like domain experts, and sub-agents that execute narrower tasks while helping control context, avoid pollution, and preserve separation between different levels of reasoning. The future is a shift from training models to training agents, and from training agents to training systems.
Conclusion
The first phase of the reasoning wave established something important: RL on top of language models can produce qualitatively stronger cognition when the feedback signal is reliable and the infrastructure can support it.
The deeper transition is from reasoning thinking to agentic thinking: from thinking longer to thinking in order to act. The core object of training has shifted. It is the model-plus-environment system, or more concretely, the agent and the harness around it. That changes what research artifacts matter most: model architecture and training data, yes, but also environment design, rollout infrastructure, evaluator robustness, and the interfaces through which multiple agents coordinate. It changes what “good thinking” means: the most useful trace for sustaining action under real-world constraints, rather than the longest or most visible one.
It also changes where the competitive edge will come from. In the reasoning era, the edge came from better RL algorithms, stronger feedback signals, and more scalable training pipelines. In the agentic era, the edge will come from better environments, tighter train-serve integration, stronger harness engineering, and the ability to close the loop between a model’s decisions and the consequences those decisions produce.
背景
过去两年重塑了我们评估模型的方式以及我们对模型的期望。OpenAI的o1表明,“thinking”可以成为一项核心能力,可以通过训练并向用户展示。
DeepSeek-R1证明,reasoning式的后训练模型可以在原始实验室之外进行复现和扩展。OpenAI将o1描述为一个使用强化学习训练的模型,其特点是“先思考后回答”。DeepSeek则将R1定位为一个与o1相媲美的开放式reasoning模型。

那个阶段固然重要。但2025年上半年主要关注的是reasoning thinking:如何让模型投入更多时间进行推理计算,如何用更强的奖励来训练模型,以及如何展现或控制这些额外的推理工作。现在的问题是,接下来该做什么?我认为答案是agentic think:在与环境互动的同时进行thinking以采取行动,并根据来自外部世界的反馈不断更新计划。
1. OpenAI O1和DeepSeek R1的崛起究竟教会了我们什么
第一波reasoning模型告诉我们,如果想在语言模型中扩展强化学习,我们需要确定性、稳定性和可扩展性的反馈信号。数学、代码、逻辑和其他可验证领域变得至关重要,因为在这些领域中获得的奖励远比通用的偏好监督更有力。它们使强化学习能够优化正确性而非合理性。基础设施变得至关重要。
一旦模型训练完成,能够推理更长的轨迹,强化学习就不再是监督式微调的轻量级附加组件,而变成了一个系统性问题。
你需要大规模部署、高吞吐量验证、稳定的策略更新和高效的采样。推理模型的出现,既是建模本身的发展,也是基础设施建设的进步。
OpenAI将o1描述为使用强化学习训练的推理模型,而DeepSeek R1则进一步强化了这一方向,展示了基于推理的强化学习需要投入多少专门的算法和基础设施工作。
第一个重大转变:
从扩展预训练规模转向扩展后训练规模,以实现推理能力的提升。
2. 真正的问题从来不仅仅是“融合thinking和instruct”,混合思考
2025年初,Qwen团队的许多成员心中都怀揣着一个雄心勃勃的愿景。理想的系统将统一thinking模式和instruct模式,并支持可调节的推理难度,类似于低/中/高推理设置。
更进一步,它还能根据提示和上下文自动推断出合适的推理程度,从而让模型能够决定何时立即作答,何时需要更长时间的思考,以及何时需要投入更多计算资源来解决真正棘手的问题。
从概念上讲,这是正确的方向。Qwen3是最清晰的公开尝试之一。它引入了“混合思考模式”,支持同一类模型同时包含thinking行为和no thinking维行为,强调可控的think成本,并描述了一个四阶段的训练后流程,其中明确包含了在长时间冷启动和推理强化学习之后进行的“混合思考”。
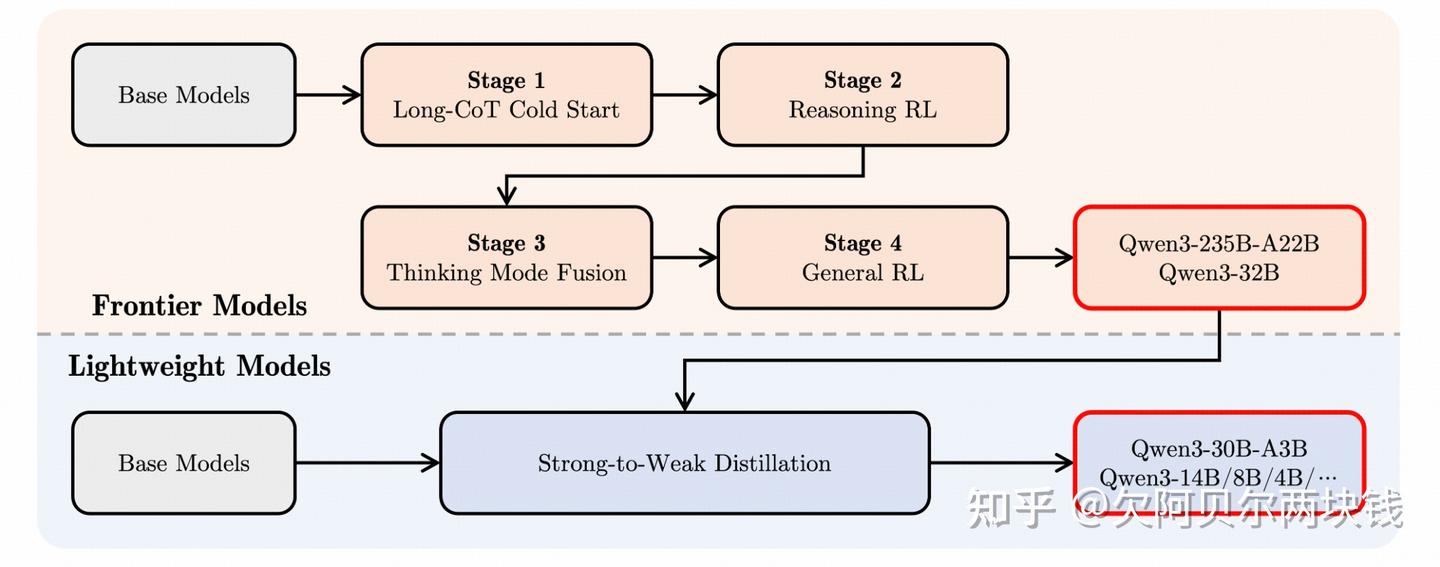
但描述合并远比真正执行要容易得多。难点在于数据。人们在谈论合并的思路和方法时,往往首先考虑的是模型层面的兼容性:
- 一个检查点能否同时支持两种模式
- 一个聊天模板能否在两种模式间切换
- 一个服务栈能否提供正确的切换开关。
但更深层次的问题在于,两种模式的数据分布和行为目标存在显著差异。
在尝试平衡模型合并与提升训练后数据的质量和多样性时,我们并非事事都能做到尽善尽美。在修订过程中,我们也密切关注用户实际如何使用think模式和instruct模式。
- 优秀的指令模型通常会因其直接性、简洁性、格式规范性以及在重复性、高容量的企业级任务(例如重写、标注、模板化支持、结构化提取和操作质量保证)上的低延迟而获得奖励。
- 优秀的思考模型则会因其在难题上投入更多资源、保持连贯的中间结构、探索替代路径以及保留足够的内部计算能力以显著提高最终正确率而获得奖励。
这两种行为模式相互制约。如果合并后的数据没有经过精心处理,结果通常会两方面都不尽如人意:“thinking”行为会变得冗长或不够果断,而“instruct”行为则会变得不够清晰、不可靠,并且比商业用户实际需要的成本更高。
在实践中,分离仍然具有吸引力。2025年晚些时候,在Qwen3最初的混合框架之后,2507产品线发布了独立的instruct模式和thinking模式更新,包括独立的30B和235B变体。
在商业部署中,大量客户仍然需要高吞吐量、低成本、高度可控的指令行为来处理批量操作。对于这些场景,合并显然没有优势。分离产品线使团队能够更清晰地专注于解决每种模式的数据和训练问题。
Anthropic选择了相反的路线
其他实验室则选择了相反的路线。Anthropic公开倡导一种集成模型理念:Claude 3.7 Sonnet被推出为一种混合推理模型,用户可以选择普通响应或扩展思考,API用户还可以设置思考预算。
Anthropic明确表示,他们认为推理应该是一种集成能力,而不是一个独立的模型。GLM-4.5也公开将自身定位为一种混合推理模型,它同时包含思考模式和非思考模式,统一了推理、编码和智能体能力;DeepSeek后来也朝着类似的方向发展,推出了V3.1的“Think & Non-Think”混合推理模型。
关键问题在于这种融合是否自然。如果thinking和instruct仅仅位于同一个checkpoint 内,却仍然像两个生硬组合的个体,那么产品体验仍然会显得不自然。
真正成功的融合需要一个平滑reasoning轨迹。模型应该能够自适应地进行选择计算策略。
3. 为什么Anthropic的发展方向是一种有效的纠正措施
Anthropic对Claude 3.7和Claude 4的公开宣传较为克制。他们强调集成推理、用户可控的思维预算、真实世界任务、编码质量,以及后来在扩展思考过程中使用工具的能力。
Claude 3.7被描述为一个具有可控预算的混合推理模型;Claude 4则在此基础上扩展,允许推理与工具使用交错进行。与此同时,Anthropic还强调编码、长时间运行的任务和智能体工作流程是其主要目标。
生成更长的推理轨迹并不会自动使模型更智能。在许多情况下,过多的可见推理表明资源分配不合理。如果模型试图以同样冗长的方式推理所有内容,则可能导致优先级排序失败、压缩失败或无法采取行动。
Anthropic的发展轨迹表明了一种更为严谨的观点:thinking应该根据目标工作负载来塑造。如果目标是coding,那么思维应该有助于代码库导航、规划、分解、错误恢复和工具编排。如果目标是智能体工作流,那么thinking应该着眼于提升长期执行质量,而不是生成令人印象深刻的中间文本。
这种对目标效用的强调指向一个更宏大的方向:我们正在从训练模型的时代迈向训练智能体的时代。我们在Qwen3博客中明确指出这一点,写道:“我们正在从一个以训练模型为中心的时代过渡到一个以训练智能体为中心的时代”,并将未来强化学习的进展与环境反馈联系起来,以实现长远推理。智能体是一个能够制定计划、决定何时行动、使用工具、感知环境反馈、修正策略并持续进行长远推理的系统。它的定义是与世界进行闭环交互。
4. “Agentic Thinking”的真正含义
Agentic thinking是另一种优化目标。Reasoning thinking通常以模型在得出最终答案前的内部thinking质量来评判:模型能否解决定理、写出证明、生成正确的代码或通过基准测试。而agentic thinking则关注模型在与环境交互的过程中能否持续进步。
核心问题从“模型能否thinking足够长的时间?”转变为“模型能否以能够维持有效行动的方式进行thinking?” agentic thinking必须处理一些纯reasoning模型大多可以避免的问题:
- 决定何时停止thinking并采取行动
- 选择要调用的工具以及调用顺序
- 接收来自环境的噪声或不完整的观测数据
- 失败后修改计划
- 在多次交互和多次工具调用中保持一致性
Agentic thinking是一种通过行动进行推理的模型。
5. 为什么Agentic RL基建更难构建
一旦目标从解决基准测试问题转向解决交互式任务,强化学习的架构就会发生变化。用于经典Reasoning RL的基础设施已不再适用。
在Reasoning RL中,通常可以将迭代过程视为相对独立的轨迹,并配备相对清晰的评估器。而在智能体强化学习中,poilcy 处于在一个更大的 harness(系统框架)内:工具服务器、浏览器、终端、搜索引擎、模拟器、执行沙箱、API层、内存系统和编排框架。环境不再是静态的验证器,而是训练系统的一部分。
这就产生了一个新的系统要求:训练和推理必须更彻底地解耦。如果没有这种解耦,部署吞吐量就会急剧下降。
试想一下,一个coding agent必须针对实时测试环境执行生成的代码:推理端会因为等待执行反馈而停滞,训练端会因为缺乏已完成的轨迹而停滞,整个流程的GPU利用率远低于传统推理强化学习的预期水平。工具延迟、部分可观测性和有状态环境的加入会加剧这些效率低下的问题。
最终结果是,在达到预期能力水平之前,实验就会变得缓慢而痛苦。
环境本身也成为一流的研究对象。在SFT时代,我们痴迷于数据多样性。在智能体时代,我们应该关注环境质量:稳定性、真实性、覆盖范围、难度、状态多样性、反馈丰富性、抗攻击性以及部署生成的可扩展性。环境构建已逐渐成为一个真正的创业领域,而不再是业余项目。如果智能体被训练用于在类似生产环境的场景中运行,那么环境就是其核心能力的一部分。
6. 下一个前沿领域是更实用的思考
我预期agentic thinking将成为主流思维模式。我认为它最终可能会取代之前的的静态 独白式的reasoning thinking:冗长 独立的内部逻辑试图通过输出越来越多的文本来弥补交互的缺失。
即使是面对极其复杂的数学或编程任务,一个真正先进的系统也应该有权进行搜索、模拟、执行、检查、验证和修改。其目标是稳健高效地解决问题。
训练此类系统的最大挑战在于奖励机制的破解。一旦模型获得有效的工具访问权限,奖励机制的破解就会变得更加危险。例如,具备搜索功能的模型可能会在强化学习过程中直接查找答案。codint agent可能会利用存储库中的未来信息、滥用日志,或者发现使任务无效的捷径。
一个存在隐藏漏洞的环境可以让策略看起来超乎常人,而实际上是奖励作弊。正因如此,智能体时代比推理时代更加复杂。更强大的工具固然能提升模型的效用,但也扩大了虚假优化的攻击面。我们应该预见,下一个重要的研究瓶颈将来自环境设计、评估器的鲁棒性、反作弊协议以及策略与世界之间更合理的接口。尽管如此,方向依然明确:工具辅助的思考方式远比没有任何的思考方式更有用,也更有可能提高实际生产力。
Agentic thinking也意味着对框架工程(harness engineering)的驾驭。核心智能将日益来源于多个智能体的组织方式:一个负责Planning和分配工作的协调器,一些扮演领域专家角色的专业智能体,以及一些执行更具体任务的sub-agents,它们在执行任务的同时,还有助于控制上下文、避免信息污染,并保持不同推理层次之间的分离。未来将从训练模型转向训练智能体,再从训练智能体转向训练系统。
结论
reasoning浪潮的第一阶段确立了一些重要的东西:当反馈信号可靠且基础设施能够支持时,基于语言模型的强化学习可以产生质量上更强的认知能力。
更深层次的转变是从reasoning thinking向agentic thinking的转变:从思考更长远到思考以采取行动。训练的核心对象也发生了变化。它变成了模型加环境系统,更具体地说,是智能体及其周围的组件。
这改变了最重要的研究成果:模型架构和训练数据固然重要,但环境设计、部署基础设施、评估器的鲁棒性以及多个智能体协调的接口也同样重要。它改变了“好的思考”的含义:在现实世界的约束下,最能有效维持行动的思考轨迹,而非最长或最显眼的思考轨迹。
这也改变了竞争优势的来源。在reasoning时代,优势来自更优秀的强化学习算法、更强大的反馈信号和更具可扩展性的训练流程。在智能体时代,优势将来自更优的训练环境、更紧密的训练-服务集成、更强大的模型工程,以及将模型决策与其后果之间形成闭环的能力。