Flink基础理论
文章目录
- Flink概述
- Flink生态
- 为什么选择Flink?
- 系统架构
- 运行架构
- 核心原理
- Flink部署与运行
- Storm、Spark-Streaming和Flink对比
- Demo演示(SocketTextStreamWordCount)
- Fink-Startup
- 参考
Flink概述
Apache Flink是一个计算框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。其针对数据流的分布式计算提供了数据分布、数据通信以及容错机制等功能。基于流执行引擎,Flink提供了诸多更高抽象层的API以便用户编写分布式任务:
- DataSet API, 对静态数据进行批处理操作,将静态数据抽象成分布式的数据集,用户可以方便地使用Flink提供的各种操作符对分布式数据集进行处理,支持Java、Scala和Python。
- DataStream API,对数据流进行流处理操作,将流式的数据抽象成分布式的数据流,用户可以方便地对分布式数据流进行各种操作,支持Java和Scala。
- Table API,对结构化数据进行查询操作,将结构化数据抽象成关系表,并通过类SQL的DSL对关系表进行各种查询操作,支持Java和Scala。
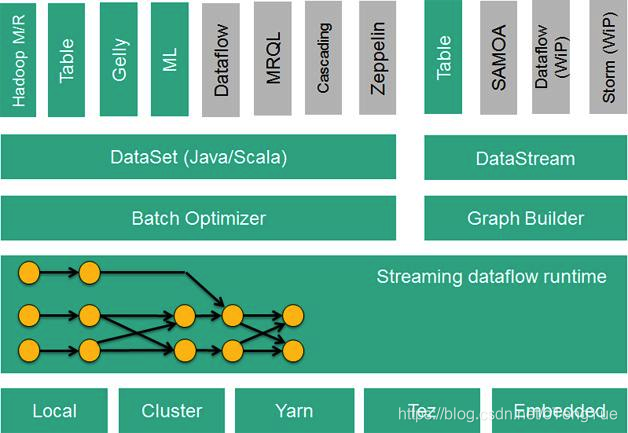
从部署上讲,Flink支持local模式、集群模式(standalone集群或者Yarn集群)、云端部署。Runtime是主要的数据处理引擎,它以JobGraph形式的API接收程序,JobGraph是一个简单的并行数据流,包含一系列的tasks,每个task包含了输入和输出(source和sink例外)。
Flink生态
为什么选择Flink?

系统架构
Flink分布式程序包含2个主要的进程:JobManager和TaskManager.当程序运行时,不同的进程就会参与其中,包括Jobmanager、TaskManager和JobClient。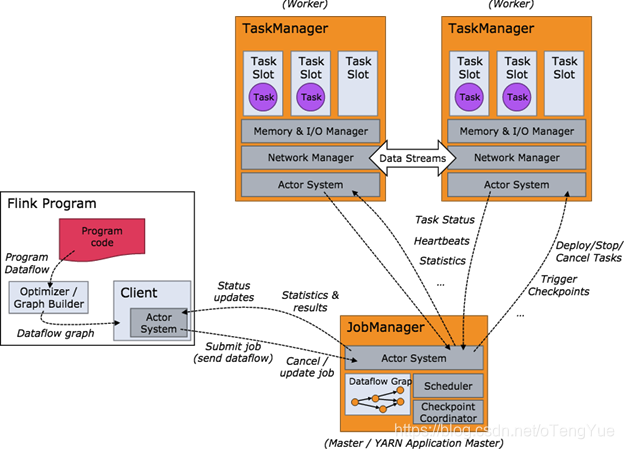
当 Flink 集群启动后,首先会启动一个 JobManger 和一个或多个的 TaskManager。由 Client 提交任务给 JobManager,JobManager 再调度任务到各个 TaskManager 去执行,然后 TaskManager 将心跳和统计信息汇报给 JobManager。TaskManager 之间以流的形式进行数据的传输。上述三者均为独立的 JVM 进程。
JobManager
Master进程,负责Job的管理和资源的协调。包括任务调度,检查点管理,失败恢复等。
当然,对于集群HA模式,可以同时多个master进程,其中一个作为leader,其他作为standby。当leader失败时,会选出一个standby的master作为新的leader(通过zookeeper实现leader选举)。
JobManager包含了3个重要的组件:
###(1)Actor系统
Flink内部使用Akka模型作为JobManager和TaskManager之间的通信机制。
Actor系统是个容器,包含许多不同的Actor,这些Actor扮演者不同的角色。Actor系统提供类似于调度、配置、日志等服务,同时包含了所有actors初始化时的线程池。
所有的Actors存在着层级的关系。新加入的Actor会被分配一个父类的Actor。Actors之间的通信采用一个消息系统,每个Actor都有一个“邮箱”,用于读取消息。如果Actors是本地的,则消息在共享内存中共享;如果Actors是远程的,则消息通过RPC远程调用。
每个父类的Actor都负责监控其子类Actor,当子类Actor出现错误时,自己先尝试重启并修复错误;如果子类Actor不能修复,则将问题升级并由父类Actor处理。
在Flink中,actor是一个有状态和行为的容器。Actor的线程持续的处理从“邮箱”中接收到的消息。Actor中的状态和行为则由收到的消息决定。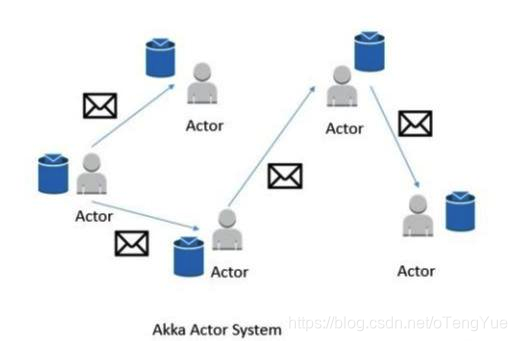
###(2)调度
Flink中的Executors被定义为task slots(线程槽位)。每个Task Manager需要管理一个或多个task slots。
Flink通过SlotSharingGroup和CoLocationGroup来决定哪些task需要被共享,哪些task需要被单独的slot使用。
###(3)检查点
Flink的检查点机制是保证其一致性容错功能的骨架。它持续的为分布式的数据流和有状态的operator生成一致性的快照。Flink的容错机制持续的构建轻量级的分布式快照,因此负载非常低。通常这些有状态的快照都被放在HDFS中存储(state backend)。程序一旦失败,Flink将停止executor并从最近的完成了的检查点开始恢复(依赖可重发的数据源+快照)。
运行架构
常用的类型和操作
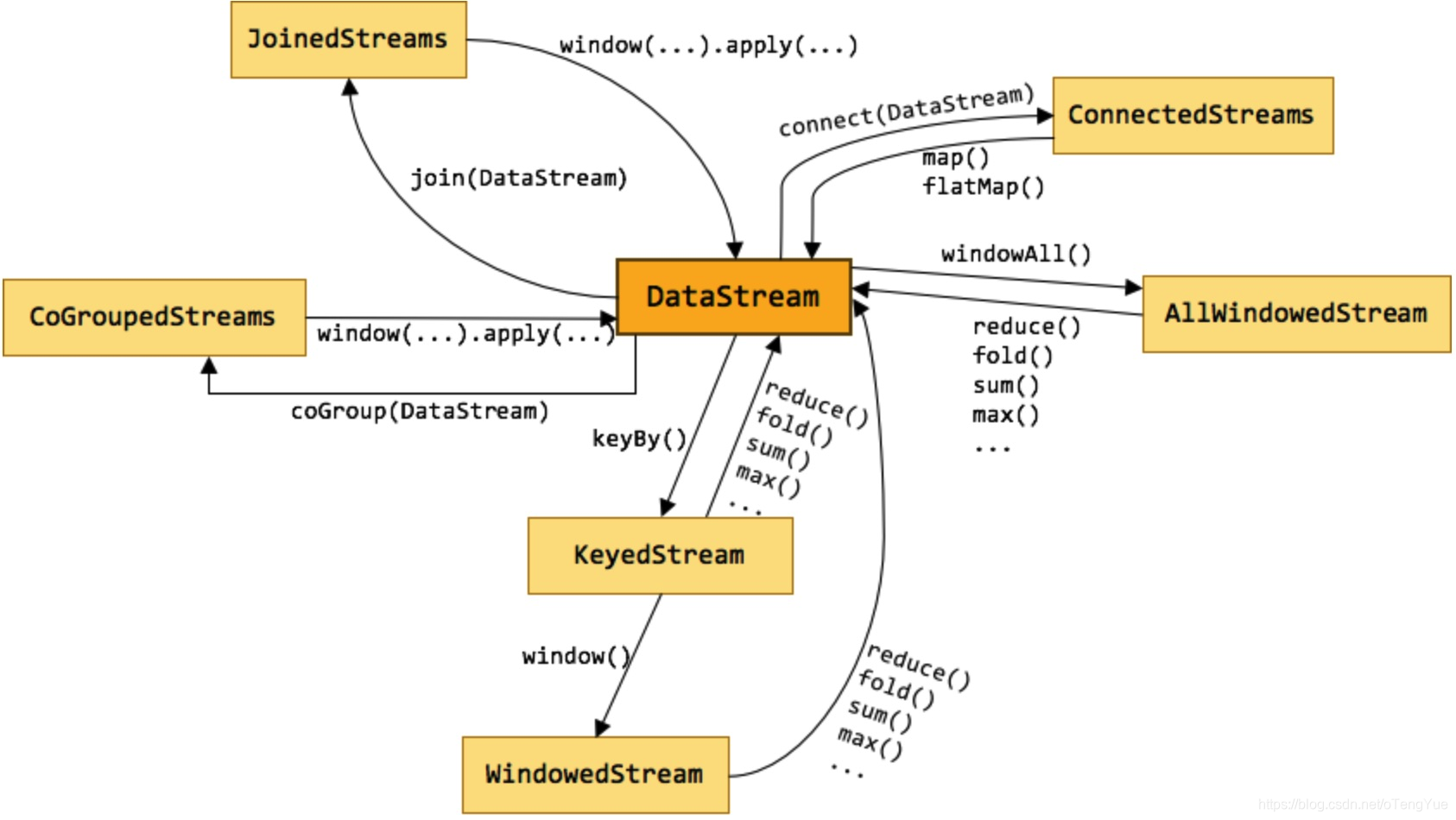
参考:
Flink 原理与实现:数据流上的类型和操作:http://wuchong.me/blog/2016/05/20/flink-internals-streams-and-operations-on-streams
Flink Stream 算子:https://flink.sojb.cn/dev/stream/operators
程序结构介绍
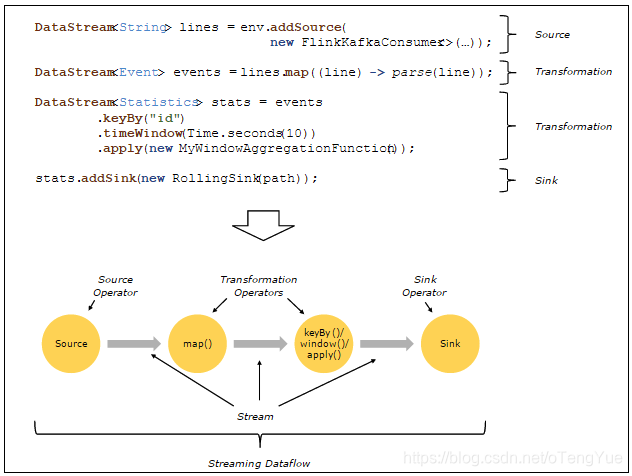
Source,它是整个stream的入口。
Transformation,用于转换一个或多个DataStream从而形成一个新的DataStream对象。
Sink,它流的数据出口。
并行数据流
Flink程序本质上是并行和分布式的。在程序执行期间,一个流会生成一个或者多个stream partition,并且一个operator会生成一个或者多个operator subtask。operator的 subtask 彼此之间是独立的,分别在不同的线程里去执行并且可能分布在不同的机器上或者containers上。
operator的subtasks的数量等于该操作算子的并行度的数量。流的并行度有总是取决于产生它的操作算子的并行度决定的。同一个flink程序中的不同的operators可能有不同的并行度。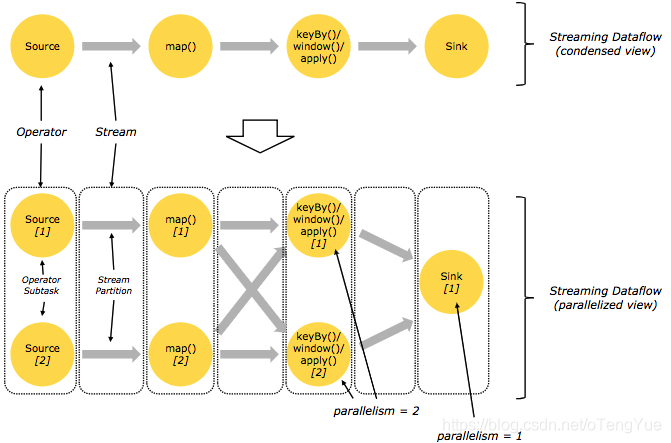
数据流在两个operators之间进行传递的方式有两种:one-to-one 模式 和 redistributing 模式
- one-to-one 模式
两个operator用此模式传递的时候,会保持数据的分区数和数据的排序,比如:在下图中Source和map() operators之间的数据传递方式; - Redistributing 模式(重新分配模式)
这种模式会改变数据的分区数;每个一个operator subtask会根据选择transformation把数据发送到不同的目标subtasks,比如keyBy()会通过hashcode重新分区,broadcast()和rebalance()方法会随机重新分区,比如:在下图中map()和keyBy/window ,keyBy/window和Sink之间的数据传递方式;
Flink每个算子都可以设置并行度,然后就是也可以设置全局并行度。
api设置.map(new RollingAdditionMapper()).setParallelism(10)
全局配置在flink-conf.yaml文件中,parallelism.default,默认是1
Task and Operator Chains
为了更高效地分布式执行,Flink会尽可能地将operator的subtask链接(chain)在一起形成task。每个task在一个线程中执行。将operators链接成task是非常有效的优化:它能减少线程之间的切换,减少消息的序列化/反序列化,减少数据在缓冲区的交换,减少了延迟的同时提高整体的吞吐量。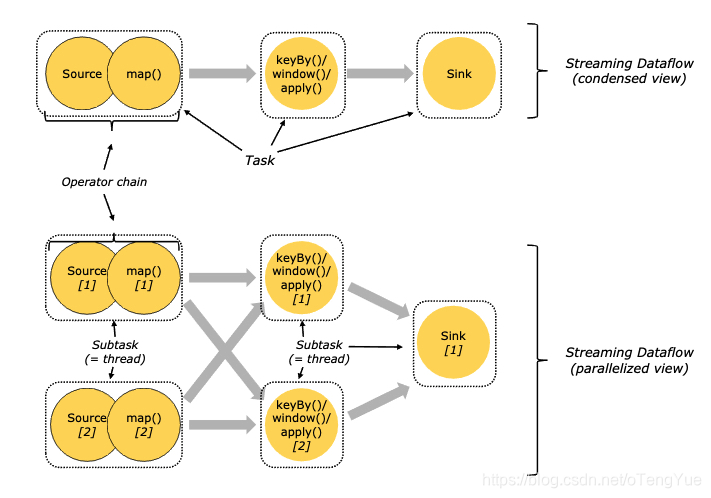
可以进行Operator chains的条件
1、上下游的并行度一致
2、下游节点的入度为1 (也就是说下游节点没有来自其他节点的输入)
3、上下游节点都在同一个 slot group 中(下面会解释 slot group)
4、下游节点的 chain 策略为 ALWAYS(可以与上下游链接,map、flatmap、filter等默认是ALWAYS)
5、上游节点的 chain 策略为 ALWAYS 或 HEAD(只能与下游链接,不能与上游链接,Source默认是HEAD)
6、两个节点间数据分区方式是 forward(参考理解数据流的分区)
7、用户没有禁用 chain
核心原理
Apache Flink 之所以能越来越受欢迎,我们认为离不开它最重要的四个基石:Checkpoint、State、Time、Window。
Window&Time
Window
Flink 中 Window 可以将无限流切分成有限流,是处理有限流的核心组件,现在Flink 中 Window 可以是时间驱动的(Time Window),也可以是数据驱动的(Count Window),如下图所示: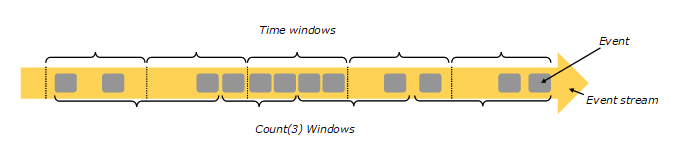
上图中,基于时间的窗口操作,在每个相同的时间间隔对Stream中的记录进行处理,通常各个时间间隔内的窗口操作处理的记录数不固定;而基于数据驱动的窗口操作,可以在Stream中选择固定数量的记录作为一个窗口,对该窗口中的记录进行处理。
窗口类型:
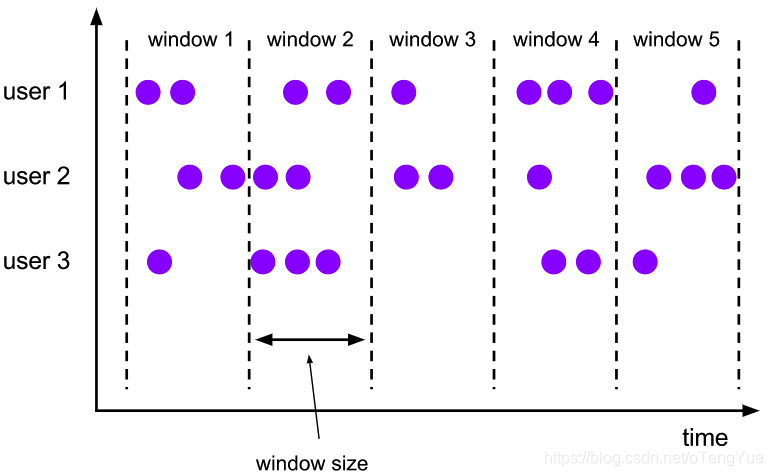
- tumbling window(滚动窗口):窗口间的元素无重复
一个翻滚窗口分配器的每个数据元分配给指定的窗口的窗口大小。翻滚窗具有固定的尺寸,不重叠。例如,如果指定大小为5分钟的翻滚窗口,则将评估当前窗口,并且每五分钟将启动一个新窗口
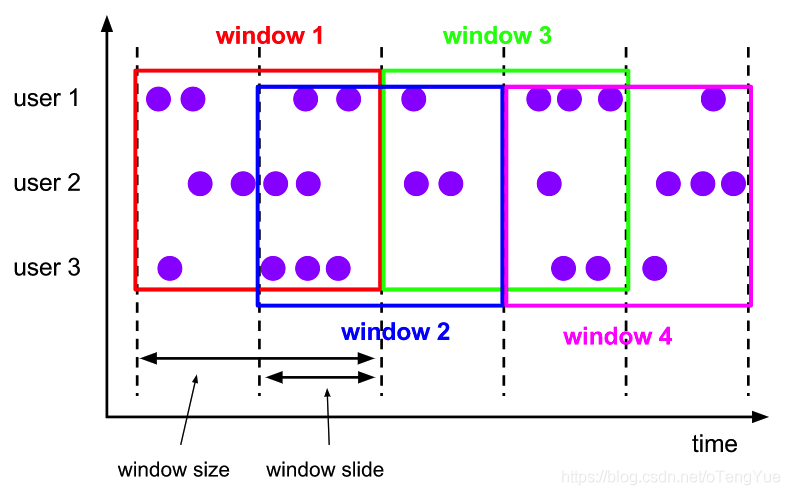
- sliding window(滑动窗口):窗口间的元素可能重复
该滑动窗口分配器分配元件以固定长度的窗口。与翻滚窗口分配器类似,窗口大小由窗口大小参数配置。附加的窗口滑动参数控制滑动窗口的启动频率。因此,如果幻灯片小于窗口大小,则滑动窗口可以重叠。在这种情况下,数据元被分配给多个窗口。
例如,您可以将大小为10分钟的窗口滑动5分钟。有了这个,你每隔5分钟就会得到一个窗口,其中包含过去10分钟内到达的事件
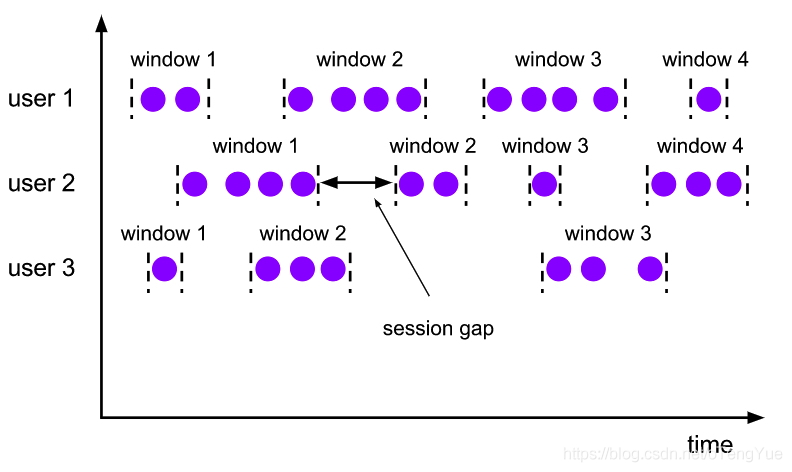
- session window(会话窗口)
在会话窗口中按活动会话分配器组中的数据元。与翻滚窗口和滑动窗口相比,会话窗口不重叠并且没有固定的开始和结束时间。相反,当会话窗口在一段时间内没有接收到数据元时,即当发生不活动的间隙时,会关闭会话窗口。会话窗口分配器可以配置静态会话间隙或 会话间隙提取器函数,该函数定义不活动时间段的长度。当此期限到期时,当前会话将关闭,后续数据元将分配给新的会话窗口。
- global window(全局窗口)
一个全局性的窗口分配器分配使用相同的Keys相同的单个的所有数据元全局窗口。此窗口方案仅在您还指定自定义触发器时才有用。否则,将不执行任何计算,因为全局窗口没有我们可以处理聚合数据元的自然结束。
参考:
window:http://flink.iteblog.com/dev/windows.html

Time
Time的分类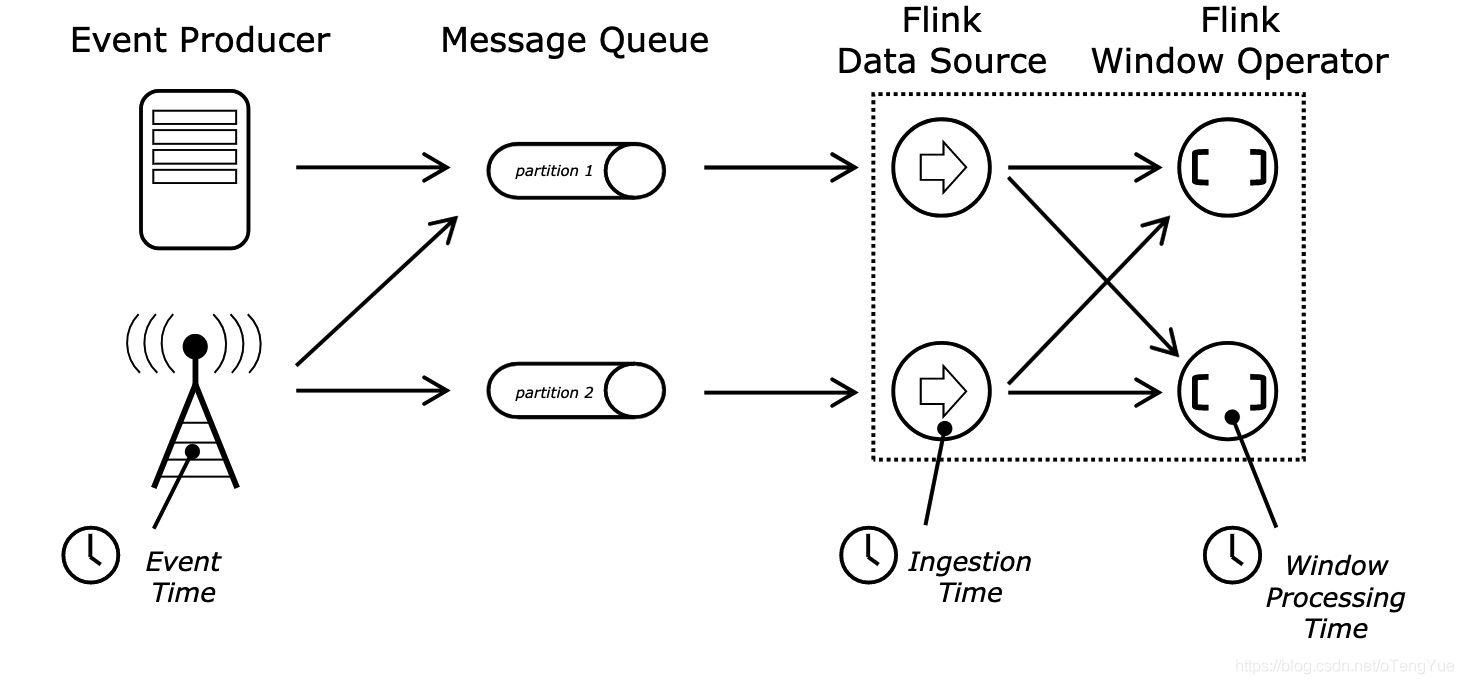
- Event-Time :事件时间是每个事件在其生产设备上发生的时间。此时间通常在进入Flink之前嵌入记录中,并且 可以从每个记录中提取该事件时间戳。
- Ingestion-Time :摄取时间是事件进入Flink的时间。在源算子处,每个记录将源的当前时间作为时间戳,并且基于时间的 算子操作(如时间窗口)引用该时间戳。
- Processing-Time : 处理时间是指执行相应算子操作的机器的系统时间。
引入Watermark的背景?
主要解决延迟数据
我们可以考虑一个这样的例子:某 App 会记录用户的所有点击行为,并回传日志(在网络不好的情况下,先保存在本地,延后回传)。A 用户在 11:02 对 App 进行操作,B 用户在 11:03 操作了 App,但是 A 用户的网络不太稳定,回传日志延迟了,导致我们在服务端先接受到 B 用户 11:03 的消息,然后再接受到 A 用户 11:02 的消息,消息乱序了。
那我们怎么保证基于 event-time 的窗口在销毁的时候,已经处理完了所有的数据呢?这就是 watermark 的功能所在。watermark 会携带一个单调递增的时间戳 t,watermark(t) 表示所有时间戳不大于 t 的数据都已经到来了,未来不会再来,因此可以放心的触发和销毁窗口了。
什么是Watermark?
Watermark是Apache Flink为了处理EventTime 窗口计算提出的一种机制,本质上也是一种时间戳,由Apache Flink Source或者自定义的Watermark生成器按照需求Punctuated或者Periodic两种方式生成的一种系统Event,与普通数据流Event一样流转到对应的下游算子,接收到Watermark Event的算子以此不断调整自己管理的EventTime clock。
乱序流中Watermark的工作示意图: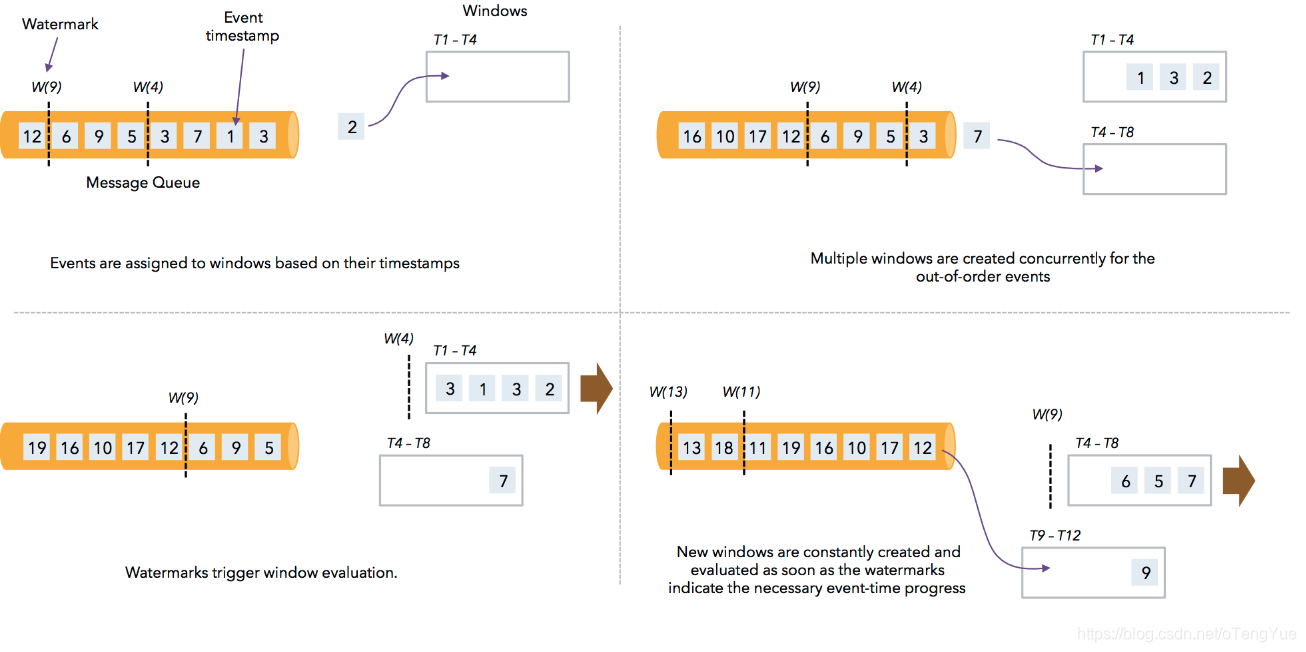
并行流中的Watermarks的工作示意图: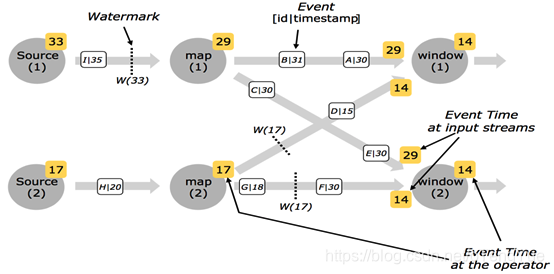
多并行度的情况下,watermark对齐会取所有channel最小的watermark。
例如:多输入operator(union、 keyBy、 partition)的当前event time是其输入流event time的最小值。
设置Time类型
不设置Time 类型,默认是processingTime。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
如果使用EventTime则需要在source之后明确指定Timestamp Assigner & Watermark Generator
Watermark的产生方式:
- Punctuated – 数据流中每一个递增的EventTime都会产生一个Watermark。在实际的生产中Punctuated方式在TPS很高的场景下会产生大量的Watermark在一定程度上对下游算子造成压力,所以只有在实时性要求非常高的场景才会选择Punctuated的方式进行Watermark的生成。
接口定义AssignerWithPunctuatedWatermarks:Watermark checkAndGetNextWatermark(T lastElement, long extractedTimestamp); - Periodic – 周期性的(一定时间间隔或者达到一定的记录条数)产生一个Watermark。在实际的生产中Periodic的方式必须结合时间和积累条数两个维度继续周期性产生Watermark,否则在极端情况下会有很大的延时。
接口定义AssignerWithPeriodicWatermarks:Watermark getCurrentWatermark();
Watermark触发计算时间:
在基于 Event-Time 的流处理应用中,每个数据有两个必需的信息:
- 时间戳:事件发生的时间
- Watermark:算子通过Watermark推断当前的事件时间。Watermark用于通知算子没有比水位更小的时间戳的事件会发生了。
基于时间的窗口会根据事件时间将一个数据分配给某个窗口。每个时间窗口都有一个 开始时间戳 和 结束时间戳 。
所有内置的窗口分配器都会提供一个默认的触发器,一旦时间超过某个窗口的结束时间,触发器就会触发对这个窗口的计算。
触发过程见示例:https://juejin.im/post/5bf95810e51d452d705fef33
参考:
event-time:https://flink.sojb.cn/dev/event_time.html
flink watermark的原理和实践:https://www.jianshu.com/p/7d524ef8143c
Flink学习笔记:Time的故事:https://www.cnblogs.com/dajiangtai/p/10697318.html
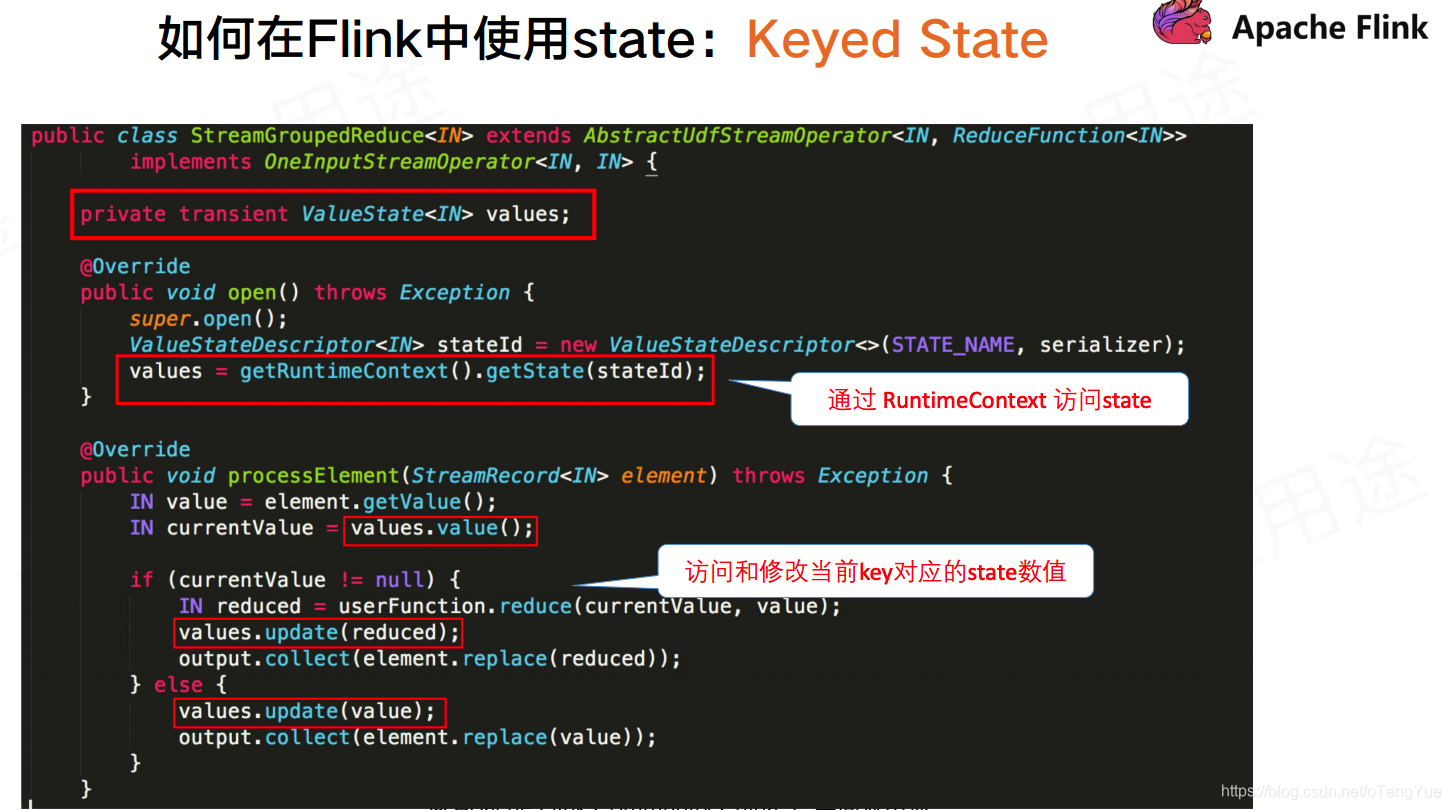
State状态管理
State是指流计算过程中计算节点的中间计算结果或元数据属性,比如 在aggregation过程中要在state中记录中间聚合结果,比如 Apache Kafka 作为数据源时候,我们也要记录已经读取记录的offset,这些State数据在计算过程中会进行持久化(插入或更新)。所以Apache Flink中的State就是与时间相关的,Apache Flink任务的内部数据(计算数据和元数据属性)的快照。
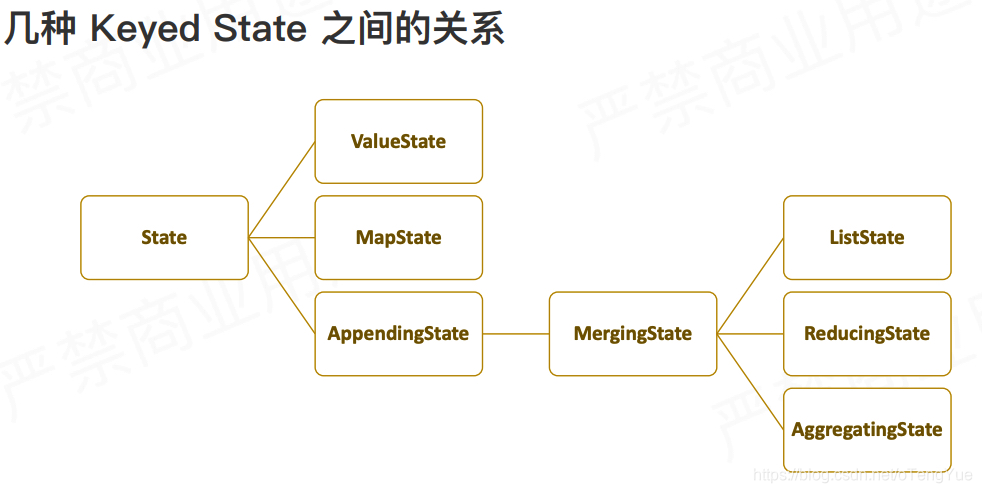
按组织形式的划分
- Managed State,这类State的内部结构完全由Flink runtime内部来控制,包括如何将它们编码写入到checkpoint中等等。
- Raw State,这类State就比较显得灵活一些,它们被保留在操作运行实例内部的数据结构中。从Flink系统角度来观察,在checkpoint时,它只知道的是这些状态数据是以连续字节的形式被写入checkpoint中。等待进行状态恢复时,又从字节数据反序列化为状态对象。
Managed State可以在所有的data stream相关方法中被使用,官方也是推荐优先使用这类State,因为它能被Flink runtime内部做自动重分布而且能被更好地进行内存管理。
按照数据的划分和扩张方式


参考:
Apache Flink 漫谈系列 – State:https://www.codercto.com/a/32411.html
Flink 的状态管理和检查点机制:http://blog.jrwang.me/2017/flink-state-checkpoint
Checkpoint容错机制
Checkpoint是Flink实现容错机制最核心的功能,它能够根据配置周期性地基于Stream中各个Operator/task的状态来生成一个轻量级的分布式快照,从而将这些状态数据定期持久化存储下来,当Flink程序一旦意外崩溃时,重新运行程序时可以有选择地从这些快照进行恢复,从而修正因为故障带来的程序数据异常。
默认情况下,检查点不会保存,仅用于从失败中恢复作业。取消程序时会删除它们。但是,您可以配置要保存的定期检查点。根据配置 ,当作业失败或取消时,不会自动清除这些保存的检查点。这样,如果您的工作失败,您将有一个检查点可以从中恢复。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(1000);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
env.getCheckpointConfig().setCheckpointTimeout(60000);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
Flink的失败恢复依赖于“检查点机制+可部分重发的数据源”。
Flink 实现了一个轻量级的分布式快照机制,其核心点在于 Barrier。 Coordinator 在需要触发检查点的时候要求数据源注入向数据流中注入 barrie, barrier 和正常的数据流中的消息一起向前流动,相当于将数据流中的消息切分到了不同的检查点中。当一个 operator 从它所有的 input channel 中都收到了 barrier,则会触发当前 operator 的快照操作,并向其下游 channel 中发射 barrier。当所有的 sink 都反馈收到了 barrier 后,则当前检查点创建完毕。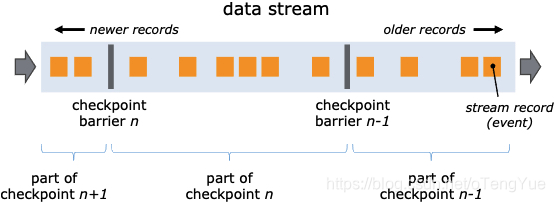
在此过程中会涉及到对齐操作,一些 operator 拥有多个 input channel,它往往不会同时从这些 channel 中接收到 barrier。如果 Operator 继续处理 barrier 先到达的 channel 中的消息,那么在所有 channel 的 barrier 都到达时,operator 就会处于一种混杂的状态。在这种情况下,Flink 采用对齐操作来保证 Exactly Once 特性。Operator 会阻塞 barrier 先到达的 channel,通常是将其流入的消息放入缓冲区中,待收到所有 input channel 的 barrier 后,进行快照操作,释放被阻塞的 channel,并向下游发射 barrier。
Barries 对齐过程:
(1). 一旦operator从输入流接收到快照barrier n,它就不能处理来自该流的任何其他记录,直到它从其他输入接收到barrier n为止。 否则,它会混合属于快照n的记录和属于快照n + 1的记录。
(2). 包含barrier n的流数据暂时被Operator搁置。 从这些流接收的记录不会被处理,而是放入输入缓冲区。
(3). 一旦最后一个流接收到屏障n,Operator就会向下一个Operator发出所有挂起的流数据,然后自己发出快照n个屏障。
(4). 之后,它将继续处理来自所有输入流的记录,在处理来自流的记录之前,会优先处理来自输入缓冲区的记录。
对齐操作会对流处理造成延时,但通常不会特别明显。如果应用对一致性要求比较宽泛的话,那么也可以选择跳过对齐操作。这意味着快照中会包含一些属于下一个检查点的数据,这样就不能保证 Exactly Once 特性,而只能降级为 At Least Once。
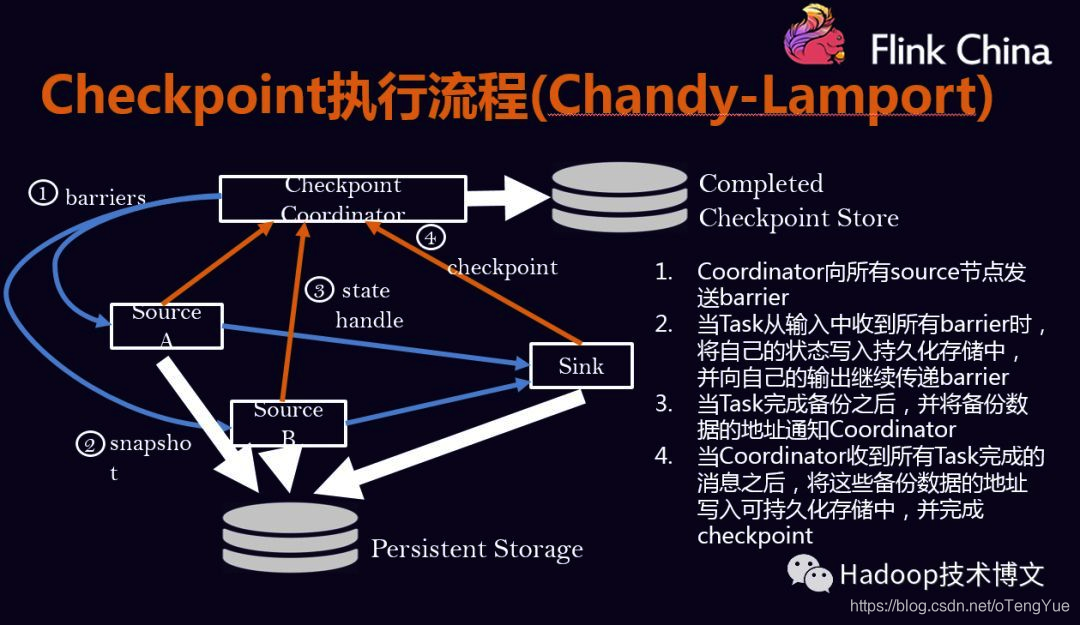
Checkpoint的执行流程:
Checkpoint的执行流程是按照Chandy-Lamport算法实现的。
后端状态存储方式
在有状态的流处理中,当开发人员启用了 Flink 中的 checkpoint 机制,那么状态将会持久化以防止数据的丢失并确保发生故障时能够完全恢复。选择何种状态后端,将决定状态持久化的方式和位置。
Flink 提供了三种可用的状态后端:MemoryStateBackend、FsStateBackend和RocksDBStateBackend。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new FsStateBackend("hdfs://namenode:40010/flink/checkpoints"));



参考:
如何选择状态后端:http://wuchong.me/blog/2018/11/21/flink-tips-how-to-choose-state-backends
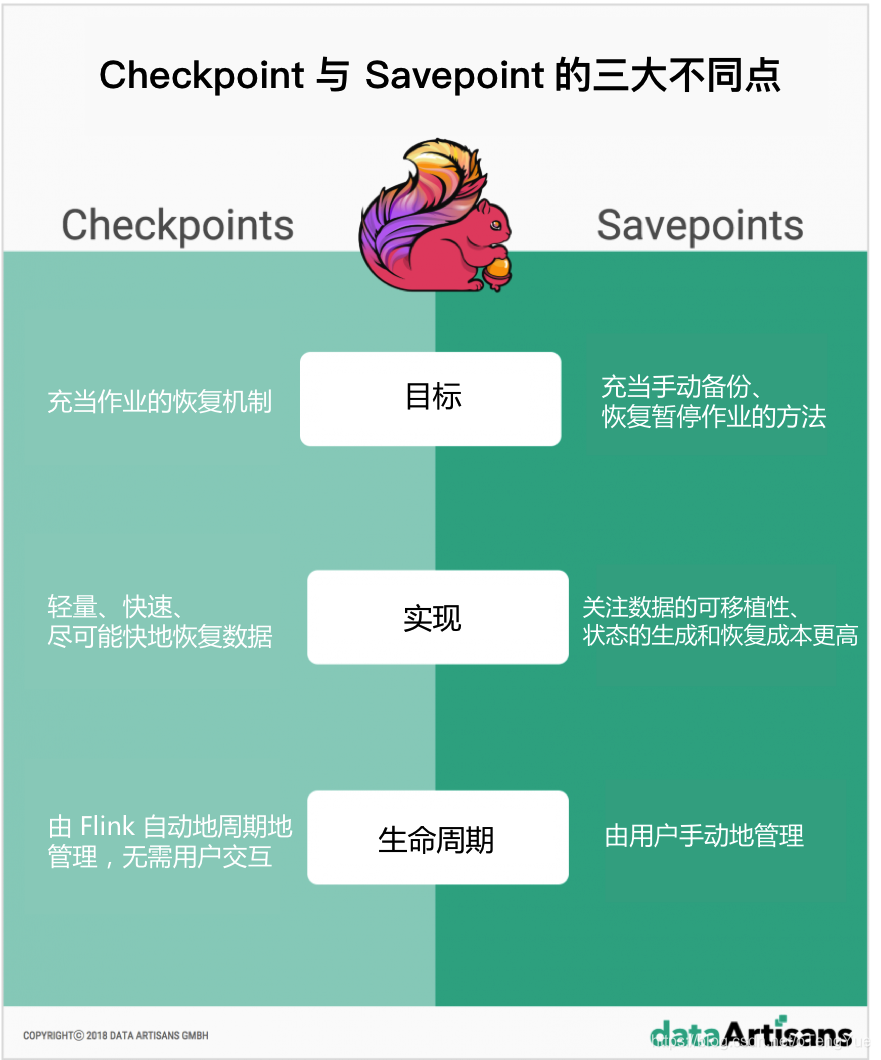
Savepoint保存点
Savepoint 是命令触发的 Checkpoint,对流式程序做一次完整的快照并将结果写到 State backend,可用于停止、恢复或更新 Flink 程序。整个过程依赖于 Checkpoint 机制。另一个不同之处是,Savepoint 不会自动清除。
分配算子ID
Savepoint 中会以 Operator ID 作为 key 保存每个有状态算子的状态。
Operator ID 用于确定每个算子的状态,只要ID不变,就可以从 Savepoint 中恢复,Operator ID 如果不显示指定会自动生成,生成的ID取决于程序的结构,并且对程序更改很敏感。
DataStream<String> stream = env.
// Stateful source (e.g. Kafka) with ID
.addSource(new StatefulSource())
.uid("source-id") // ID for the source operator
.shuffle()
// Stateful mapper with ID
.map(new StatefulMapper())
.uid("mapper-id") // ID for the mapper
// Stateless printing sink
.print(); // Auto-generated ID
Savepoint 包含了两个主要元素:
- 1、首先,Savepoint 包含了一个目录,其中包含(通常很大的)二进制文件,这些文件表示了整个流应用在 Checkpoint/Savepoint 时的状态。
- 2、以及一个(相对较小的)元数据文件,包含了指向 Savapoint 各个文件的指针,并存储在所选的分布式文件系统或数据存储中。
何时使用 Savepoint ?
虽然流式应用程序处理的数据是持续地生成的(“运动中”的数据),但是存在着想要重新处理之前已经处理过的数据的情况。Savepoint 可以在以下情况下使用:
- 部署流应用的一个新版本,包括新功能、BUG 修复、或者一个更好的机器学习模型
- 引入 A/B 测试,使用相同的源数据测试程序的不同版本,从同一时间点开始测试而不牺牲先前的状态
- 在需要更多资源时扩容应用程序
- 迁移流应用程序到 Flink 的新版本上,或者迁移到另一个集群
如何使用?
savepoint是有用户手动管理的,常用操作包含:
- 保存Savepoint
$ bin/flink savepoint :jobId [:targetDirectory]
这将触发具有ID的作业的保存点:jobId,并返回创建的保存点的路径。您需要此路径来还原和部署保存点。 - 在yarn 集群中保存Savepoint
$ bin/flink savepoint :jobId [:targetDirectory] -yid :yarnAppId
这将触发具有ID :jobId和YARN应用程序ID 的作业的保存点:yarnAppId,并返回创建的保存点的路径。 - 使用 Savepoint 取消job
$ bin/flink cancel -s [:targetDirectory] :jobId
这将以原子方式触发具有ID的作业的保存点:jobid并取消作业。此外,您可以指定目标文件系统目录以存储保存点。该目录需要可由JobManager和TaskManager访问。 - Resuming Savepoint
$ bin/flink run -s :savepointPath [:runArgs]
这将提交作业并指定要从中恢复的保存点。您可以指定保存点目录或_metadata文件的路径。 - 允许未恢复状态启动
$ bin/flink run -s :savepointPath -n [:runArgs]
默认情况下,resume操作将尝试将保存点的所有状态映射回要恢复的程序。如果删除了运算符,则可以通过–allowNonRestoredState(short -n:)选项跳过无法映射到新程序的状态
- 删除Savepoint
$ bin/flink savepoint -d :savepointPath
通过指定路径删除 Savepoint,也可以通过文件系统手动删除 Savepoint 数据,而不会影响其他 Savepoint 或 Checkpoint。
Savepoint 和 Checkpoint
参考:
Savepoint 和 Checkpoint 的 3 个不同点:http://wuchong.me/blog/2018/11/25/flink-tips-differences-between-savepoints-and-checkpoints/
Flink 专题 -2 Checkpoint、Savepoint 机制:https://yq.aliyun.com/articles/665758?spm=a2c4e.11153940.0.0.143e64c01hVKeN
Flink部署与运行
Yarn运行Flink作业
link支持多种部署模式:本地、集群(Standalone/YARN)、云(GCE/EC2)。Standalone部署模式与Spark类似,这里,我们看一下Flink on YARN的部署模式,如下图所示: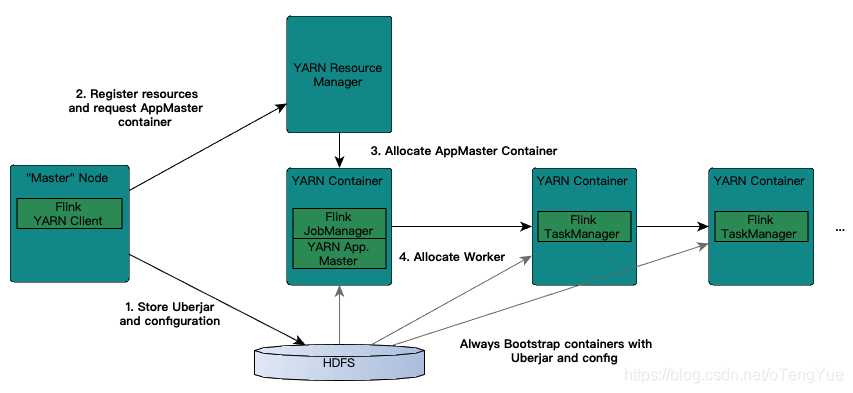
实际Flink也实现了满足在YARN集群上运行的各个组件:Flink YARN Client负责与YARN RM通信协商资源请求,Flink JobManager和Flink TaskManager分别申请到Container去运行各自的进程。通过上图可以看到,YARN AM与Flink JobManager在同一个Container中,这样AM可以知道Flink JobManager的地址,从而AM可以申请Container去启动Flink TaskManager。待Flink成功运行在YARN集群上,Flink YARN Client就可以提交Flink Job到Flink JobManager,并进行后续的映射、调度和计算处理。
在YARN上启动一个Flink主要有两种方式:(1)、启动一个YARN session(Start a long-running Flink cluster on YARN);(2)、直接在YARN上提交运行Flink作业(Run a Flink job on YARN)。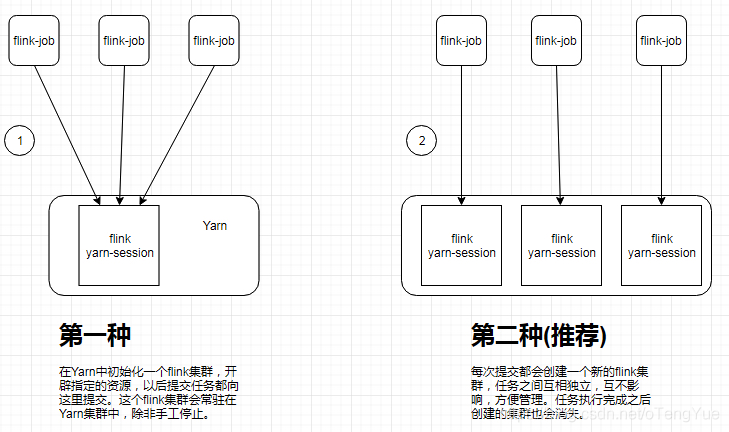
Flink YARN Session
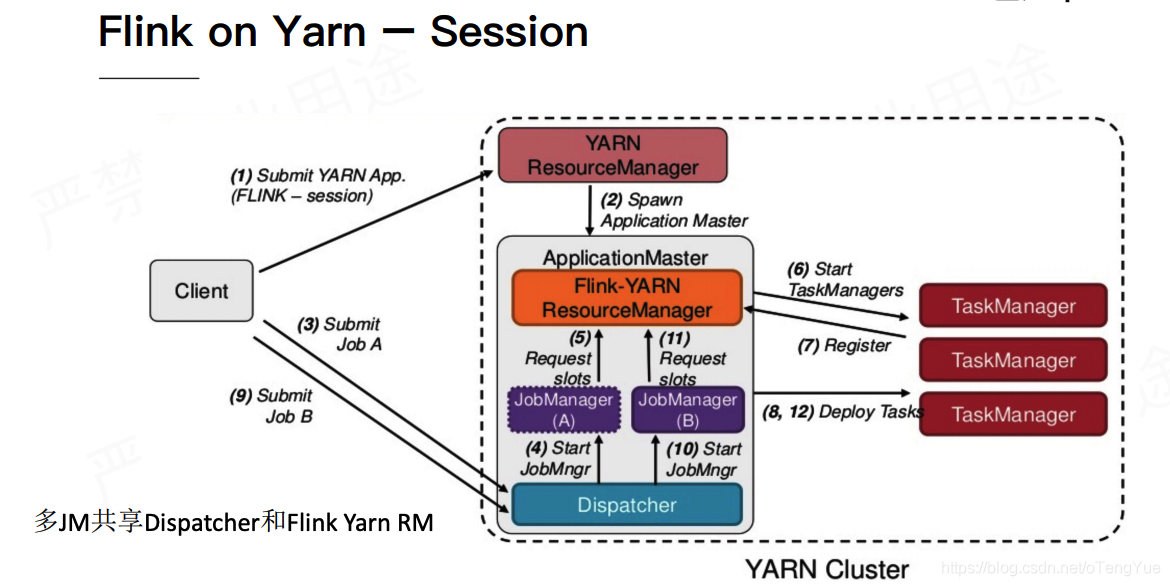
首先,看下yarn-session.sh脚本参数
yarn-session.sh脚本参数
用法:
必须:
-n,--container <arg> 要分配的YARN容器数(=任务管理器数)
可选的
-D <property=value> 使用给定属性的值
-d,--detached 如果存在,则以分离模式运行作业,不启动客户端进程,不打印YARN返回信息
-h,--help
-id,--applicationId <arg> 附加到正在运行的YARN会话
-j,--jar <arg> Flink jar文件的路径
-jm,--jobManagerMemory <arg> 具有可选单元的JobManager容器的内存(默认值:MB)
-m,--jobmanager <arg> 要连接的JobManager(主站)的地址。 使用此标志连接到指定地址的JobManager
配置中的:
-n,--container <arg> 要分配的YARN容器数(=任务管理器数)
-nl,--nodeLabel <arg> 为YARN应用程序指定YARN节点标签
-nm,--name <arg> 在YARN上为应用程序设置自定义名称
-q,--query 显示可用的YARN资源(内存,内核)
-qu,--queue <arg> 指定YARN队列
-s,--slots <arg> 每个TaskManager的槽
-sae,--shutdownOnAttachedExit 如果作业以附加模式提交,请在CLI突然终止时执行尽力而为的群集关闭,例如,响应用户中断,
例如键入Ctrl + C.
-st,--streaming 流模式启动flink
-t,--ship <arg> 在指定目录中发送文件(t用于传输)
-tm,--taskManagerMemory <arg> 没taskmanager内存数
-yd,--yarndetached 如果存在,则以分离模式运行作业(不建议使用;请改为使用非YARN特定选项)
-z,--zookeeperNamespace <arg> 命名空间,用于为高可用性模式创建Zookeeper子路径
在启动的是可以指定TaskManager的个数以及内存(默认是1G),也可以指定JobManager的内存,但是JobManager的个数只能是一个。好了,我们开启动一个YARN session:./bin/yarn-session.sh -n 10 -tm 8192 -s 32
上面命令启动了10个TaskManager,每个管理器具有8 GB内存和32个处理插槽(是每个TaskManager,默认是1个核)。
注:以上命令实际启动了11个容器(即使只请求了10个容器),因为ApplicationMaster和Job Manager还有一个额外的容器。
上述命令一直在终端中运行着的,此时可以通过停止unix进程(使用CTRL + C)或在客户端输入“stop”来停止yarn session。
如果想启动一个后台运行的yarn session。使用这个参数:-d 或者 –detached 在这种情况下,flink yarn client将会只提交任务到集群然后关闭自己。
附着到一个已存在的flink yarn session,可以用./bin/yarn-session.sh -id <applicationId>
如果关闭一个已存在的flink yarn session,可以用yarn application -kill <applicationId>
启动了YARN session之后我们如何运行作业呢?很简单,我们可以使用./bin/flink脚本提交作业,同样我们来看看这个脚本支持哪些参数:
flink 命令脚本参数说明
操作“run”编译并运行程序。
run 操作选项
-c,--class <classname> 具有程序入口点的类“main”方法或“getPlan()”方法。仅在JAR文件未在其清单中指定类时才需要。
-C,--classpath <url> 向集群中所有节点上的每个用户代码类加载器添加URL。路径必须指定协议(例如file://)并且可以在所有节点上访问
(例如,通过NFS共享)。您可以多次使用此选项来指定多个URL。该协议必须由{@link java.net.URLClassLoader}支持。
-d,--detached 如果存在,则以分离模式运行作业(不启动客户端,集群提交方式,不在客户端打印返回信息)
-n,--allowNonRestoredState 允许跳过无法恢复的保存点状态。如果在触发保存点时从程序中删除了作为程序一部分的运算符,则需要允许此操作。
-p,--parallelism <parallelism> 运行程序的并行性。可选标志,用于覆盖配置中指定的默认值。
-q,--sysoutLogging 如果存在,则将日志记录输出抑制为标准输出
-s,--fromSavepoint <savepointPath> 保存点的路径,用于从中恢复作业(例如hdfs:///flink/savepoint-1537)。
-sae,--shutdownOnAttachedExit 如果作业以附加模式提交,请在CLI突然终止时执行尽力而为的群集关闭,例如,响应用户中断,例如键入Ctrl + C.
YARN集群模式选项:
-d,--detached 如果存在,则以分离模式运行作业
-m,--jobmanager <arg> 要连接的JobManager(主站)的地址。使用此标志连接到与配置中指定的JobManager不同的JobManager。
-yD <property=value> 使用给定属性的值
-yd,--yarndetached 如果存在,则以分离模式运行作业(不建议使用;请改为使用非YARN特定选项)
-yh,--yarnhelp yarn session cli帮助(“-yh”不是有效的操作)
-yid,--yarnapplicationId <arg> 附加到正在运行的YARN会话
-yj,--yarnjar <arg> Flink jar文件的路径
-yjm,--yarnjobManagerMemory <arg> 有可选单元的JobManager容器的内存(默认值:MB)
-yn,--yarncontainer <arg> 要分配的YARN容器数(=任务管理器数)
ynl,--yarnnodeLabel <arg> 为YARN应用程序指定YARN节点标签
-ynm,--yarnname <arg> 在YARN上为应用程序设置自定义名称
-yq,--yarnquery 显示可用的YARN资源(内存,内核)
-yqu,--yarnqueue <arg> 指定YARN队列
-ys,--yarnslots <arg> 每个TaskManager的插槽数
-yst,--yarnstreaming 以流模式启动Flink
-yt,--yarnship <arg> 在指定目录中发送文件(t用于传输)
-ytm,--yarntaskManagerMemory <arg> 具有可选单元的每个TaskManager容器的内存(默认值:MB)
-yz,--yarnzookeeperNamespace <arg> 命名空间,用于为高可用性模式创建Zookeeper子路径
-z,--zookeeperNamespace <arg> 命名空间,用于为高可用性模式创建Zookeeper子路径
默认模式的选项:
-m,--jobmanager <arg> 要连接的JobManager(主站)的地址。 使用此标志连接到与配置文件中指定的JobManager不同的JobManager。
-z,--zookeeperNamespace <arg> 命名空间,用于为高可用性模式创建Zookeeper子路径
操作“info”显示程序的优化执行计划(JSON)。
语法:info [OPTIONS] <jar-file> <arguments>
“info”动作选项:
-c,--class <classname> 具有程序入口点的类(“main”方法或“getPlan()”方法。仅在JAR文件未在其清单中指定类时才需要。
-p,--parallelism <parallelism> 运行程序的并行性。 可选标志,用于覆盖配置中指定的默认值。
操作“list”列出了运行和计划的程序。
语法: list [OPTIONS]
"list" 操作选项
-r,--running 仅显示正在运行的程序及其JobID
-s,--scheduled Show only scheduled programs and their JobIDs
yarn-cluster 模式选项
-m,--jobmanager <arg> 要连接的JobManager(主站)的地址。 使用此标志连接到与配置中指定的JobManager不同的JobManager。
-yid,--yarnapplicationId <arg> 附加到正在运行的YARN会话
-z,--zookeeperNamespace <arg> 命名空间,用于为高可用性模式创建Zookeeper子路径
默认模式的选项:
-m,--jobmanager <arg>
-z,--zookeeperNamespace <arg>
操作“stop”会停止正在运行的程序(仅限流式处理作业)。
语法:stop [OPTIONS] <Job ID>
"stop"操作选项:
yarn-cluster 模式选项
-m,--jobmanager <arg> 指定需要操作的非默认的jobmanager地址
-yid,--yarnapplicationId <arg> 追加到指定的yarn容器
-z,--zookeeperNamespace <arg> 命名空间,用于为高可用性模式创建Zookeeper子路径
默认选项
-m,--jobmanager <arg>
-z,--zookeeperNamespace <arg>
操作“cancel”取消正在运行的程序。
语法:cancel [OPTIONS] <Job ID>
"cancel" 操作选项
-s,--withSavepoint <targetDirectory> 触发保存点并取消作业。 目标目录是可选的。 如果未指定目录,则使用配置的缺省目录(state.savepoints.dir)。
yarn-cluster 模式选项
-m,--jobmanager <arg> 指定需要操作的非默认的jobmanager地址
-yid,--yarnapplicationId <arg> 追加到指定的yarn容器
-z,--zookeeperNamespace <arg> 命名空间,用于为高可用性模式创建Zookeeper子路径
默认模式的选项:
-m,--jobmanager <arg>
-z,--zookeeperNamespace <arg>
操作"savepoint" 触发正在运行的作业的保存点或处置现有作业。
语法:savepoint [OPTIONS] <Job ID> [<target directory>]
"savepoint"操作选项
-d,--dispose <arg> 处置的保存点的路径。
-j,--jarfile <jarfile> flink程序jar文件
yarn-cluster 模式选项
-m,--jobmanager <arg> 要连接的JobManager(主站)的地址。 使用此标志连接到与配置中指定的JobManager不同的JobManager。
-yid,--yarnapplicationId <arg> 附加到正在运行的YARN会话
-z,--zookeeperNamespace <arg> 命名空间,用于为高可用性模式创建Zookeeper子路径
默认模式的选项:
-m,--jobmanager <arg>
-z,--zookeeperNamespace <arg>
操作"modify"修改正在运行的作业(例如,并行性的改变)。
语法:modify <Job ID> [OPTIONS]
"modify" 操作选项
-h,--help
-p,--parallelism <newParallelism> 指定作业的新并行性。
-v,--verbose 不推荐使用此选项。
yarn-cluster 模式选项
-m,--jobmanager <arg> 指定需要操作的非默认的jobmanager地址
-yid,--yarnapplicationId <arg> 追加到指定的yarn容器
-z,--zookeeperNamespace <arg> 命名空间,用于为高可用性模式创建Zookeeper子路径
默认模式的选项:
-m,--jobmanager <arg>
-z,--zookeeperNamespace <arg>
可以自动获取到YARN session的地址,然后我们以WordCount程序启动程序:
./bin/flink run ./examples/batch/WordCount.jar \
--input hdfs:///user/iteblog/LICENSE \
--output hdfs:///user/iteblog/result.txt
Run a single Flink job on YARN(推荐)
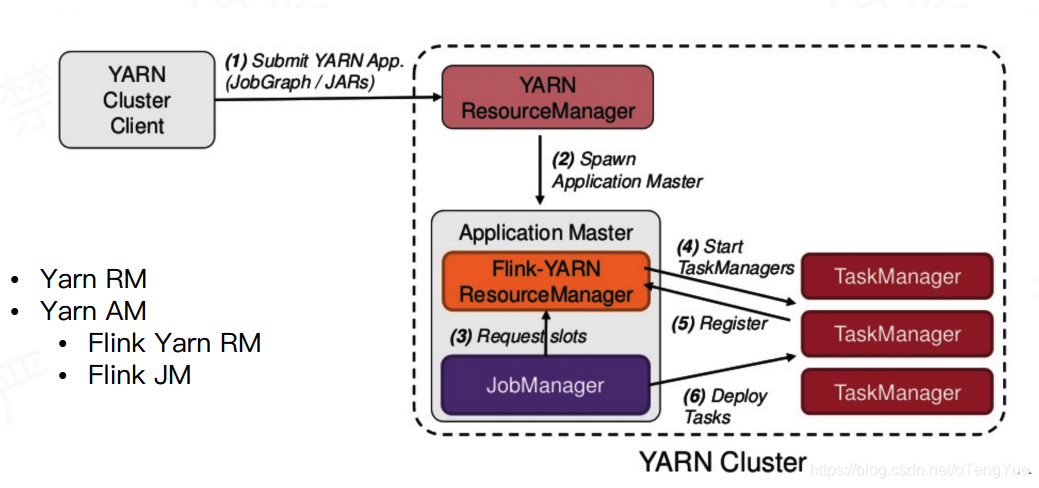
我们也可以不需要事先启动YARN session,而直接启动一个Flink作业,在这个作业运行完session也就结束了。
#命令行启动示例:
./bin/flink run -m yarn-cluster -yn 2 ./examples/batch/WordCount.jar \
--input hdfs:///user/iteblog/LICENSE \
--output hdfs:///user/iteblog/result.txt
上面的命令同样会启动一个类似于YARN session启动的页面。其中的-yn是指TaskManager的个数,必须指定。
Standalone部署
一般用于开发环境
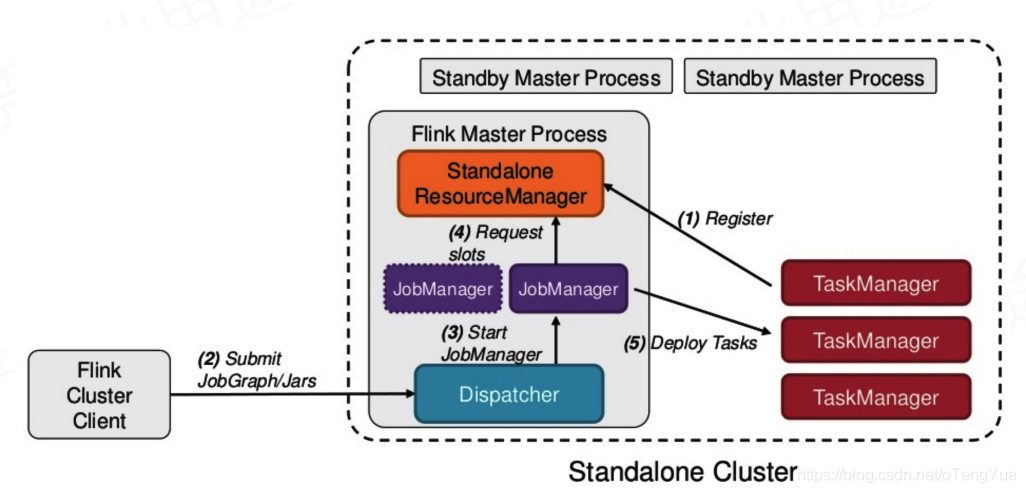
参考:Flink从入门到放弃(入门篇2)-本地环境搭建&构建第一个Flink应用.md
Storm、Spark-Streaming和Flink对比
| storm | spark streaming | flink | |
|---|---|---|---|
| 流模型 | 原生流 | 微批次 | 原生流 |
| 延迟 | 毫秒 | 秒 | 毫秒 |
| 消息处理 | At least once | exactly once | exactly once |
| 消息容错 | 记录&ack | 基于RDD的checkpoint | checkpoint(基于分布式快照) |
| 状态管理 | 非内置 | 专有的DStream | 带状态的操作 |
| 吞吐量 | 低 | 高 | 高 |
| API | Low level | High level | High level |
| 成熟度 | 高(工业标准) | 高(正当时) | 低(新兴) |
| 代码贡献量 | 378 | 1400 | 543 |
| Beam Runner | not support | support | support |
参考:
流计算框架 Flink 与 Storm 的性能对比:https://tech.meituan.com/2017/11/17/flink-benchmark.html
Demo演示(SocketTextStreamWordCount)
我们使用 Flink 自带的 examples 包中的 SocketTextStreamWordCount,这是一个从 socket 流中统计单词出现次数的例子。(如果仅仅是演示效果,在Standalone模式下即可),假设flink的安装目为FLINK_HOME
SocketTextStreamWordCount 的具体代码如下:(flink-1.0.x 版本,最新示例点击)
public static void main(String[] args) throws Exception {
// 检查输入
final ParameterTool params = ParameterTool.fromArgs(args);
...
// set up the execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// get input data
DataStream<String> text =
env.socketTextStream(params.get("hostname"), params.getInt("port"), '\n', 0);
DataStream<Tuple2<String, Integer>> counts =
// split up the lines in pairs (2-tuples) containing: (word,1)
text.flatMap(new Tokenizer())
// group by the tuple field "0" and sum up tuple field "1"
.keyBy(0)
.sum(1);
counts.print();
// execute program
env.execute("WordCount from SocketTextStream Example");
}
1、首先,使用 netcat 启动在终端中输入:
nc -l 9000
2、提交Flink作业
cd FLINK_HOME,直接使用example中的SocketTextStreamWordCount.jar即可。
./bin/flink run examples/streaming/SocketTextStreamWordCount.jar --port 9000
3、输入单词并查看结果
在第1步的netcat中输入单词(多个单词用空格隔开)
新开终端,cd FLINK_HOME,执行tail -f flink*.out,可以实时查看执行结果
另外,日志可可以在web ui上直接查看
参考:https://flink.sojb.cn/tutorials/local_setup.html
Fink-Startup
maven创建初始工程
Flink Maven Archetype 来创建我们的项目结构和一些初始的默认依赖。在你的工作目录下,运行如下命令来创建项目:
mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeCatalog=https://repository.apache.org/content/repositories/snapshots/ \
-DarchetypeVersion=1.7-SNAPSHOT
当然也可以用以下命令
curl https://flink.apache.org/q/quickstart-SNAPSHOT.sh | bash -s 1.7-SNAPSHOT
这样一个工程就构建好了
参考:
参考
Apache Flink官方文档(英文):https://ci.apache.org/projects/flink/flink-docs-stable/
Ververica【推荐】:https://ververica.cn/
Apache Flink中文文档:https://flink.sojb.cn
github:https://github.com/apache/flink
flink-forward-china-2018: https://github.com/flink-china/flink-forward-china-2018
flink-training-course:https://github.com/flink-china/flink-training-course
God-Of-BigData:https://github.com/wangzhiwubigdata/God-Of-BigData/tree/master/Flink
Flink China:https://zh.ververica.com
一文了解 Apache Flink 核心技术:http://wuchong.me/blog/2018/11/09/flink-tech-evolution-introduction/
深入理解Apache Flink核心技术:https://www.toutiao.com/a6254143247988293890
Apache Flink状态管理和容错机制介绍:https://www.iteblog.com/archives/2417.html
Flink Improvement Proposals:https://cwiki.apache.org/confluence/display/FLINK/Flink+Improvement+Proposals
Flink on YARN部署快速入门指南:https://www.iteblog.com/archives/1620.html
Flink流计算编程–Flink扩容、程序升级前后的思考:https://blog.csdn.net/lmalds/article/details/73457767