did
这次推文的内容主要是介绍选择偏差及其导致的内生性问题,以及缓解这种内生性问题的倾向得分匹配法(Propensity Score Matching,PSM),并且用一实例介绍一下如何将PSM与DID结合,即PSM - DID在Stata中的具体操作。
注:推文中的公式与代码块均可左右滑动。
一、选择偏差与内生性
1.1 结论可信吗?
先举两个例子。
- 例1:进行一项调查,调查内容是去不去医院是否会影响个人健康,因此向医院里的各类人员发放问卷并得出其健康状况,最后发现去医院不利于个人健康。
- 例2:评估一项污染防治政策的政策效果,选择期初污染程度基本一致的地区作为样本,并根据各地区意愿决定其是否实施该项政策,3年后政策实施地的污染指标明显低于未实施该政策的地区,结论是这项政策有效。
以上问卷调查和政策评估的结论可信吗?
例1的问题很明显,去医院的大多是健康状况不佳的患者,因此从逻辑上来说正是人们健康状况不佳才选择去医院,而不是因为他们去了医院才导致健康状况不佳。为了得到更令人信服的结论,应该将调查人群(样本)扩大至所有场合,而不仅仅是医院。与之类似的案例还有,在健身房调查健身对脱发的影响等。
例2的问题不易看出,从DID的角度来看,“期初污染程度基本一致”说明平行趋势检验基本通过,因此直观上政策实施地(处理组)的污染指标(结果变量y)与未实施政策地区(控制组)的污染指标的差值就是政策的处理效应,差值为负(假设指标越小污染程度越低)说明政策有效。但是,还应该看到的是,“根据各地区意愿决定其是否实施该项政策”,也就是说各地区是否实施该项政策是自己选择的。实际上,某地是否实施政策更多基于地理区位、经济发展和产业结构等因素的考量。这也与现实情况吻合,政策一般都在先行示范区率先实施,而这些示范区经济发展水平都较高。
那为什么说例2的政策评估结论不可信呢?
从计量的角度分析,影响某地是否实施政策(即处理组虚拟变量du的取值)的因素也会影响该地区的污染指标(y),这些因素可以分为可观测因素与不可观测因素。
首先,可观测说明可度量,这些可观测变量与y相关,因此可以将其引入到我们的模型中,虽然可能与du存在共线性,但一定程度的共线性不是问题。问题是我们无法找出所有的可观测变量(或者可观测变量以非线性的形式影响结果变量),而这部分没有引入模型中的可观测变量(或者可观测变量的非线性形式)就被放到扰动项中,造成扰动项与du相关,即存在内生性,最后导致did项的估计系数存在偏误。
其次,不可观测说明不可度量,因此这部分不可观测因素必然就在扰动项中,同样会存在内生性问题,造成估计偏误。
1.2 样本选择性偏差与自选择偏差
例1和例2存在的问题本质上是不同的。
例1存在的问题是样本的选择不随机,即我们只获取了医院的样本,而没有随机调查其他场所。某些影响样本选择过程的因素也会影响到y,因此这些因素被放到扰动项中,造成选择过程与干扰项相关,存在内生性问题,这被称为样本选择性偏差(Sample Selection Bias)。然而,当我们重新审视样本选择性偏差导致内生性的逻辑时,可以发现所谓的“样本选择过程”并不是一个特定的变量,也没有放到我们的模型中,那为什么会导致解释变量与扰动项相关?Hansen在《ECONOMETRICS(V 2021)》第27章第9小节[1]给出了推导,并且还介绍了一种流行的解决方法——Heckman两步法,下期推送将用一具体实例讲解Heckman两步法在Stata中如何操作。
例2存在的问题是变量的选择不随机,换言之,各地区对是否实施政策有着自己的“小九九”。du的取值不随机,而是和其他因素相关,而这些因素又被放到扰动项中,造成解释变量与干扰项相关,存在内生性问题,这被称为自选择偏差(Self-Selection Bias)。若是由可观测变量导致的自选择偏差,可以使用PSM方法予以解决,这也是本次推文的主要内容之一。
综合来看,样本选择性偏差和自选择偏差都属于选择偏差(Selection Bias),只是侧重的角度不同,一个侧重的是样本的选择不随机,一个侧重的是变量的选择不随机,但都表明一个观点:非随机化实验将导致内生性。那么问题来了,什么是“非随机化实验”?先从为什么需要随机化实验说起,最后引出PSM - DID。
1.3 随机分组与依可测变量选择
还是以一个例子来分析。
假设要评估一项实验的效果,也就是考察个体在接受试验()后他的结果变量y的变化。最理想也是最不现实的一种评估方法是找出这个人在平行时空中的个体,并让不接受实验(
),相同的一段时间后分别得到结果变量并将其作差,这个差值就是此次实验的参与者平均处理效应(Average Treatment Effect on the Treated,ATT),也就是我们要考察的实验效果。用公式来表达就是:
其中,
。
但是,平行时空中的个体一般是无法找到的(至少现在不能~),现实中,我们更多的是用参与实验个体的结果变量与未参与实验个体的结果变量
作差(即全部样本的平均处理效应,Average Treatment Effect,ATE),以ATE来代替ATT,如下式(2):
选择偏差
然而,正如式(2)所示,第二个等号右边可以分解为两个部分,第一部分是我们需要的ATT,第二部分是选择偏差。也就是说,当我们将处理组的与控制组的直接作差时,这个差值并不能代表纯粹的政策处理效应,即
(即便平行趋势检验通过)。
而为了使,其中一个思路就是消掉选择偏差这一部分,怎么消除?假设条件期望等于无条件期望;怎么实现条件期望等于无条件期望?假设均值独立于;怎么实现均值独立于
?随机分组。
也就是说,如果处理组的选择是随机的,就能实现处理组虚拟变量与结果变量均值独立,从而推出。换言之,只要处理组的选择是随机的,两组间的
之差就是我们需要的参与组平均处理效应ATT。
问题是,现实中处理组的选择是非随机的,即存在前文所说的自选择偏差,各个样本做出是否参与实验的决策是一种内生化的行为。那么,如果我们找到决定个体是否参与实验的因素,然后在控制组中匹配到这些因素与处理组相等的样本,最后将这些样本作为我们真正参与评估的控制组,这样是否就能说明处理组的选择是近似随机的呢?答案是可以的,Rosenbaum & Rubin(1983)[2]给出了证明。
[2] Rosenbaum P R, Rubin D B. The Central Role of the Propensity Score in Observational Studies for Causal Effects[J]. Biometrika, 1983, 70(01): 41-55.
简单捋一下上文的逻辑,估计ATT最理想的方法是找到参与实验的个体在平行时空的自己,并假设平行时空的自己没有参与实验,最后作差得出最纯粹的ATT,但是找到平行时空的自己不现实;退而求其次,我们可以使用随机分组的处理组与控制组,作差得到ATT,但现实中个体是否参与实验的选择不随机;为了得到随机化分组的样本,找出影响个体是否参与实验的因素,控制两组间因素的取值相等,最后利用处理后的分组样本作差得到ATT。
其中,当决定个体是否参与实验的因素是可观测因素时,个体的决策就是依可观测变量选择;当决定个体是否参与实验的因素是不可观测因素时,个体的决策就是依不可观测变量选择。由于不可观测因素不可度量,而将控制组样本与处理组样本匹配时需要准确识别出这些因素,因此以下匹配方法都是基于可观测变量(协变量)来设计的。
1.4 倾向得分匹配
关于怎么匹配又是一个问题。
如果决定个体是否参与实验的可观测变量是一个单一协变量,那么我们只要在控制组中找到与处理组协变量取值相等的样本作为我们的被匹配对象。然而,决定个体决策的协变量并非单一,而是一个由多个协变量构成的多维向量,直接使用
进行匹配可能遇到数据稀疏的问题。一种可行的思路是将多维向量进行降维,降维的方法解决数据稀疏问题的同时还保留了足够多的信息。实际使用中的方法主要有以下两种。
- 一是使用距离函数,如马氏距离。
- 二是倾向得分匹配PSM。
由于距离函数不是本文关注的重点,并且距离函数有其固有缺陷,因此这次不做赘述,详情参阅陈强(2014)《高级计量经济学及Stata应用(第二版)》第542页[3]。
PSM主要有以下三个步骤。
- 选择协变量。实际应用中,多数论文直接将基础回归所使用的控制变量作为协变量,这种做法的基本逻辑在于要求协变量与
相关,但问题在于这些控制变量不一定与处理组变量相关,即便相关,也可能是协变量的高次项或交互项与相关。更稳妥的做法是根据相关文献找出同时影响与的变量,但相关数据可能很难找到,因此直接使用控制变量作为协变量其实是一种妥协,但还是要仔细甄别每一个控制变量是否在理论上真正影响到,并且也要做协变量高次项或交互性的敏感性分析。
估计倾向得分值。作为被解释变量,协变量作为解释变量,由于是一个二元哑变量,因此使用logit模型或probit模型,应用中更多使用logit模型。logit回归之后会得到各个样本的倾向得分值(在psmatch2中将生成_pscore变量,_pscore介于
- 之间),之后就是根据
_pscore进行第三步的匹配。 - 根据
_pscore进行匹配。最常用的是卡尺最近邻匹配,其他匹配方法参阅陈强(2014)《高级计量经济学及Stata应用(第二版)》第545页。卡尺最近邻匹配基于最近邻匹配,最近邻匹配需要设置邻居数(neighbor(#1)),也就是说根据倾向得分值最接近的原则,每一个处理组样本匹配到#1个控制组样本,但如果控制组样本的倾向得分值与处理组样本差距太大,这样的匹配是没有多大意义的,因此需要还设置一个卡尺(caliper(#2)),即控制一个阈值界限,界限内的控制组样本可以作为匹配对象,界限外的样本则被忽视。
1.5 PSM + DID
PSM和DID是天生绝配!
为何这么说?
因为现实中的政策本质上是一种非随机化实验(或称,准自然实验),因此政策效应评估所使用的DID方法难免存在自选择偏差,而使用PSM方法可以为每一个处理组样本匹配到特定的控制组样本,使得准自然实验近似随机,注意是近似,因为影响决策的不可观测因素在两组间仍然存在差异。
如,石大千等(2018)[4]为了使实验组和控制组城市在各方面特征上尽可能地相似,消除选择偏差,选择PSM - DID方法以便更准确地评估智慧城市建设降低环境污染的效应。王雄元和卜落凡(2019)[5]认为开通“中欧班列”的枢纽城市自身交通基础设施较好,且上市公司分布存在区域集聚现象,为了消除选择偏差采用PSM - DID方法进行稳健性检验。丁宁等(2020)[6]考虑到绿色信贷和银行成本效率之间可能存在内生性,为了解决这个问题,采用了PSM - DID方法。郭晔和房芳(2021)[7]为了缓解实验组和对照组企业之间的其他差异对研究结果的干扰,同样采用了PSM - DID方法。其他采用PSM - DID方法缓解因选择偏差导致的内生性问题的文献还有孙琳琳等(2020)[8]、陆菁等(2021)[9]和余东升等(2021)[10]等。
[4] 石大千, 丁海, 卫平, 刘建江. 智慧城市建设能否降低环境污染[J]. 中国工业经济, 2018(06): 117-135.
[5] 王雄元, 卜落凡. 国际出口贸易与企业创新——基于“中欧班列”开通的准自然实验研究[J]. 中国工业经济, 2019(10): 80-98.
[6] 丁宁, 任亦侬, 左颖. 绿色信贷政策得不偿失还是得偿所愿?——基于资源配置视角的PSM-DID成本效率分析[J]. 金融研究, 2020(04): 112-130.
[7] 郭晔, 房芳. 新型货币政策担保品框架的绿色效应[J]. 金融研究, 2021(01): 91-110.
[8] 孙琳琳, 杨浩, 郑海涛. 土地确权对中国农户资本投资的影响——基于异质性农户模型的微观分析[J]. 经济研究, 2020, 55(11): 156-173.
[9] 陆菁, 鄢云, 王韬璇. 绿色信贷政策的微观效应研究——基于技术创新与资源再配置的视角[J]. 中国工业经济, 2021(01): 174-192.
[10] 余东升, 李小平, 李慧. “一带一路”倡议能否降低城市环境污染?——来自准自然实验的证据[J]. 统计研究, 2021, 38(06): 44-56.
然而,PSM - DID也并非是解决选择偏差的灵丹妙药,除了PSM本身不能控制因不可观测因素导致的组间差异,在与DID结合时还存在一个更为关键的问题。
从本质上来说,PSM适用于截面数据,而DID仅仅适用于时间 – 截面的面板数据。
- 对于PSM,每一个处理组样本匹配到的都是同一个时点的控制组样本,相应得到的
ATT仅仅是同一个时点上的ATT。下文psmatch2的输出结果中,ATT那一行结果就仅仅代表同一个时点上的参与者平均处理效应。 - 对于DID,由于同时从时间与截面两个维度进行差分,所以DID本身适用的条件就是面板数据。因此,由PSM匹配到的样本原本并不能直接用到DID中做回归。
面对两者适用数据类型的不同,现阶段的文献大致有两种解决思路。
- 第一,将面板数据视为截面数据再匹配。如上文参考文献中的绝大多数。
- 第二,逐期匹配。如,Heyman et al.(2007)[11]、Bockerman & Ilmakunnas(2009)[12]等。
[11] Heyman F, Sjoholm F, Tingvall P G. Is There Really a Foreign Ownership Wage Premium? Evidence from Matched Employer-Employee Data[J]. Journal of International Economics, 2007, 73(02): 355-376.
[12] Bockerman P, Ilmakunnas P. Unemployment and Self-Assessed Health: Evidence from Panel Data[J]. Health Economics, 2009, 18(02): 161-179.
然而,谢申祥等(2021)[13]指出了这两种方法的不足。
- 第一,将面板数据转化为截面数据进行处理存在“自匹配”问题。
- 第二,逐期匹配将导致匹配对象在政策前后不一致。
[13] 谢申祥, 范鹏飞, 宛圆渊. 传统PSM-DID模型的改进与应用[J]. 统计研究, 2021, 38(02): 146-160.
虽然传统的研究思路存在一定程度的不足,但本次推送还是按照传统的设计思路介绍一下PSM - DID如何在Stata中实现。
具体来说,本次推送将使用李青原和章尹赛楠(2021)[14]公布在《中国工业经济》官网的原始数据,首先,分别采用截面PSM与逐年PSM两种方法获得匹配样本,之后将匹配样本进行DID回归,并比较匹配后的回归结果与匹配前的基准回归结果,进而验证结论的稳健性。
[14] 李青原, 章尹赛楠. 金融开放与资源配置效率——来自外资银行进入中国的证据[J]. 中国工业经济, 2021(05): 95-113.
事实上,这篇文章也注意到了选择偏差的问题,但却是采用自助法(Bootstrapping)进行重复随机抽样(抽取500次,每次抽取1,000个样本),然后将抽取到的样本进行回归,最后重复随机抽样的结果与基准回归结果无实质性差异,从而证明了结论的稳健性。因此,本次推送将是从PSM的角度对基准回归结果进行复盘和二次验证。
二、PSM – DID的实现
2.1 数据初步处理
在PSM和DID之前先定义路径、设置图片输出格式(Stata自带的图片主题太丑~)、定义控制变量(协变量)和回归命令选择项的全局暂元以及生成处理组虚拟变量,然后保存好初步处理的原始数据。
其中,处理组虚拟变量原始数据集中是没有的,因为多期DID直接结合时间虚拟变量与分组虚拟变量构成did项(数据集中的变量名为FB)。由于官网放出的原始代码给出了三段政策时间节点,以及各个时点政策实施地区的城市代码或省份代码,我们根据这个信息可以生成处理组虚拟变量treated。
*- 定义路径
cd "C:\Users\KEMOSABE\Desktop\psm-did"
*- 设置图片输出样式
graph set window fontface "Times New Roman"
graph set window fontfacesans "宋体"
set scheme s1color
use 行业数据.dta, clear
*- 定义全局暂元
global xlist "ADM PPE ADV RD HHI INDSIZE NFIRMS FCFIRM MARGIN LEVDISP SIZEDISP ENTRYR EXITR"
global regopt "absorb(city ind3) cluster(city#ind3 city#year) keepsing"
*- 生成处理组虚拟变量
gen treated = ( city == 5101 | city == 5000 | city == 2102 | city == 3501 ///
| city == 4401 | city == 3701 | city == 3201 | city == 3702 ///
| city == 3101 | city == 4403 | city == 1200 | city == 4201 ///
| city == 4404 | prov == 44 | prov == 45 | prov == 43 ///
| prov == 32 | prov == 33 | city == 1100 | city == 5301 ///
| city == 2101 | city == 3502 | city == 6101 | city == 2201 ///
| city == 2301 | city == 6201 | city == 6401 )
save psmdata.dta, replace
2.2 截面PSM – DID
由于psmatch2为外部命令,因此第一次使用该命令时需要键入如下代码进行安装。
ssc install psmatch2, replace
在使用psmatch2命令前,首先设置了一个随机种子并将样本进行随机排序,这么做的原因是在匹配控制组样本时,如果有几个样本的倾向得分值相同,系统会优先选择排序靠前的样本。当然,不进行随机排序直接使用原始数据集的默认样本顺序问题也不大。
**# 一、截面匹配
use psmdata.dta, clear
**# 1.1 卡尺最近邻匹配(1:2)
set seed 0000
gen norvar_1 = rnormal()
sort norvar_1
psmatch2 treated $xlist , outcome(TFPQD_OP) logit neighbor(2) ties common ///
ate caliper(0.05)
save csdata.dta, replace
treated是本例中的分组变量。$xlist是协变量的全局暂元,纯粹为了演示,这里直接使用基础回归中的控制变量,实际使用中一定要结合其他文献及敏感性分析挑选出适合的协变量。outcome(TFPQD_OP)括号里面填的是结果变量(这里是TFPQD_OP),即基准回归中的被解释变量y,括号里可以填入多个结果变量。logit表明使用logit模型估计倾向得分值,默认使用probit模型。neighbor(2)表明使用最近邻匹配,括号里填入2说明使用1:2的匹配方法,即一个处理组样本最多匹配2个控制组样本。至于为什么是2?因为使用1:1的配对方式最后的结果不好看~ties说明如果多个控制组样本的倾向得分值相同并且处于这个得分值的样本应该作为被匹配对象,那么匹配样本的结果变量取它们的均值,默认按照样本的排列顺序进行选择。这同时说明,如果加上ties,那么数据集是否提前排序就不怎么重要了。common表示只对倾向得分值共同取值范围内的样本进行匹配。也就是说,两组样本的倾向得分值如果不在共同取值范围内,则直接被排除,从一开始就没有匹配资格。默认对所有样本进行匹配。ate表示同时汇报ATE、ATU和ATT,默认只汇报ATT。ATE和ATT前文有介绍,ATU是非参与者的平均处理效应(Average Treatment Effect on the Untreated),我们重点关注的是ATT。caliper(0.05)表示卡尺设置为0.05,即控制组样本的倾向得分值如果在处理组样本倾向得分值±0.05以外,直接没有被匹配的资格。因此,如果选择项同时包括neighbor(#)和caliper(#),则说明使用卡尺最近邻匹配。至于为什么是0.05?道理同neighbor(2)~
关于psmatch2其他选择项的详细说明,请键入如下代码进行了解。
help psmatch2
psmatch2的运行结果包括三部分的内容。
Logistic regression Number of obs = 81,567
LR chi2(13) = 5973.89
Prob > chi2 = 0.0000
Log likelihood = -53407.844 Pseudo R2 = 0.0530
------------------------------------------------------------------------------
treated | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
ADM | 2.303432 .1007328 22.87 0.000 2.105999 2.500865
PPE | -1.222116 .0342674 -35.66 0.000 -1.289279 -1.154953
ADV | 21.56327 3.731756 5.78 0.000 14.24917 28.87738
RD | 18.12885 3.306851 5.48 0.000 11.64754 24.61016
HHI | -.4729895 .065837 -7.18 0.000 -.6020276 -.3439513
INDSIZE | .0015667 .0103893 0.15 0.880 -.018796 .0219294
NFIRMS | .4045981 .0190289 21.26 0.000 .3673021 .441894
FCFIRM | 2.685802 .1414342 18.99 0.000 2.408596 2.963008
MARGIN | .8316006 .0620282 13.41 0.000 .7100276 .9531736
LEVDISP | -2.178396 .0987579 -22.06 0.000 -2.371958 -1.984835
SIZEDISP | .2341893 .0247433 9.46 0.000 .1856934 .2826852
ENTRYR | -.0103419 .0385426 -0.27 0.788 -.0858841 .0652002
EXITR | -.1123095 .0605613 -1.85 0.064 -.2310075 .0063884
_cons | -.9478736 .1123736 -8.44 0.000 -1.168122 -.7276253
------------------------------------------------------------------------------
----------------------------------------------------------------------------------------
Variable Sample | Treated Controls Difference S.E. T-stat
----------------------------+-----------------------------------------------------------
TFPQD_OP Unmatched | 2.24921913 2.35179198 -.102572852 .006214925 -16.50
ATT | 2.24921615 2.35605481 -.106838668 .008017304 -13.33
ATU | 2.35179488 2.28215595 -.069638929 . .
ATE | -.089340447 . .
----------------------------+-----------------------------------------------------------
Note: S.E. does not take into account that the propensity score is estimated.
psmatch2: | psmatch2: Common
Treatment | support
assignment | Off suppo On suppor | Total
-----------+----------------------+----------
Untreated | 1 38,367 | 38,368
Treated | 1 43,198 | 43,199
-----------+----------------------+----------
Total | 2 81,565 | 81,567
- 第一部分是
logit回归结果,在这里没有多大意义。 - 第二部分则重点关注
ATT的大小与显著性。在未匹配前(Unmatched那一行),平均处理效应为-0.1026,且在1%的水平下显著(t值的绝对值大于2.58);匹配后,参与者的平均处理效应ATT为-0.1068,同样在1%的水平下显著。结果虽好,但不能开心太早,因为这里的ATT仅仅是参与者实施政策对结果变量的影响,双重差分只在截面维度进行了差分,时间维度并未考虑,换言之,这不是我们需要的DID的处理效应。反之,就算ATT不显著关系也不大,因为我们PSM的目的是获得匹配样本,真正的DID回归在之后。 - 第三部分考察两组在共同取值范围内(
On support那一列)的样本量。可以看到,处理组和控制组都分别只有一个样本在共同取值范围外,这说明绝大多数样本(特别是控制组样本)都有资格参与匹配。
接下来是平衡性检验(Balance Test)。即检验匹配后协变量取值在两组间是否存在显著差异,如果差异不明显,则说明匹配效果好,使用这样的匹配样本进行DID回归就比较合适。平衡性检验主要有两种。
- 一是度量两组间协变量的标准化均值的偏差
%bias。如果匹配后协变量的%bias小于10%,且明显小于未匹配前的%bias,则说明对于这个协变量来说,两组间并无差距。%bias的计算公式如下。
- 二是通过t检验来判断各个协变量的取值在两组间是否存在系统性偏差。t检验的原假设(
H0)是“两组间协变量的取值不存在系统性偏差”,因此我们的目标是最终接受H0。
psmatch2自带两个估计后检验命令,一个是pstest,用于进行平衡性检验;一个是psgraph,用柱状图的方式直观呈现出两组间满足共同支撑假设(即倾向得分值在共同取值范围内)样本的分布情况。
**# 1.2 平衡性检验
pstest, both graph saving(balancing_assumption, replace)
graph export "balancing_assumption.emf", replace
psgraph, saving(common_support, replace)
graph export "common_support.emf", replace
both表示同时显示匹配前后两组间各变量的平衡情况。graph表示图示各变量匹配前后的平衡情况。saving表示将图形保存为Stata可以识别的*.gph格式,方便后续修改。graph export表示将图形输出为*.emf矢量图,方便插入到论文中。
pstest的运行结果如下,包括两张表和一幅图(图 1)。
----------------------------------------------------------------------------------------
Unmatched | Mean %reduct | t-test | V(T)/
Variable Matched | Treated Control %bias |bias| | t p>|t| | V(C)
--------------------------+----------------------------------+---------------+----------
ADM U | .07524 .06583 11.5 | 16.40 0.000 | 1.07*
M | .07524 .07762 -2.9 74.7 | -3.92 0.000 | 0.77*
| | |
PPE U | .34533 .40875 -29.7 | -42.32 0.000 | 0.93*
M | .34532 .34725 -0.9 96.9 | -1.36 0.173 | 1.02*
| | |
ADV U | .00044 .00036 4.4 | 6.22 0.000 | 1.26*
M | .00044 .00042 1.1 75.5 | 1.50 0.133 | 1.03*
| | |
RD U | .00047 .0003 6.9 | 9.77 0.000 | 1.63*
M | .00047 .00045 0.5 92.1 | 0.72 0.470 | 1.03*
| | |
HHI U | .2341 .26739 -19.8 | -28.19 0.000 | 0.95*
M | .23409 .23365 0.3 98.7 | 0.38 0.703 | 0.97*
| | |
INDSIZE U | 13.279 12.873 29.9 | 42.60 0.000 | 1.01
M | 13.279 13.291 -0.9 96.9 | -1.31 0.189 | 0.85*
| | |
NFIRMS U | 2.6806 2.3742 37.9 | 53.74 0.000 | 1.35*
M | 2.6807 2.6892 -1.1 97.2 | -1.41 0.159 | 0.89*
| | |
FCFIRM U | .01606 .00744 15.2 | 21.47 0.000 | 2.16*
M | .01606 .01534 1.3 91.7 | 1.60 0.109 | 1.01
| | |
MARGIN U | .8387 .83491 2.9 | 4.17 0.000 | 1.01
M | .8387 .83786 0.6 77.9 | 0.95 0.343 | 0.99
| | |
LEVDISP U | .25657 .26916 -16.9 | -24.11 0.000 | 0.81*
M | .25656 .25834 -2.4 85.9 | -3.69 0.000 | 0.99
| | |
SIZEDISP U | 1.211 1.1797 8.3 | 11.88 0.000 | 0.85*
M | 1.211 1.2131 -0.5 93.4 | -0.83 0.405 | 0.97*
| | |
ENTRYR U | .081 .08743 -3.4 | -4.82 0.000 | 0.92*
M | .081 .07818 1.5 56.1 | 2.25 0.024 | 1.05*
| | |
EXITR U | .03935 .0459 -5.4 | -7.74 0.000 | 0.81*
M | .03935 .04031 -0.8 85.4 | -1.21 0.225 | 0.96*
| | |
----------------------------------------------------------------------------------------
* if variance ratio outside [0.98; 1.02] for U and [0.98; 1.02] for M
-----------------------------------------------------------------------------------
Sample | Ps R2 LR chi2 p>chi2 MeanBias MedBias B R %Var
-----------+-----------------------------------------------------------------------
Unmatched | 0.053 5936.79 0.000 14.8 11.5 55.2* 1.17 85
Matched | 0.000 45.01 0.000 1.1 0.9 4.6 0.91 77
-----------------------------------------------------------------------------------
* if B>25%, R outside [0.5; 2]
(file balancing_assumption.gph saved)
第一张表是我们关注的重点。可以看到,所有协变量的%bias均小于10%,且都明显小于匹配前的%bias,%bias的绝对值较匹配前大幅下降了56.1%~98.7%;除ADM、LEVDISP和ENTRYR这三个协变量外,其余协变量均不拒绝“两组间协变量的取值不存在系统性偏差”的原假设。
第二张表是匹配前后logit回归的情况,其中Unmatched那一行是匹配前的回归结果,与psmatch2运行后第一张表保持一致,Matched那一行是匹配后的logit回归情况。可以看到,匹配后回归结果中伪R方(Ps R2)明显变小,这说明匹配后两组间的所有协变量取值差异性都不大,从而对logit回归中的被解释变量的变动没有太大的解释力。

图 1和第一张表的结果保持一致,即所有协变量的%bias均小于10%,并且都明显小于匹配前的%bias。
psgraph的运行结果如图 2。同样,图 2和前文psmatch2运行结果中的第三张表保持一致,即处理组和控制组的绝大多数样本都在共同取值范围内,而不在共同取值范围内的样本的倾向得分值比较极端(从图片中暂时无法看出是极端大还是极端小)。

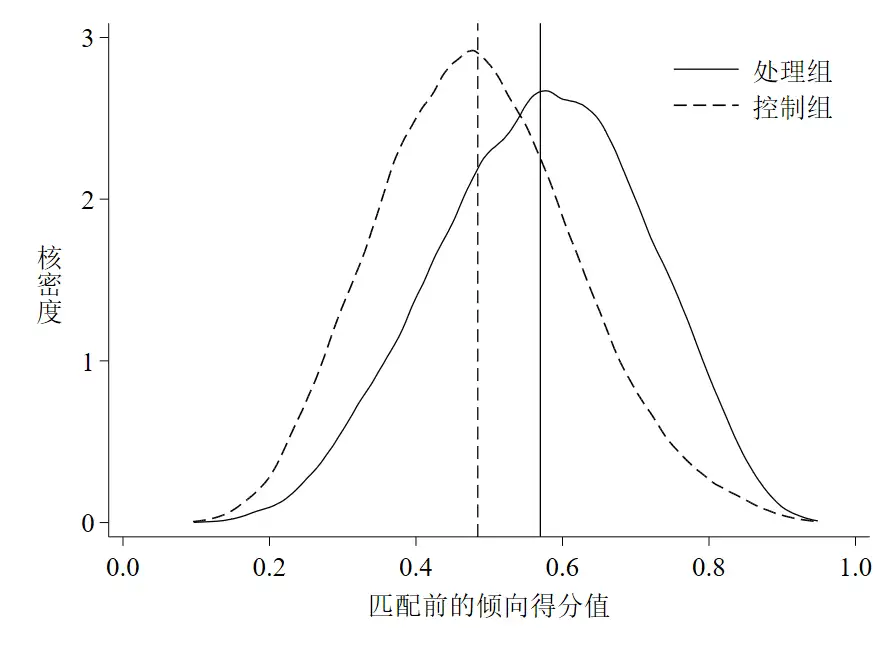
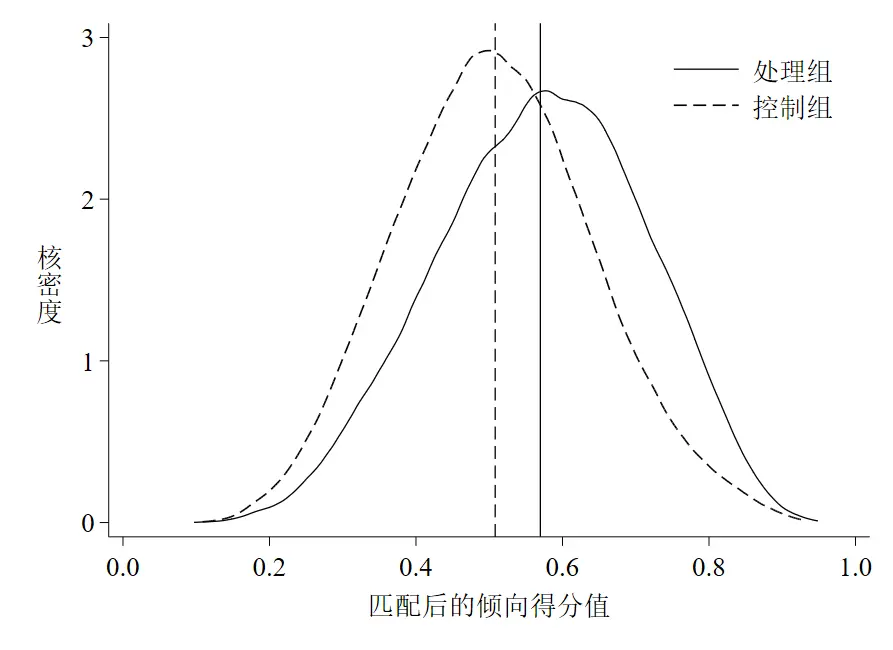
然后我们还可以考察一下两组倾向得分值在匹配前后是否存在差异,这里可以使用核密度图来直观体现。如果匹配前两组间的核密度曲线偏差比较大,而匹配后核密度曲线比较接近,说明匹配效果好。
**# 1.3 倾向得分值的核密度图
sum _pscore if treated == 1, detail // 处理组的倾向得分均值为0.5632
*- 匹配前
sum _pscore if treated == 0, detail
twoway(kdensity _pscore if treated == 1, lpattern(solid) ///
lcolor(black) ///
lwidth(thin) ///
scheme(qleanmono) ///
ytitle("{stSans:核}""{stSans:密}""{stSans:度}", ///
size(medlarge) orientation(h)) ///
xtitle("{stSans:匹配前的倾向得分值}", ///
size(medlarge)) ///
xline(0.5632 , lpattern(solid) lcolor(black)) ///
xline(`r(mean)', lpattern(dash) lcolor(black)) ///
saving(kensity_cs_before, replace)) ///
(kdensity _pscore if treated == 0, lpattern(dash)), ///
xlabel( , labsize(medlarge) format(%02.1f)) ///
ylabel(0(1)4, labsize(medlarge)) ///
legend(label(1 "{stSans:处理组}") ///
label(2 "{stSans:控制组}") ///
size(medlarge) position(1) symxsize(10))
graph export "kensity_cs_before.emf", replace
discard
*- 匹配后
sum _pscore if treated == 0 & _weight != ., detail
twoway(kdensity _pscore if treated == 1, lpattern(solid) ///
lcolor(black) ///
lwidth(thin) ///
scheme(qleanmono) ///
ytitle("{stSans:核}""{stSans:密}""{stSans:度}", ///
size(medlarge) orientation(h)) ///
xtitle("{stSans:匹配后的倾向得分值}", ///
size(medlarge)) ///
xline(0.5632 , lpattern(solid) lcolor(black)) ///
xline(`r(mean)', lpattern(dash) lcolor(black)) ///
saving(kensity_cs_after, replace)) ///
(kdensity _pscore if treated == 0 & _weight != ., lpattern(dash)), ///
xlabel( , labsize(medlarge) format(%02.1f)) ///
ylabel(0(1)4, labsize(medlarge)) ///
legend(label(1 "{stSans:处理组}") ///
label(2 "{stSans:控制组}") ///
size(medlarge) position(1) symxsize(10))
graph export "kensity_cs_after.emf", replace
discard
以上代码的运行结果如下图 3和图 4。

可以看到,匹配前后两条核密度曲线偏差都较大,但匹配后两条曲线更为接近了,这点可以从均值距离缩小看出(图中垂直于横轴的实线是处理组样本倾向得分值的均值线,虚线是控制组的均值线)。因此,一定程度上可以说明我们的匹配还是有效果的(虽然效果不太明显~)。
最后就是利用PSM后的样本进行DID回归,并将回归结果与基准回归结果进行比较。
回归需要样本,那么如何获取匹配后的样本呢?
打开Stata的数据编辑器,可以观察到psmatch2在我们的数据集中生成了几个新变量,如下图 5。

_pscore是样本的倾向得分值。_treated是处理组虚拟变量,和我们手动生成的treated保持一致。_support是样本是否满足共同支撑假设的虚拟变量,即如果样本处于共同取值范围内,该变量取值为1,否则为0。_weight是一个关键变量。
- 对于处理组样本来说,该变量为空说明没有参与匹配(即未满足共同支撑假设),或者参与匹配了但在卡尺范围内暂未匹配到控制组样本;如果匹配成功了,该变量取值为1(奇了怪了,部分处理组样本该变量取值居然不等于1,甚至不为整!)。
- 对于控制组样本来说,该变量为空说明样本不满足共同支撑假设或在卡尺范围内没有匹配成功;对于匹配成功的样本,该变量可能取整也可能不取整,这取决于样本匹配成功的次数。具体来说,如果是
1:1无放回匹配,则每个处理组样本最多匹配成功一次,并且控制组样本也最多被匹配一次,因此对于控制组中匹配成功的样本来说,_weight只可能等于1;如果是1:1有放回匹配,则每个处理组样本最多匹配成功一次,而控制组样本可能被匹配k次,因此对于控制组中匹配成功的样本来说,_weight的取值为大于等于1的整数;如果是1:m的有放回匹配(psmatch2只允许在1:1匹配中设置无放回选项),则一个处理组样本最多可以匹配到m个对象,因此被匹配到的对象所占的权重为
,那么对于控制组样本来说,如果它被匹配到了k次,那么它的总权重就是,即_weight取值为
- 。如果我们想要知道在
1:m有放回匹配中,控制组样本被匹配的次数k,那么就只要将它们的_weight乘以m即可。因此,_weight的取值表明了样本是否参与匹配以及样本的重要性程度。
_TFPQD_OP代表样本匹配到对象的结果变量(这里是TFPQD_OP)的均值。_id是psmatch2自动为每一个样本赋予的唯一识别编码。_n1和n2代表样本匹配对象在_id中的编码,由于这里是1:2匹配,所以有两个。_nn表示处理组样本匹配到的控制组样本的个数。_pdif表示样本的倾向得分值与_n1样本倾向得分值之差的绝对值。
由此可知,只要样本的_weight不为空,就代表该样本参与了匹配,就可以将这些样本代入到DID回归模型中进行参数估计,而且一定程度上缓解了基准回归中存在的选择偏差问题,进一步还可以与基准回归结果进行比较以检验其稳健性。
事实上,多数文献都是按照这个思路进行的,当然,也有部分文献直接选择满足共同支撑假说的样本代入到DID回归模型中,如李青原和肖泽华(2020)[15]。
[15] 李青原, 肖泽华. 异质性环境规制工具与企业绿色创新激励——来自上市企业绿色专利的证据[J]. 经济研究, 2020, 55(09): 192-208.
但是,这样可能忽视了一个关键问题。无论是使用权重不为空的样本还是使用满足共同支撑假设的样本进行回归,都忽视了一个基本事实,那就是被匹配的控制组样本可能作为多个处理组样本的匹配对象,因此不同权重的控制组样本在总体的控制组样本中的重要性程度是不一样的。权重越大,说明被匹配上的次数越多,参与回归时越应该被重视,因此一种可行的办法是根据权重来复制控制组中被匹配上的样本,也就是所谓的频数加权回归[16]。
所以,在进行回归结果对比时,除了需要包括两个基准回归、一个使用权重不为空的样本进行的回归和一个使用使用满足共同支撑假设的样本进行的回归,还需要包括一个考虑样本重要性的频数加权回归。
**# 1.4 回归结果对比
use csdata.dta, clear
*- 基准回归1(混合OLS)
qui: reg TFPQD_OP FB $xlist , cluster(city)
est store m1
*- 基准回归2(固定效应模型)
qui: reghdfe TFPQD_OP FB $xlist , $regopt
est store m2
*- PSM-DID1(使用权重不为空的样本)
qui: reghdfe TFPQD_OP FB $xlist if _weight != ., $regopt
est store m3
*- PSM-DID2(使用满足共同支撑假设的样本)
qui: reghdfe TFPQD_OP FB $xlist if _support == 1, $regopt
est store m4
*- PSM-DID3(使用频数加权回归)
gen weight = _weight * 2
replace weight = 1 if treated == 1 & _weight != .
qui: reghdfe TFPQD_OP FB $xlist [fweight = weight], $regopt
est store m5
*- 回归结果输出
local mlist_1 "m1 m2 m3 m4 m5"
reg2docx `mlist_1' using 截面匹配回归结果对比.docx, b(%6.4f) t(%6.4f) ///
scalars(N r2_a(%6.4f)) noconstant replace ///
mtitles("OLS" "FE" "Weight!=." "On_Support" "Weight_Reg") ///
title("基准回归及截面PSM-DID结果")
其中,频数加权回归除了可以使用Stata自带的fweight方法,还可以考虑直接将样本复制进而回归,这种思路来源于黄河泉(2017)在经管之家论坛的回答[17],最终结果与fweight方法完全一致。
gen weight = _weight * 2
replace weight = 1 if treated == 1 & _weight != .
keep if weight != .
expand weight
reghdfe TFPQD_OP FB $xlist , $regopt
est store m5
基准回归及截面PSM - DID回归结果如下。
--------------------------------------------------------------------------------------------
(1) (2) (3) (4) (5)
OLS FE Weight!=. On_Support Weight_Reg
--------------------------------------------------------------------------------------------
FB -0.1243*** -0.0496*** -0.0545*** -0.0497*** -0.0422***
(-5.2480) (-3.6531) (-3.9823) (-3.6550) (-2.9228)
ADM 1.0682*** 0.8719*** 0.9287*** 0.8719*** 0.9839***
(17.6388) (18.0260) (16.1842) (18.0262) (12.0535)
PPE -0.1183*** -0.0845*** -0.0784*** -0.0845*** -0.0813***
(-4.3488) (-5.4869) (-4.3384) (-5.4864) (-3.6168)
ADV 3.4239* 0.4029 1.6045 0.3975 2.3618
(1.9284) (0.2547) (0.8734) (0.2513) (0.9525)
RD -1.1993 -3.5116*** -3.4516** -3.4852*** -4.2360*
(-0.8120) (-2.6572) (-2.1919) (-2.6371) (-1.8977)
HHI -0.0284 0.1391*** 0.1347*** 0.1393*** 0.0702
(-0.5123) (3.7371) (3.2368) (3.7409) (1.3515)
INDSIZE 0.1061*** 0.0398*** 0.0425*** 0.0398*** 0.0541***
(6.4798) (5.1231) (5.1566) (5.1227) (5.1725)
NFIRMS -0.2011*** -0.1012*** -0.1048*** -0.1012*** -0.1324***
(-7.0272) (-8.2637) (-7.9029) (-8.2608) (-7.5215)
FCFIRM 0.2561** -0.0343 0.0229 -0.0335 0.0774
(2.5595) (-0.5604) (0.2952) (-0.5472) (0.6958)
MARGIN 0.2333*** 0.2377*** 0.2472*** 0.2377*** 0.2808***
(6.6555) (8.2641) (7.5753) (8.2641) (6.3765)
LEVDISP 1.8228*** 1.1270*** 1.1118*** 1.1271*** 1.0811***
(15.3788) (20.1912) (17.9101) (20.1920) (13.5927)
SIZEDISP 0.1373*** 0.0678*** 0.0667*** 0.0678*** 0.0785***
(5.2810) (4.5861) (4.0912) (4.5819) (3.8797)
ENTRYR 0.0735*** 0.0732*** 0.0573** 0.0732*** 0.0684***
(2.9277) (3.2806) (2.4976) (3.2805) (2.6353)
EXITR 0.0560* 0.0491* 0.0420 0.0492* -0.0326
(1.7687) (1.7444) (1.3206) (1.7474) (-0.8330)
--------------------------------------------------------------------------------------------
N 81567 81567 60078 81565 116882
r2_a 0.0646 0.1613 0.1548 0.1613 0.1592
--------------------------------------------------------------------------------------------
t statistics in parentheses
* p<0.1, ** p<0.05, *** p<0.01可以看到,核心解释变量外资银行进入(FB)在五个回归中均显著为负,且第(3)(4)(5)列FB系数值大小与第(2)列相差不大,其余控制变量的系数也符合预期,这说明当考虑到选择偏差问题后,基准回归结果依旧稳健。
此外,观察各回归中实际参与回归的样本数N可以发现,因为第(3)列使用的是权重不为空的样本,即PSM匹配成功的样本,因此样本量相比基础回归有所减少,且减少幅度较大;第(3)列使用的是满足共同支撑假设的样本,由于只有两个样本不满足假设,因此参与回归的样本只比基础回归少两个;第(4)列由于是根据权重进行的频数加权回归,实际参与回归的样本会根据权重进行复制,因此最终有116,882个样本参与回归。
2.3 逐年PSM – DID
逐年PSM – DID的整个流程与截面PSM – DID大致相似,也是通过PSM获得匹配后样本,然后再将样本代入DID模型中参与回归,最后比较回归结果以验证稳健性。
首先还是进行1:2的卡尺最近邻匹配。
**# 二、逐年匹配
use psmdata.dta, clear
**# 2.1 卡尺最近邻匹配(1:2)
forvalue i = 1998/2007{
preserve
capture {
keep if year == `i'
set seed 0000
gen norvar_2 = rnormal()
sort norvar_2
psmatch2 treated $xlist , outcome(TFPQD_OP) logit neighbor(2) ///
ties common ate caliper(0.05)
save `i'.dta, replace
}
restore
}
clear all
use 1998.dta, clear
forvalue k =1999/2007 {
capture {
append using `k'.dta
}
}
save ybydata.dta, replace
明显可以看出,与截面PSM – DID相比这里多了两个循环。
- 第一个循环的作用是逐年进行PSM,并将各年份PSM结果保存,最后获得1998年至2007年共10年的匹配后数据集。其中,preserve和restore方便高效使用数据,即不用在循环中写入use psmdata.dta, clear。capture{}是为了避免某些年份数据缺失导致Stata报错并停止运行,当然,这里的年份都是连续的。
- 第二个循环的作用是将各年份匹配后数据纵向合并至一个数据集中,生成我们回归需要的面板数据。capture{}的作用同上。
之后是绘制倾向得分值的核密度图(当然,先进行平衡性检验也行)。
**# 2.2 倾向得分值的核密度图
sum _pscore if treated == 1, detail // 处理组的倾向得分均值为0.5698
*- 匹配前
sum _pscore if treated == 0, detail
twoway(kdensity _pscore if treated == 1, lpattern(solid) ///
lcolor(black) ///
lwidth(thin) ///
scheme(qleanmono) ///
ytitle("{stSans:核}""{stSans:密}""{stSans:度}", ///
size(medlarge) orientation(h)) ///
xtitle("{stSans:匹配前的倾向得分值}", ///
size(medlarge)) ///
xline(0.5698 , lpattern(solid) lcolor(black)) ///
xline(`r(mean)', lpattern(dash) lcolor(black)) ///
saving(kensity_yby_before, replace)) ///
(kdensity _pscore if treated == 0, lpattern(dash)), ///
xlabel( , labsize(medlarge) format(%02.1f)) ///
ylabel(0(1)3, labsize(medlarge)) ///
legend(label(1 "{stSans:处理组}") ///
label(2 "{stSans:控制组}") ///
size(medlarge) position(1) symxsize(10))
graph export "kensity_yby_before.emf", replace
discard
*- 匹配后
sum _pscore if treated == 0 & _weight != ., detail
twoway(kdensity _pscore if treated == 1, lpattern(solid) ///
lcolor(black) ///
lwidth(thin) ///
scheme(qleanmono) ///
ytitle("{stSans:核}""{stSans:密}""{stSans:度}", ///
size(medlarge) orientation(h)) ///
xtitle("{stSans:匹配后的倾向得分值}", ///
size(medlarge)) ///
xline(0.5698 , lpattern(solid) lcolor(black)) ///
xline(`r(mean)', lpattern(dash) lcolor(black)) ///
saving(kensity_yby_after, replace)) ///
(kdensity _pscore if treated == 0 & _weight != ., lpattern(dash)), ///
xlabel( , labsize(medlarge) format(%02.1f)) ///
ylabel(0(1)3, labsize(medlarge)) ///
legend(label(1 "{stSans:处理组}") ///
label(2 "{stSans:控制组}") ///
size(medlarge) position(1) symxsize(10))
graph export "kensity_yby_after.emf", replace
discard
结果如图 6和图 7。

与截面PSM的结果类似,匹配前后两条核密度曲线偏差都比较大,但匹配后均值线距离缩短,两条曲线更加接近,因此一定程度上可以说明逐年匹配有效。
然后是逐年PSM的平衡性检验。
与截面PSM不同的是,由于逐年PSM是一年一年进行匹配的,因此考察各协变量在两组间是否存在系统性偏差只能在同一年份中进行比较,不同年份的匹配样本没有可比性,而且合并成面板数据后再进行平衡性检验Stata在技术上也不可行。这里参考谢申祥等(2021)的方法,比较匹配前后不同年份logit回归结果,即,如果匹配后各协变量的系数值减小、变得不显著和伪R方明显减小,则说明在不同年份两组的协变量不存在系统性偏差。
**# 2.3 逐年平衡性检验
*- 匹配前
forvalue i = 1998/2007 {
capture {
qui: logit treated $xlist i.ind3 if year == `i', vce(cluster prov)
est store ybyb`i'
}
}
local ybyblist ybyb1998 ybyb1999 ybyb2000 ybyb2001 ybyb2002 ///
ybyb2003 ybyb2004 ybyb2005 ybyb2006 ybyb2007
reg2docx `ybyblist' using 逐年平衡性检验结果_匹配前.docx, b(%6.4f) t(%6.4f) ///
scalars(N r2_p(%6.4f)) noconstant replace ///
indicate("Industry = *.ind3") ///
mtitles("1998b" "1999b" "2000b" "2001b" "2002b" ///
"2003b" "2004b" "2005b" "2006b" "2007b") ///
title("逐年平衡性检验_匹配前")
*- 匹配后
forvalue i = 1998/2007 {
capture {
qui: logit treated $xlist i.ind3 ///
if year == `i' & _weight != ., vce(cluster prov)
est store ybya`i'
}
}
local ybyalist ybya1998 ybya1999 ybya2000 ybya2001 ybya2002 ///
ybya2003 ybya2004 ybya2005 ybya2006 ybya2007
reg2docx `ybyalist' using 逐年平衡性检验结果_匹配后.docx, b(%6.4f) t(%6.4f) ///
scalars(N r2_p(%6.4f)) noconstant replace ///
indicate("Industry = *.ind3") ///
mtitles("1998a" "1999a" "2000a" "2001a" "2002a" ///
"2003a" "2004a" "2005a" "2006a" "2007a") ///
title("逐年平衡性检验_匹配后")
以上代码的运行结果如下。
*- 匹配前
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
(1) (2) (3) (4) (5) (6) (7) (8) (9) (10)
1998b 1999b 2000b 2001b 2002b 2003b 2004b 2005b 2006b 2007b
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
treated
ADM 2.2684*** 2.3222*** 2.0865*** 1.9288** 1.4294* 2.0740** 2.0784* 1.5288 2.3137 2.7268**
(2.7355) (2.5959) (2.8096) (2.4781) (1.9008) (2.0923) (1.9458) (0.9822) (1.3856) (2.1562)
PPE -0.5244** -0.3025 -0.7743*** -0.5716** -0.7099*** -0.6272** -1.0487*** -1.0451*** -0.8431* -0.9608**
(-2.2990) (-1.5852) (-3.4052) (-2.3569) (-2.6279) (-2.2244) (-3.5397) (-2.7774) (-1.9164) (-2.1682)
ADV 0.0000 0.0000 0.0000 13.4355 0.0000 0.0000 26.4667** 34.6121** 31.8339** 16.2578
(.) (.) (.) (1.0514) (.) (.) (2.4702) (2.2337) (2.2127) (1.2177)
RD 0.0000 0.0000 0.0000 10.9171 0.0000 0.0000 0.0000 -1.3296 14.1701 8.3546
(.) (.) (.) (1.2536) (.) (.) (.) (-0.1238) (1.5283) (0.7065)
HHI -1.6439* -1.6918** -1.1028 -1.2699 -1.0869 -0.6338 0.0072 0.0714 -0.0496 0.0429
(-1.7219) (-1.9652) (-1.3282) (-1.4922) (-1.4629) (-0.8633) (0.0148) (0.1513) (-0.0896) (0.0784)
INDSIZE 0.5445* 0.4829* 0.3557 0.3033 0.2376 0.1528 -0.2555 -0.0907 -0.1805 -0.2358
(1.7667) (1.8760) (1.4057) (1.1672) (0.9226) (0.6146) (-1.2398) (-0.4178) (-0.7170) (-0.9694)
NFIRMS -0.3930 -0.2420 0.0200 0.1023 0.2644 0.3734 0.9632*** 0.6899** 0.7769** 0.8697**
(-0.6612) (-0.4746) (0.0427) (0.2083) (0.5603) (0.8035) (2.7205) (1.9736) (2.0972) (2.4071)
FCFIRM 1.6635 0.7963 1.6429 1.1912 0.7410 0.6982 2.0390** 0.8335 1.1705 1.5674*
(0.9054) (0.4392) (1.1530) (0.6450) (0.5633) (0.6334) (2.1761) (0.6433) (1.3389) (1.6736)
MARGIN 1.5995*** 1.4034*** 1.0741*** 1.2462*** 0.4034 0.8745** 1.2484** -0.3829 0.7840 0.1712
(3.5296) (3.5031) (2.8690) (3.1566) (0.8275) (2.0900) (2.3096) (-0.3499) (0.6127) (0.1870)
LEVDISP -0.9378 -0.8800 -1.3296 -1.3270 -0.9001 -1.1339 -0.9631 -1.2057 -1.6036 -1.5013
(-0.4328) (-0.5331) (-0.7892) (-0.7769) (-0.5507) (-0.6717) (-0.5041) (-0.6542) (-0.9766) (-0.9726)
SIZEDISP -0.0741 0.0517 0.0790 0.1699 0.1840 0.1689 0.5612*** 0.3714 0.5487** 0.6102**
(-0.2874) (0.2080) (0.3297) (0.7125) (0.6938) (0.7498) (2.7553) (1.4051) (2.1442) (2.1618)
ENTRYR 0.0000 -0.0619 0.9535* 0.2964 0.0387 0.0183 0.0348 -0.6241 -0.6629** -0.6837**
(.) (-0.1157) (1.7572) (0.5243) (0.1305) (0.0435) (0.1230) (-0.6853) (-2.1473) (-2.3081)
EXITR -0.9139 0.7341 0.0460 -0.5761 -0.3070 0.2523 0.8344** 0.0524 -0.5910 -0.5330
(-1.1158) (1.1616) (0.0659) (-0.8138) (-0.6607) (0.4841) (2.0014) (0.1361) (-0.9383) (-0.7851)
_cons -8.6621*** -8.8834*** -7.3079*** -6.6187** -5.6780** -5.4720** -2.9528 -2.3179 -2.4977 -1.5174
(-2.7961) (-3.3483) (-2.6862) (-2.2210) (-2.1561) (-2.1240) (-1.0200) (-0.8532) (-0.7556) (-0.4968)
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Industry Yes Yes Yes Yes Yes Yes Yes Yes Yes Yes
N 6303 6600 6656 6845 7187 7601 9057 9428 10221 11207
r2_p 0.1321 0.1301 0.1337 0.1368 0.1369 0.1351 0.1578 0.1351 0.1314 0.1368
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
t statistics in parentheses
* p<0.1, ** p<0.05, *** p<0.01
*- 匹配后
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
(1) (2) (3) (4) (5) (6) (7) (8) (9) (10)
1998a 1999a 2000a 2001a 2002a 2003a 2004a 2005a 2006a 2007a
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
treated
ADM 0.8186 0.7099 1.0169 0.8462 0.1525 0.7434 0.0853 0.3600 0.8061 0.7568
(1.0061) (0.8124) (1.3867) (1.0619) (0.2048) (0.8235) (0.0714) (0.2385) (0.4899) (0.5814)
PPE 0.2349 0.3703* 0.1335 0.1864 0.2028 0.0637 -0.0651 -0.1128 -0.0983 -0.1607
(0.9089) (1.9154) (0.5660) (0.7556) (0.7784) (0.2231) (-0.2131) (-0.2964) (-0.2179) (-0.3868)
ADV 0.0000 0.0000 0.0000 6.5454 0.0000 0.0000 15.1587 4.7196 12.2655 -1.5428
(.) (.) (.) (0.6044) (.) (.) (1.3536) (0.2908) (0.8152) (-0.1188)
RD 0.0000 0.0000 0.0000 -8.3398 0.0000 0.0000 0.0000 -9.1278 -0.9288 -12.7757
(.) (.) (.) (-0.6978) (.) (.) (.) (-0.9596) (-0.0959) (-0.9324)
HHI -0.4786 -0.4828 -0.4323 -0.6529 -0.4950 -0.2469 -0.0630 -0.0505 0.2196 0.0863
(-0.5030) (-0.5685) (-0.5165) (-0.7708) (-0.6700) (-0.3173) (-0.1331) (-0.1042) (0.4048) (0.1496)
INDSIZE 0.2424 0.2039 0.0910 0.1361 0.1026 0.0569 -0.0786 0.0223 -0.0374 -0.1057
(0.7698) (0.8281) (0.3584) (0.5155) (0.3942) (0.2317) (-0.4091) (0.1061) (-0.1454) (-0.4386)
NFIRMS -0.1716 -0.0790 0.1095 0.0273 0.0924 0.1564 0.3901 0.2145 0.3206 0.4058
(-0.2827) (-0.1616) (0.2372) (0.0546) (0.1948) (0.3406) (1.1371) (0.6342) (0.8572) (1.1148)
FCFIRM 0.1643 -0.2306 -0.7050 -0.5302 -1.3960 -0.7499 -0.6088 -1.3333 -0.8095 -0.5513
(0.0941) (-0.1382) (-0.5092) (-0.3022) (-1.0856) (-0.7352) (-0.7719) (-1.0874) (-0.9200) (-0.6073)
MARGIN 1.1374** 0.7720* 0.7420* 0.5409 0.3343 0.4295 0.2948 -0.3597 0.3036 -0.0030
(2.3418) (1.7993) (1.9478) (1.2911) (0.6710) (1.0841) (0.5314) (-0.3368) (0.2356) (-0.0033)
LEVDISP -0.0022 0.2363 0.0725 0.5919 0.2944 0.4385 0.2644 0.2651 -0.0433 0.0963
(-0.0011) (0.1432) (0.0417) (0.3263) (0.1779) (0.2698) (0.1413) (0.1424) (-0.0264) (0.0619)
SIZEDISP -0.0387 0.0307 0.1642 0.1315 0.2040 0.2365 0.3054 0.1376 0.1875 0.2849
(-0.1369) (0.1286) (0.6774) (0.5625) (0.8189) (1.0679) (1.5141) (0.5676) (0.6690) (1.0209)
ENTRYR 0.0000 -0.0030 0.4019 0.0722 -0.2552 0.0391 -0.0099 -0.1736 -0.2510 -0.2626
(.) (-0.0054) (0.7407) (0.1290) (-0.8574) (0.0951) (-0.0325) (-0.2006) (-0.7387) (-0.9214)
EXITR -0.3475 0.1600 0.3100 -0.0141 -0.1314 0.2665 0.3176 0.1137 -0.0595 -0.1399
(-0.4376) (0.2422) (0.4429) (-0.0211) (-0.2864) (0.4944) (0.7820) (0.2809) (-0.0983) (-0.2001)
_cons -2.7021 -5.7169** -4.4212 -4.1241 -3.9158 -3.7323 -2.6553 -2.7141 -2.6220 -1.8506
(-0.9521) (-2.2631) (-1.6429) (-1.4217) (-1.4988) (-1.4734) (-0.9617) (-1.0106) (-0.7973) (-0.6046)
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Industry Yes Yes Yes Yes Yes Yes Yes Yes Yes Yes
N 4576 4769 4813 4889 5168 5557 6418 6732 7387 8048
r2_p 0.0907 0.0934 0.0894 0.0931 0.0878 0.0917 0.0951 0.0836 0.0767 0.0797
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
t statistics in parentheses
* p<0.1, ** p<0.05, *** p<0.01
可以看到,匹配后各年份绝大多数协变量的系数值减小(少数几个协变量因为共线性而被omitted),并且系数大多变得不显著,而且所有回归的伪R方明显减小,这说明在不同年份两组的协变量不存在系统性偏差。
最后是回归结果的对比。
**# 2.4 回归结果对比
use ybydata.dta, clear
*- 基准回归1(混合OLS)
qui: reg TFPQD_OP FB $xlist , cluster(city)
est store m1
*- 基准回归2(固定效应模型)
qui: reghdfe TFPQD_OP FB $xlist , $regopt
est store m2
*- PSM-DID1(使用权重不为空的样本)
qui: reghdfe TFPQD_OP FB $xlist if _weight != ., $regopt
est store m6
*- PSM-DID2(使用满足共同支撑假设的样本)
qui: reghdfe TFPQD_OP FB $xlist if _support == 1, $regopt
est store m7
*- PSM-DID3(使用频数加权回归)
gen weight = _weight * 2
replace weight = 1 if treated == 1 & _weight != .
qui: reghdfe TFPQD_OP FB $xlist [fweight = weight], $regopt
est store m8
*- 回归结果输出
local mlist_2 "m1 m2 m6 m7 m8"
reg2docx `mlist_2' using 逐年匹配回归结果对比.docx, b(%6.4f) t(%6.4f) ///
scalars(N r2_a(%6.4f)) noconstant replace ///
mtitles("OLS" "FE" "Weight!=." "On_Support" "Weight_Reg") ///
title("基准回归及逐年PSM-DID结果")
运行结果如下。回归结果与截面PSM – DID基本一致,因此也同样可以说明基准回归结果在考虑到选择偏差问题之后依然稳健。
--------------------------------------------------------------------------------------------
(1) (2) (3) (4) (5)
OLS FE Weight!=. On_Support Weight_Reg
--------------------------------------------------------------------------------------------
FB -0.1243*** -0.0496*** -0.0493*** -0.0498*** -0.0466***
(-5.2480) (-3.6531) (-3.5125) (-3.6669) (-3.1779)
ADM 1.0682*** 0.8719*** 0.8917*** 0.8712*** 0.9117***
(17.6388) (18.0260) (15.3250) (17.9650) (11.4538)
PPE -0.1183*** -0.0845*** -0.0899*** -0.0848*** -0.1136***
(-4.3488) (-5.4869) (-4.8695) (-5.5008) (-4.9564)
ADV 3.4239* 0.4029 0.3887 0.3767 4.4924
(1.9284) (0.2547) (0.1959) (0.2374) (1.5339)
RD -1.1993 -3.5116*** -5.1446*** -3.5391*** -5.2116**
(-0.8120) (-2.6572) (-2.9252) (-2.6649) (-2.1192)
HHI -0.0284 0.1391*** 0.1510*** 0.1392*** 0.0911*
(-0.5123) (3.7371) (3.6121) (3.7313) (1.7278)
INDSIZE 0.1061*** 0.0398*** 0.0363*** 0.0397*** 0.0459***
(6.4798) (5.1231) (4.1622) (5.1027) (4.3791)
NFIRMS -0.2011*** -0.1012*** -0.0975*** -0.1011*** -0.1199***
(-7.0272) (-8.2637) (-6.9857) (-8.2429) (-6.8619)
FCFIRM 0.2561** -0.0343 -0.1043 -0.0388 0.0600
(2.5595) (-0.5604) (-1.3284) (-0.6256) (0.6081)
MARGIN 0.2333*** 0.2377*** 0.2238*** 0.2368*** 0.3077***
(6.6555) (8.2641) (6.8292) (8.2343) (7.1966)
LEVDISP 1.8228*** 1.1270*** 1.1647*** 1.1270*** 1.1589***
(15.3788) (20.1912) (18.2101) (20.1705) (14.0951)
SIZEDISP 0.1373*** 0.0678*** 0.0637*** 0.0678*** 0.0712***
(5.2810) (4.5861) (3.8471) (4.5825) (3.5551)
ENTRYR 0.0735*** 0.0732*** 0.0635*** 0.0743*** 0.0563**
(2.9277) (3.2806) (2.6220) (3.3212) (2.0777)
EXITR 0.0560* 0.0491* 0.0468 0.0483* 0.0201
(1.7687) (1.7444) (1.4509) (1.7128) (0.4843)
--------------------------------------------------------------------------------------------
N 81567 81567 58926 81507 116269
r2_a 0.0646 0.1613 0.1548 0.1612 0.1590
--------------------------------------------------------------------------------------------
t statistics in parentheses
* p<0.1, ** p<0.05, *** p<0.01
参考资料
[1] Hansen的个人主页:
https://www.ssc.wisc.edu/~bhansen/econometrics/
[2] Rosenbaum & Rubin(1983)在Oxford Univ Press上的文章:
https://academic.oup.com/biomet/article/70/1/41/240879
[3] 陈强的个人主页:
http://www.econometrics-stata.com/
[4] 石大千等(2018)在CNKI上的文章:
[5] 王雄元和卜落凡(2019)在CNKI上的文章:
[6] 丁宁等(2020)在CNKI上的文章:
[7] 郭晔和房芳(2021)在CNKI上的文章:
[8] 孙琳琳等(2020)在CNKI上的文章:
[9] 陆菁等(2021)在CNKI上的文章:
[10] 余东升等(2021)在CNKI上的文章:
[11] Heyman et al.(2007)在WOS上的文章:
https://www.webofscience.com/wos/alldb/full-record/WOS:000251380600006
[12] Bockerman & Ilmakunnas(2009)在WOS上的文章:
https://www.webofscience.com/wos/alldb/full-record/WOS:000262706800003
[13] 谢申祥等(2021)在CNKI上的文章:
[14] 李青原和章尹赛楠(2021)在《中国工业经济》官网的原始数据:
http://ciejournal.ajcass.org/Magazine/show/?id=77331
[15] 李青原和肖泽华(2020)在CNKI上的文章:
[16] SSCC(2015)的一篇专题文章:
https://www.ssc.wisc.edu/sscc/pubs/stata_psmatch.htm
[17] 黄河泉(2017)在经管之家论坛的回答:
https://bbs.pinggu.org/thread-5693607-2-1.html
—
这期推送简单介绍一下我在以往清洗数据的过程中用过的一些野路子。
这期推文其实在上期之后就一直在构思,只是在实际落地的时候有一些小问题需要解决,然后这段时间又在忙其他事情,所以就一直拖到了现在……
1、下划线字体为链接,可点击跳转;2、推文中的公式与代码块均可左右滑动;3、该文首发于微信公众号
DMETP,欢迎关注;4、文中所有外部命令均可通过以下方式获得,以高维固定效应估计命令reghdfe为例:
*- 法一:
ssc install reghdfe, replace
*- 法二:
findit reghdfe
*- 法三:
search reghdfe< 目录 >
一、数据格式转换与合并
当我们从EPS中国微观经济数据查询系统[1]按照单年数据查询下载好每一年的csv文件后,假设我们按照年份把这些csv文件分别放到不同的文件夹中,接下来的事情就是把这些csv文件统一转化为dta文件,再将这些同一年份的dta文件纵向append到一个dta文件中。
往期推送的解决方案是:
- 首先,利用批处理对文件重命名;
- 其次,使用StatTransfer软件将
csv文件转为dta文件; - 最后,在Stata中修正乱码并使用
for循环进行多个数据集的纵向合并。
整体来看,这样的操作比较繁乱,而且特别容易出错。事实上,Stata有一个csvconvert外部命令能够同时进行多个csv文件的转换与合并,极大地方便了我们的数据清洗工作(除了不能修正乱码)。下面结合工企数据库对该命令进行简要介绍。
首先,在桌面创建一个文件夹,并将其命名为exp,在该文件夹中再创建两个子文件夹:
- 一是
raw_data文件夹,raw_data中再分别按照年份创建16个孙文件夹(1998-2013年),分别存放我们下载好的对应年份的原始数据。 - 二是
temp_data文件夹,用于存放我们操作过程中产生的缓存数据。
其次,在Stata中定义原始数据及缓存数据存放路径的全局暂元。
global path C:\Users\KEMOSABE\Desktop\exp
global raw_path $path\raw_data
global temp_path $path\temp_data之后,结合循环语句和csvconvert命令将原始数据合并为16个dta文件。
forvalue i = 1998/2013 {
capture csvconvert $raw_path\\`i' , ///
replace output_dir( $temp_path ) output_file(`i')
}以1998年为例:
$raw_path\\1998是1998年所有原始数据存放的路径,在子路径和孙路径中间加两个\的原因是,如果只加一个\,Stata将自动忽略这个符号从而报错。replace代表替代该路径下的同名文件。output_dir( $temp_path )代表输出的缓存文件的存放路径,这里是C:\Users\KEMOSABE\Desktop\exp\temp_data。output_file(1998)代表该缓存文件命名为1998。
整体来看,csvconvert命令确实比之前的方法要简便。但是,一个不能忽视的问题是,在我们得到这16年的dta文件之后,任意打开一个文件可以发现乱码的现象是普遍存在的,包括所有变量名称、字符型数据和标签。之前的方法可以使用Stata自带的转码命令进行转码,但是通过csvconvert输出的数据集却只能对标签进行转码,我尝试了几乎所有能找到的方法,但这些方法都不能奏效。针对这个顽疾,欢迎各位读者在公众号后台与我交流!
二、OP法计算企业TFP
OP法测算TFP的常用外部命令是opreg,在该命令下需要企业退出变量Exit,Exit的取值规则是:若企业在下一年退出市场且于观察期内不复进入时取1,否则取0;特别地,当企业在观测期末年仍旧存续时取0。以工企数据库为例,存在以下四种情况:
- 情况一,企业只有单年观测值( singleton ),也就是说,某企业在1998-2013年这16年的观测区间内只有一年观测值。对于这种样本,
Exit的取值情况不影响回归结果,因为在参与回归时单年观测值将被自动剔除(除非强行不剔除,如reghdfe命令下使用keepsingletons选择项,但这样的后果是统计显著性有偏)。在这里,我们将其取1。 - 情况二,企业存在两年及以上观测值,并且这些观测值在时间上连续,如某企业在2001、2002和2003年这三年内存续,并且在2003年以后不存在(无论其原因是退出市场还是数据本身的缺陷)。对于这种情况,我们令
Exit在2001年和2002年取0,2003年取1。 - 情况三,企业存在两年及以上观测值,并且这些观测值在时间上不连续,如某企业在2001、2002和2004年这三年内存续,并且在2004年以后不存在。在这种情况下,我们令
Exit在2001年和2002年取0,2004年取1。对于间断的年份(如这里的2003年),我们认为企业在这些间断年份内仍旧保持存续,数据缺失不表明企业不存续。 - 情况四,特别地,如果某企业在2013年存在观测值,由于我们无法得知企业在2014年的存续状态,因此我们令
Exit在2013年取0。
我们以一个手工生成的数据集为例。
clear all
input id year emp
1 2011 1
2 2008 0
2 2009 0
2 2010 0
2 2011 0
2 2012 0
2 2013 0
3 2008 0
3 2010 0
3 2011 0
3 2012 0
3 2013 0
4 2008 0
4 2011 0
4 2012 0
4 2013 0
5 2008 0
5 2009 0
5 2011 0
5 2012 0
5 2013 0
6 2008 0
6 2009 0
6 2010 0
6 2011 0
6 2012 1
7 2006 0
7 2007 1
end
list, sepby(id)其中,变量emp是企业实际的存续状况,其取值与后面创建的Exit变量保持一致。可以看到,个体1符合上文中的情况一;个体2符合情况二和情况四;个体3、4和5符合情况三和情况四;个体6和个体7符合情况二。
下面是创建Exit变量的代码。
xtset id year
bysort id: gen Exit = (_n == _N)
replace Exit = 0 if year == 2013
bro可以看到,Exit的取值与emp保持一致。
事实上,opreg命令的编写者Yasar et al.(2008[2];2012)[3]也提供了变量Exit的生成方法。下面是参照Yasar et al.(2008;2012)的方法生成工企数据库企业退出变量exit的代码。
[2] Yasar M, Raciborski R, Poi B. Production Function Estimation in Stata Using the Olley and Pakes Method[J]. Stata Journal, 2008, 8(02): 221-231.
[3] Software Updates[J]. Stata Journal, 2012, 12(01): 167-167.
xtset id year
sort id year
by id: gen count = _N
gen survivor = (count == 16)
gen has98 = 1 if year == 2013
sort id has98
by id: replace has98 = 1 if has98[_n-1] == 1
replace has98 = 0 if has98 == .
sort id year
by id: gen has_gaps = 1 if year[_n-1] != year-1 & _n != 1
sort id has_gaps
by id: replace has_gaps = 1 if has_gaps[_n-1] == 1
replace has_gaps = 0 if has_gaps == .
sort id year
by id: gen exit = (survivor == 0 & has98 == 0 & has_gaps != 1 & _n == _N)
replace exit = 0 if exit == 1 & year == 2013
drop count survivor has98 has_gaps
bro可以看到,emp、Exit和exit保持一致。
此外,部分研究者在生成Exit变量时,直接将存续年份不连续的样本剔除,关于这种做法的理论与文献基础我暂时没有找到,因此其合理性存疑。下面的实现代码借鉴了黄河泉老师(2021)[4]在经管之家论坛的回答。若有必要,这段代码在Exit生成之前运行即可。
xtset id year
gen d = 1
tsfill
bysort id: egen tem1 = count(d)
bysort id: gen tem2 = _N
keep if tem1 == tem2
drop d tem1 tem2 // 剔除存续序列不连续的样本,该步骤的必要性与合理性存疑OP法测算企业TFP,除了上文介绍的opreg命令,prodest这个外部命令也能实现,且不需要加入Exit变量。prodest除了可以使用OP法测算TFP,还可以使用LP法、WRDG法、MR法、以及OP法和LP法的ACF修正法,具体方法与使用细节可以键入help prodest进行了解。
值得一提的是,在实际测算中,OP、LP、WRDG和MR方法测算的TFP基本保持一致,但ACF法测算的结果与前面几种相比存在较大偏差。篇幅所限,这几种测算方法的结果对比推文没有贴出来。
三、截取字符串生成新变量
假设有一个字符型变量,在该变量下的数据为字母与数字的混合组合,且长度不一致。现在的需求就是,生成两个新变量,其中一个变量记录字符型变量的字母部分;另外一个变量记录字符型变量的数字部分,且将变量类型改为数值型。
最初的想法是使用substr()函数,但问题是字符型变量的长度不一致,而substr()函数只能截取固定位置的信息,也就是说,substr()函数要求变量的长度保持一致。这里将尝试使用正则表达式(regular expression)。
还是以一个手工生成的数据集为例。
clear all
input str8 x
"abc"
"123"
"abc123"
"123abc"
"a1b2c3"
"1a2b3c"
end可以看到,该数据集的唯一变量x有多个字符串组合,包括纯字母、纯数字、前字母后数字、前数字后字母以及其他组合类型。下面的实现代码专门针对前三种组合,至于后面几种组合,利用正则表达式也能实现。
gen x1 = regexs(0) if regexm(x, "^([a-z]*)([0-9]*)$")
gen x2 = regexs(1) if regexm(x, "^([a-z]*)([0-9]*)$")
gen x3 = regexs(2) if regexm(x, "^([a-z]*)([0-9]*)$")
destring x3, replace
list, separator(6)
bro
/*
+-----------------------------+
| x x1 x2 x3 |
|-----------------------------|
1. | abc abc abc . |
2. | 123 123 123 |
3. | abc123 abc123 abc 123 |
4. | 123abc . |
5. | a1b2c3 . |
6. | 1a2b3c . |
+-----------------------------+
*/可以看到,x2和x3就是我们需要的变量。
下面对代码进行解释,由于这里只是正则表达式的简单应用,因此不会做过多分析,但若能够熟练使用该方法,在处理数据时帮助会很大。键入help string_functions详细了解。
regexs(#)提示截取信息的位置,#等于0说明截取regexm()中逗号前的内容;#等于1说明截取逗号后第一个括号内的内容;#等于2说明截取逗号后第二个括号内的内容。regex()提示信息截取的具体内容,双引号内^表示开始,$表示结束;[a-z]表示字母,[0-9]表示数字;*表示截取0个及以上的数字或字母。
四、永续盘存法测算投资额
使用OP法估计企业TFP时,须引入企业投资额作为不可观测生产率冲击的代理变量,以缓解模型中可能存在的同时性偏差(Simultaneity)(Olley & Pakes,1996)[5]。
[5] Olley G S, Pakes A. The Dynamics of Productivity in the Telecommunications Equipment Industry[J]. Econometrica, 1996, 64(06): 1263-1297.
因此,在使用OP法估计工业企业TFP时,固定资产投资额是一个必须变量,但在工企数据库中,不存在固定资产投资额字段。一个常见的方法是使用永续盘存法(Perpetual Inventory Method,PIM)间接测算,公式如下:
有两点比较关键的说明:
- 第一,
为企业在年的固定资产合计或固定资产净值(这里选择固定资产合计),式说明上一年观测值缺失的样本无法计算当年的,因为上一年的固定资产合计数据无法获得,但对于在整个观测区间内至少存在两年观测值的样本(仅有单年观测值的样本在参与回归时将自动被剔除),年的企业固定资产合计可以以企业固定资产的平均增长率进行估算,假定平均增长率为,则(张天华和张少华,2016)[6]。在这里,企业在年的固定资产增长率计算公式如下式,其中与在年份不连续的情况下其差值不等于1,即为
- 的组内均值。
- 第二,
为经济折旧率,对的选择是充满有争议的。根据经济学领域的常用选择,可以将经济折旧率设定为9.6%(张军等,2004[7];何兴强等,2014[8])。但存在的问题是,张军等(2004)测算的9.6%是各省固定资本形成总额的经济折旧率,也就是说,该数值没有细分到具体地区,也不是我们关注的制造业行业,更关键地,该折旧率的时间跨度为1952-2000年。因此,为了增强估计结果的稳健性,还应该参考其他文献的做法来设定
- ,如5%(邵宜航等,2013)[9]、10%(肖文和林高榜,2014[10];李青原和章尹赛楠,2021)[11]和15%(聂辉华等,2012)[12]。
[6] 张天华, 张少华. 中国工业企业全要素生产率的稳健估计[J]. 世界经济, 2016, 39(04): 44-69.
[7] 张军, 吴桂英, 张吉鹏. 中国省际物质资本存量估算:1952—2000[J]. 经济研究, 2004(10): 35-44.
[8] 何兴强, 欧燕, 史卫, 刘阳. FDI技术溢出与中国吸收能力门槛研究[J]. 世界经济, 2014, 37(10): 52-76.
[9] 邵宜航, 步晓宁, 张天华. 资源配置扭曲与中国工业全要素生产率——基于工业企业数据库再测算[J]. 中国工业经济, 2013(12): 39-51.
[10] 肖文, 林高榜. 政府支持、研发管理与技术创新效率——基于中国工业行业的实证分析[J]. 管理世界, 2014(04): 71-80.
[11] 李青原, 章尹赛楠. 金融开放与资源配置效率——来自外资银行进入中国的证据[J]. 中国工业经济, 2021(05): 95-113.
[12] 聂辉华, 江艇, 杨汝岱. 中国工业企业数据库的使用现状和潜在问题[J]. 世界经济, 2012, 35(05): 142-158.
下面以一个手动生成的数据集为例。
clear all
input id year
1 2011
2 2008
2 2009
2 2010
2 2011
2 2012
2 2013
3 2008
3 2011
3 2012
3 2013
4 2008
4 2013
5 2008
5 2009
5 2011
5 2012
5 2013
6 2008
6 2009
6 2010
6 2011
6 2012
7 2006
7 2007
end
set seed 2021
gen asset = abs(rnormal())可以看到,个体1只有单年观测值,个体3、4和5的样本年份不连续。如果按照一般的方法使用PIM测算企业固定资产投资额,全部个体在样本初年的指标均无法计算,且年份不连续的个体在年份开始初年的指标也无法计算,如个体3在2011年的固定资产投资额无法计算。
sort id year
bys id: gen growth = (asset[_n] - asset[_n-1]) / (asset[_n-1] * (year[_n] - year[_n-1]))
xtset id year
tsfill
tsappend, add(1)
bys id: replace year = year[1] - 1 if _n == _N
sort id year
bys id: egen growth_mean = mean(growth)
bys id: gen ceiling = 1 if _n == _N
gen asset_hypo = asset
bys id: replace asset_hypo = asset_hypo[_n+1] / (1 + growth_mean) ///
if asset == . & asset[_n+1] != . & ceiling != 1
*- 经济折旧率δ = 9.6%(张军等,2004)
bys id: gen investment1 = asset_hypo - asset_hypo[_n-1] * (1 - 0.096)
*- 经济折旧率δ = 5%(邵宜航等,2013)
bys id: gen investment2 = asset_hypo - asset_hypo[_n-1] * (1 - 0.05)
*- 经济折旧率δ = 10%(肖文和林高榜,2014;李青原和章尹赛楠,2021)
bys id: gen investment3 = asset_hypo - asset_hypo[_n-1] * (1 - 0.1)
*- 经济折旧率δ = 15%(聂辉华等,2012)
bys id: gen investment4 = asset_hypo - asset_hypo[_n-1] * (1 - 0.15)
label var investment1 "经济折旧率取9.6%时测算的固定资产投资额"
label var investment2 "经济折旧率取5%时测算的固定资产投资额"
label var investment3 "经济折旧率取10%时测算的固定资产投资额"
label var investment4 "经济折旧率取15%时测算的固定资产投资额"
drop growth growth_mean ceiling asset_hypo
drop if asset == .
list, sepby(id)
*- 只有单年观测值的个体参与回归时将被剔除
sum invest*
#delimit ;
twoway (kdensity investment1)
(kdensity investment2)
(kdensity investment3)
(kdensity investment4)
;
#delimit cr
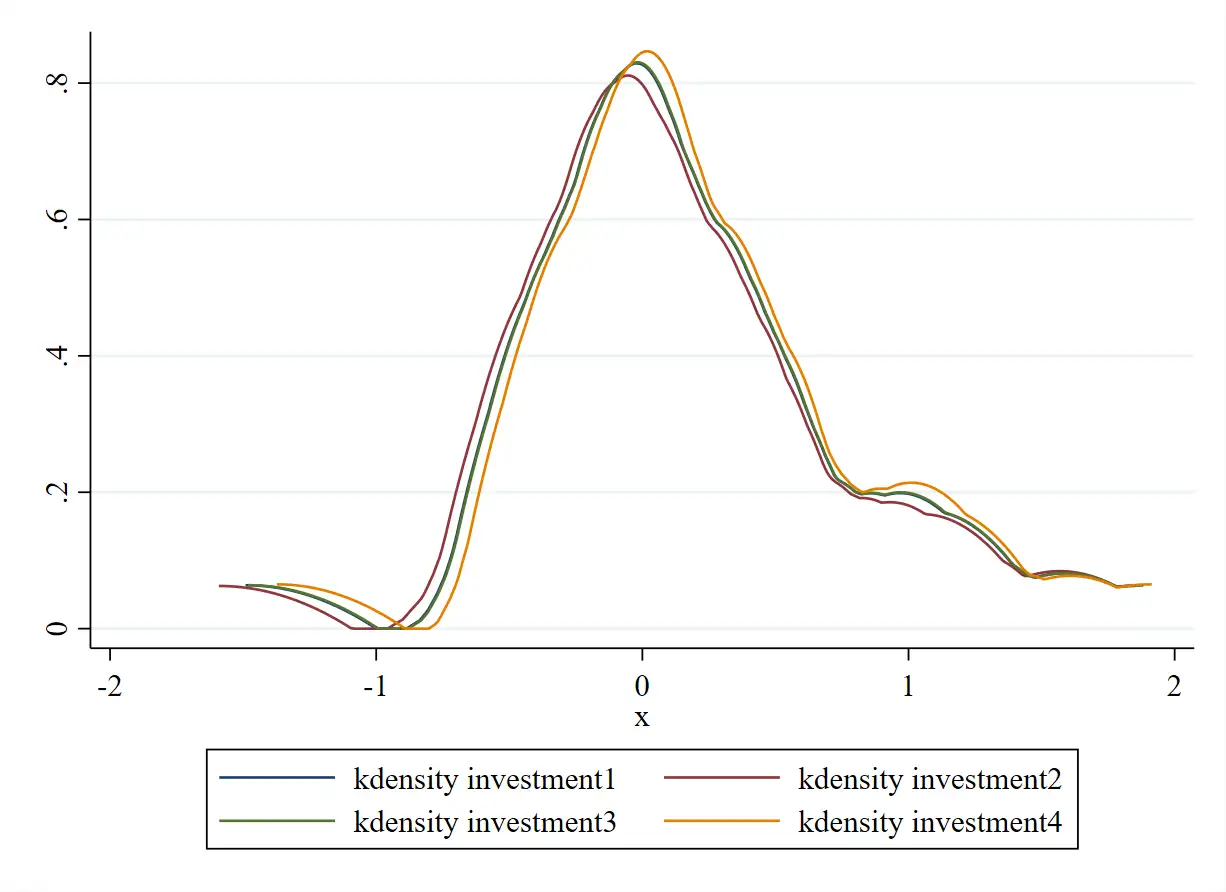
bro其中,growth为,growth_mean为的组内均值
,四个investment#即是不同经济折旧率下测算的固定资产投资额。
下面以核密度曲线图来直观呈现这四个investment#的偏离程度,如图 1。可见,这四个investment#的核密度曲线基本重合,也就是说,对于手动生成的数据集,在
这个区间选择任意一个折旧率进行测算结果均基本保持一致。

五、货币型变量的指数平减
阅读以下文字前,建议把如何对变量进行指数平减弄懂,可参考知乎用户『无宇』个人主页的第一个回答[13]。
这里以一份手工生成的数据集为例,该数据集包含两个个体1997-2019年的工业增加值,这两个个体所属省份均为安徽省(二位数行政区划代码为34),工业增加值以当年价格计算,因此需要进行指数平减,平减工业增加值的常用指数为工业品出厂价格指数PPI。
version 17
clear all
set obs 20
set seed 2021
gen id = 1 in 1/10
replace id = 2 in 11/20
bys id: gen year = 1996 + _n
gen province = 1
gen VA = abs(rnormal())
label var VA "工业增加值(当年价格)"对工业增加值进行指数平减的大致思路可以分为两步:
- 第一步,将上年=100的
PPI转为1997=1; - 第二步,利用
PPI(1997 = 1)对货币型变量进行指数平减。
由于指数平减涉及两个数据集的数据处理与合并,因此下面将使用框架(frame)进行操作。当然,对单个数据集分别进行处理,然后再横向merge到一个数据集也是可行的做法。
需要说明的是,frame是Stata 16新加入的功能,Stata 15及以下版本无法使用。Stata中frame的功能类似于Excel的工作表sheet,方便在同一个操作窗口中打开多份数据集并对数据集进行处理,而不需另外加载Stata软件打开数据集。
先简单介绍一下Stata中的frame系列命令,具体信息请键入help frame进行了解。
frame dir:显示内存中所有的框架;frame pwf:显示当前正在工作的框架,pwf和frame作用与之相同;frame create newfraname:创建一个新的框架,并命名为newfraname,mkf newfraname作用与其一致;frame drop franame:删除框架franame,但不可删除当前工作框架;frame change franame:将工作框架转换到franame,cwf franame作用与之相同;frame rename oldfraname newfraname:重命名框架;frame franame: command或frame franame {command}在框架franame下运行命令;frlink:通过连接变量linkvar建立两个框架之间的连接;frget: 通过连接变量将其他框架中的数据复制到当前工作框架中,一般与frlink配合使用,两者的配合使用功能类似于merge命令进行横向合并(append)。
mkf ppi
frame ppi {
input province year ppi
34 1997 99.4
34 1998 96.4
34 1999 92.9
34 2000 98.9
34 2001 98.6
34 2002 99.82
34 2003 103.5
34 2004 108.16
34 2005 103.25
34 2006 103.07
34 2007 103.6
34 2008 108.4
34 2009 92.8
34 2010 108.98
34 2011 108.3
34 2012 98.26
34 2013 98.16
34 2014 97.4
34 2015 93.94
34 2016 98.5
34 2017 108
34 2018 103.03
34 2019 100.3
end
replace ppi = ppi / 100
label var ppi "工业品出厂价格指数(上年 = 1)"
sort province year
gen ppi97 = ppi
bys province: replace ppi97 = 1 if _n
bys province: replace ppi97 = ppi97[_n-1] * ppi if _n != 1
label var ppi97 "工业品出厂价格指数(1997 = 1)"
format ppi* %6.4f
list
}
frame dir
pwf
frlink m:1 province year, frame(ppi) gen(linkid)
frget ppi97, from(linkid)
gen VA1 = VA / ppi97
label var VA1 "工业增加值(可比价格)"
bro其中,linkid是两个框架之间建立联系的关键连接变量,ppi97是以1997年为基期的PPI,VA1是经指数平减后的工业增加值,因此该变量在不同年份可比。
——-
双重差分倾向得分匹配(PSM-DID)简介
双重差分PSM模型是由Heckman et al(1997,1998)提出的。假设存在两期面板数据,实验前的时期记为t’,实验后的数据记为t。对于控制组合处理组在t’时期,其潜在结果均为yot‘,但是在t时期的时候存在两种潜在结果即,控制组为y0t,处理组为y1t。
双重差分PSM模型成立的假设为:
如果以上假定成立,则可以得到ATT的一致估计:
步骤
双重差分PSM的估计步骤大致如下:
(1)根据处理变量D和协变量X计算倾向得分
(2)对于处理组的每个个体i确定与其匹配的全部控制组个体(即确定集合Sp)
(3)对于处理组的每位个体i,计算其结果变量前后变化
(4)对于处理组的每个个体i,计算与其匹配的全部控制个体的前后变化
(5)针对(3)和(4)中的公式,根据以上公式进行倾向得分核匹配或局部线性回归匹配,即可得到ATT
优点:控制不可观测但不随时间变化的组间差异。例如处理组和控制组来自两个不通过的区域,或者处理组或者控制组使用了两套调查问卷。
操作
**PSM_DID
ssc install diff
help diff
***双重差分语法格式***
diff outcome_var ,treat(varname) period(varame) id(varname) ///
kernel ktype(kernel) cov(varlist) report logit support test
解释
其中“outcome_var”表示结果变量,“treat(varname) ”为必选项,用来指定处理变量,“period(varame)”用来指定实验期虚拟变量(1=实验期,0=非实验期),“id(varname)”用来指定个体id(这是进行匹配的前提),“kernel”表示使用核匹配方法(diff命令不提供其他匹配方法),“cov(varlist)”用来指定倾向得分的协变量,“report”表示汇报倾向得分的估计结果,“logit”表示使用logit计算得分,默认选项为probit,“support”表示仅使用共同取值范围内的观测值进行匹配,“test”表示检验倾向得分匹配之后的,各变量在实验组和控制在分布是否平衡。
演示
***PSM_DID
ssc install diff
help diff
***双重差分语法格式***
diff outcome_var ,treat(varname) period(varame) id(varname) ///
kernel ktype(kernel) cov(varlist) report logit support test
use cardkrueger1994.dta
bro
des
sum
diff fte ,t(treated) p(t) kernel id(id) logit cov(bk kfc roys) ///
report support
diff fte ,t(treated) p(t) kernel id(id) logit cov(bk kfc roys) ///
report support test
sssssss
https://www.zhihu.com/question/337458812
PSM-DID 模型是由倾向得分匹配模型 (Propensity Score Matching,以下简称 PSM) 和双重差分模型 (Differences-in-Differences,以下简称 DID) 结合而成。其中,PSM 负责为受处理的个体筛选对照个体,DID 负责识别政策冲击所产生的影响。
然而,二者在适用范围方面并不相同,即 PSM 模型适用于截面数据,而 DID 模型适用于面板数据。传统基于面板数据转化为截面数据再匹配的方案和基于面板数据逐期匹配的方案,都容易产生 “自匹配” 现象或匹配对象在政策前后不一致的问题。
为此,本文将阐述 PSM-DID 模型在应用中出现的问题,并探究这些问题出现的原因。在此基础上,本文也将提出一种可行的改进方案
应用中的问题和原因
PSM 适用于截面数据,而 DID 适用于面板数据。针对二者适用范围不同的问题,学者们一般有两种解决方案:
- 一是将面板数据直接转化为截面数据进行处理;
- 二是在面板数据的每期截面上进行逐期匹配。
“自匹配” 问题
将面板数据直接转化为截面数据处理,会产生不同期样本匹配的问题,这使得最终的识别结果中掺杂了大量时间趋势信息。
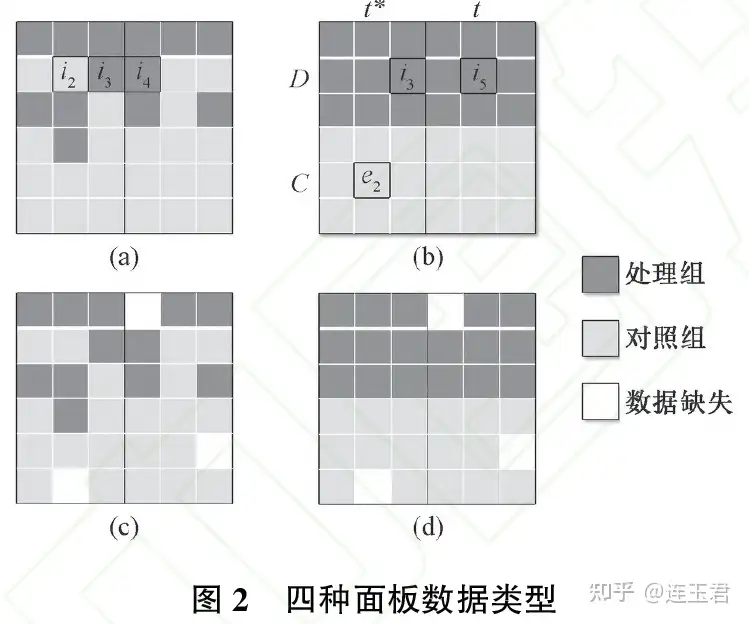
以图 2 为例,将面板数据划分为 、、、 四种结构类型。其中, 和 属于半衡面板数据,并且
更为特 殊,其处理组和对照组都是平衡面板数据,本文称之为 “双平衡” 面板数据。(c) 和 (d) 是 (a) 和 (b) 存在部分数据缺失的情 况,均属于非平衡面板数据。
在 (a) 类数据结构下,个体 存在不同时期分别属于处理组和对照组的情况。如果将面板数据直接转化为截面数据,并采用 “1:1 最近邻” 的匹配方式,处理组 和 都将会以极大的概率与对照组 匹配在一起。这是因为与现在的个体 最相似 的必然是过去 (或末来) 的个体
,本文将这种个体自身不同时期之间相互匹配的情况称之为 “自匹配” 现象。上述现象将会 造成较为严重的匹配偏误,具体理由如下:
识别结果 是原受处理个体结果变量 的直接相减。如果 存在明显的时间趋势,且出现 “自匹配” 现象的个体较 多,则识别结果中必然掺杂着大量时间趋势信息,这种情况类似于时间序列分析中的“伪回归”。而且,匹配变量
越多, 给予的约束越强,发生 “自匹配” 的概率就越大。
对于(b)类 “双平衡” 数据结构而言,将面板数据转化为截面数据进行匹配的方案虽然不会造成“自匹配” 问题,但其依然会 受到 “时间错配” 问题的困扰。例如在 (b) 中 和 都与 相匹配 (
)。
而 (c) 和 (d) 分别是 (a) 和 (b) 类数据结构中存在部分数据缺失的情况,在利用它们进行的回归当中,还会存在部分因数据 缺失而造成的偏误问题。
sssssss
https://zhuanlan.zhihu.com/p/389672688
简单谈一下我本人对空间双重差分模型(Spatial Difference in Difference Model,SDID)几点或许不太成熟的理解。
(本文首发于微信公众号DMETP,欢迎关注!)
一、从聚类标准误到空间相关性
当使用面板数据进行固定效应模型估计时,考虑到组间异方差和组内自相关,我们必然需要将标准误进行聚类调整。一般来说,聚类调整后的标准误大于异方差稳健标准误,而异方差稳健标准误大于普通标准误,因此,根据聚类标准误做出来的结果是相对最稳健的,这里所说的稳健,指的是系数显著性稳健,因为标准误影响t值,而对系数的本身影响不大。
然而,将标准误聚类调整到什么层次是一个问题。当将个体(id)作为聚类依据时,即假定每个个体不同年份的干扰项存在相关性(组内自相关),而不同个体的干扰项不存在相关性(组间不相关)。但是,这样的假定可能不符合现实情况,比如,对于微观企业来说,同一行业的企业之间必然存在竞合关系,此时同一行业不同企业之间就存在相关性,在这种情况下,将标准误聚类调整到行业层面可能更合理。因此,为了得出更稳健的结果,也为了说服苛刻的读者(或审稿人)接受我们根据实证结果得出的结论,将标准误聚类到更高层级是一种更安全的做法,当然,聚类层级越高系数越不显著。
然而,有时候我们没有甚至不能将标准误聚类到更高层级。除了显著性与稳健性之间的权衡,更多的原因在于聚类层级越高聚类数目越少,而大样本理论要求聚类数目足够大,这样才能保证所估计的标准误收敛到真实值(Petersen,2009[1]),根据拇指法则,聚类数少于30可能就不太合适了。
退而求其次,为了同时兼顾聚类层级与聚类数目,有些文献将标准误聚类到行业-年份层面(在Stata中可以利用分组函数group生成聚类变量再在回归中进行聚类调整,即:先egen ind_year = group(industry year),然后reghdfe y xlist, absorb(id year) cluster(ind_year)),如李青原和章尹赛楠(2021)[2]、邵朝对等(2021)[3],即假定同一年同一行业之间存在自相关,而不同年或不同行业之间不存在自相关。
参考文献:
[1] Petersen M A. Estimating Standard Errors in Finance Panel Data Sets: Comparing Approaches[J]. Review of Financial Studies, 2009, 22(01): 435-480.
[2] 李青原, 章尹赛楠. 金融开放与资源配置效率——来自外资银行进入中国的证据[J]. 中国工业经济, 2021(05): 95-113.
[3] 邵朝对, 苏丹妮, 杨琦. 外资进入对东道国本土企业的环境效应: 来自中国的证据[J]. 世界经济, 2021, 44(03): 32-60.
根据常识与理论将标准误聚类调整到行业-年份层面,即先验式地承认同一年份同一行业的企业存在相关性,同理,当聚类到省份-年份层面或区域-年份层面时,也可以认为同一年同一地区(省份或区域)不同个体之间存在相关性,这与构建空间计量模型(Spatial Econometric Model)的思想不谋而合。
空间计量模型最大的特征是放松了空间单位之间相互独立的假设,即认为本地区与邻近地区存在相互关系,本地区变量的变动不仅直接影响本地区,也会影响邻近地区,而且通过影响邻近地区最后反作用于本地区。本地区对本地区的影响称为直接效应(Direct Effect),本地区对邻近地区的平均影响称作间接影响或空间溢出效应(Indirect Effect or Spatial Spillover Effect)。对具体空间相关形式的判断,是在OLS模型的基础上对其残差进行拉格朗日乘子检验(LM test)和稳健的拉格朗日乘子检验(robust LM test),以检验OLS回归残差中是否存在某种形式的空间关联,即检验OLS回归残差中是否包含被解释变量的空间滞后项()抑或扰动项的空间滞后项(
)(Burridge,1980[4];Anselin,1988[5];Anselin at al.,1996[6];Elhorst,2014[7])。
参考文献:
[4] Burridge P. On the Cliff‐Ord Test for Spatial Correlation[J]. Journal of the Royal Statistical Society: Series B (Methodological), 1980, 42(01): 107-108.
[5] Anselin L: Spatial Dependence in Regression Error Terms, Anselin L, editor, Spatial Econometrics: Methods and Models, Dordrecht: Springer Netherlands, 1988: 100-118.
[6] Anselin L, Bera A K, Florax R, et al. Simple Diagnostic Tests for Spatial Dependence[J]. Regional Science & Urban Economics, 1996, 26(01): 77-104.
[7] Elhorst J P. Matlab Software for Spatial Panels[J]. International Regional Science Review, 2014, 37(03): 389-405.
因此,从这种意义上来说,当标准误聚类调整到地区-年份层面时,此时假定中的同一年份同一地区不同个体之间存在的相关性(组内自相关)本质上是一种空间相关性。也就是说,当我们将标准误聚类调整到地区-年份层面时,实质上就已经变相说明模型中存在一定的空间相关性。
二、个体处理效应稳定性假设
在DID中,一个经典的假设是个体处理效应稳定性假设(Stable Unit Treatment Value Assumption,SUTVA)。SUTVA最重要的一点是“处理组个体不会影响控制组个体”(Rubin,1974[8])。换言之,在SUTVA框架下,总体中的任何个体并不会受到其他个体接受处理与否的影响(王金杰和盛玉雪,2020[9])。然而,这个假设在考虑到空间相关性时被打破了,或者说,当不同空间单元之间存在相关性即存在空间溢出效应时,SUTVA不再成立(Kolak & Anselin,2019[10])。
参考文献:
[8] Rubin D B. Estimating Causal Effects of Treatments in Randomized and Nonrandomized Studies[J]. Journal of Educational Psychology, 1974, 66(05): 688-701.
[9] 王金杰, 盛玉雪. 社会治理与地方公共研发支出——基于空间倍差法的实证研究[J]. 南开经济研究, 2020, 1(01): 199-219.
[10] Kolak M, Anselin L. A Spatial Perspective on the Econometrics of Program Evaluation[J]. International Regional Science Review, 2019, 43(02): 128-153.
事实上,SUTVA在大多数情况下可能都不成立,而现有的DID类实证文章很少会考虑到这一点,并且Ferman(2020)[11]指出忽略空间相关性将导致标准误被低估,从而夸大系数的显著性。
参考文献:
[11] Ferman B. Inference in Differences-in-Differences: How Much Should We Trust in Independent Clusters? [R]. MPRA Paper 93746, University Library of Munich, Germany, 2020.
一个简单的道理,处理组在期初实施了某项政策,控制组没有实施,但不是说政策实施之后只会对处理组产生影响,通过示范、学习、要素流动等渠道也会作用于控制组,因此,政策的施行在长期将会在一个较广的区域范围内产生普遍(但不一致)的影响。
这里有两个问题,一个是政策实施对控制组作用的力度,另一个是作用的方向。
首先,在处理组实施的某项政策不会对全域内所有地区产生相同的影响,可能两地间经济联系越密切,政策的空间溢出效应越强;可能两地共享同一地理边界(邻接),空间溢出效应越明显;可能两地核心城市之间的地理距离或路程距离越短,空间溢出效应就越强。总之,政策的施行不会对其他地区产生一致的影响,而会随着某种空间相互关系的趋弱存在衰减效应,而我们论文中的SDID就是围绕这种空间相互关系进行研究设计的(空间权重矩阵的设置)。
其次,处理组实施的某项政策对邻近地区的影响有正有负。一方面,政策施行导致资源向先行区倾斜集聚,这不仅意味着先行地区内部资源的重新配置,而且也将导致邻近地区的资源(如劳动力、资金等)向该地区流动富集,这样的结果是抑制了邻近控制组的经济发展,形成了“虹吸效应”。另一方面,先行发展的示范区一般都是经济发展较好的地区(这同时说明DID可能存在严重的样本自选择问题!),政策实施后这些地区将已有的、相对落后的产能向周围转移,连带着将相关人才、技术与资金转移,通过这样的一种方式促进了邻近地区的发展,形成了所谓的“涓滴效应”。总之,政策的施行对邻近地区产生正反两方面的影响,而我们的工作就是要精准稳健地测度出这种影响,并进一步分析出这种异质性影响背后的形成机制或者说机理。
三、政策实施的空间溢出效应
下面结合几个实例给出SDID模型设计的参考。
空间计量模型中和DID结合最多的是自变量空间滞后模型(The Spatial Lag of X Model,SLX),而SLX是在普通线性模型等式右端引入(所有)自变量的空间滞后项,形如式
:
式中的即为所有自变量的空间滞后项,由于等式右端不包括被解释变量的空间滞后项,该模型可以视为普通的线性模型,并使用OLS方法进行估计。因此,式中的衡量的是直接效应的大小,
测度的是间接效应的大小(Vega & Elhorst,2015[12])。
参考文献:
[12] Vega S H, Elhorst J P. The SLX Model[J]. Journal of Regional Science, 2015, 55(03): 339-363.
SDID基于式,但等式右边只有DID交互项的空间滞后项,其余自变量均以其初始形式作为控制变量,形如式
:
其中,代表政策的直接效应,即绝大多数论文中所要考察的处理效应(Treatment Effect),而
代表政策的间接效应或空间溢出效应。
王金杰和盛玉雪(2020)在研究社会治理与地方公共研发支出的关系时,将十八届三中全会以来的社会治理作为准自然实验,设计了如下式
的实证模型。
其中,DID交互项()空间滞后项系数
衡量的是平均的溢出效应。
可以看出,形如和
的SDID只能测度平均的空间溢出效应,空间滞后项系数的大小代表了在所有处理组实施的政策对邻近地区的影响。从这个意义上来说,以上的研究设计本质上讨论的是空间依赖性,而非空间异质性,而对空间异质性的讨论或许是我们应该关注的重点,即:在处理组实施的某项政策,在多大范围内存在空间溢出效应?
沈坤荣和金刚(2018)[13]在评估河长制的水污染治理效果时,设计了如下式
的实证模型。
其中,表示阈值为的地理距离倒数矩阵元素,当地和
地之间的距离在阈值范围内,该元素取值为距离倒数,否则为0。
可以看出,形如式的SDID模型以100为步进距离,考察在不同地理阈值范围内空间溢出效应的大小。图 1是不同地理阈值范围内系数
的大小与显著性。
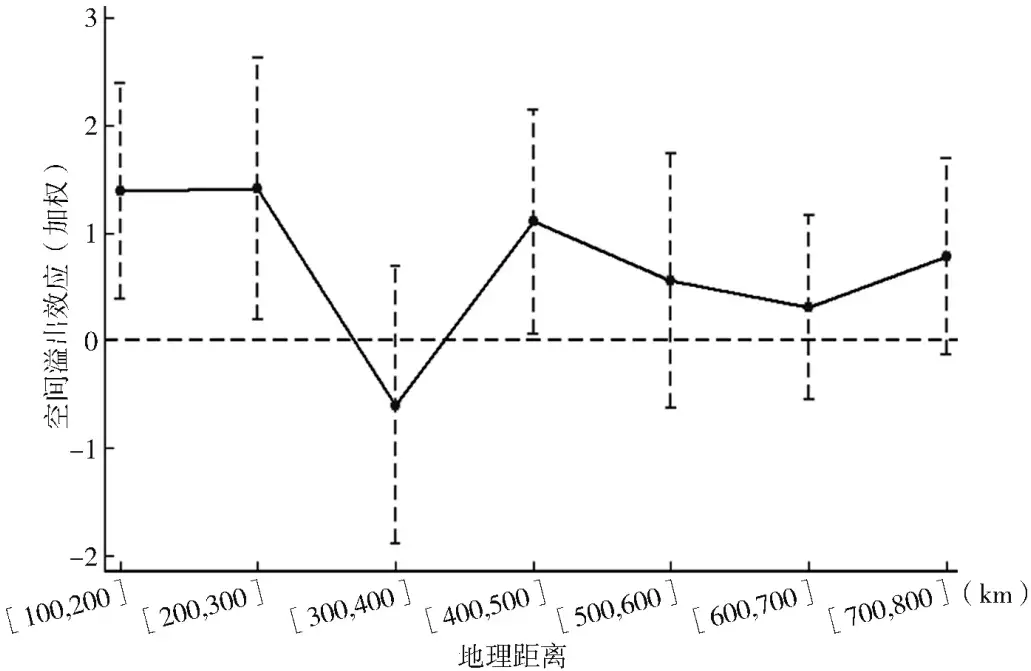
参考文献:
[13] 沈坤荣, 金刚. 中国地方政府环境治理的政策效应——基于“河长制”演进的研究[J]. 中国社会科学, 2018(05): 92-115+206.
然而,也有部分文献通过巧妙的模型设计,在不使用SDID的情况下,测度了不同阈值范围内政策实施的空间溢出效应。
曹清峰(2020)[14]在评估国家级新区的经济效应时,认为国家级新区通过空间溢出效应促进了区域协调发展。该文的实证模型设计如下式
:
其中,表示不同城市间的球面距离;如果在年距离城市的空间范围内存在国家级新区,,否则;系数衡量了国家级新区设立后对邻近城市经济增长率的影响。图 2是不同地理阈值范围内系数
的大小与显著性。
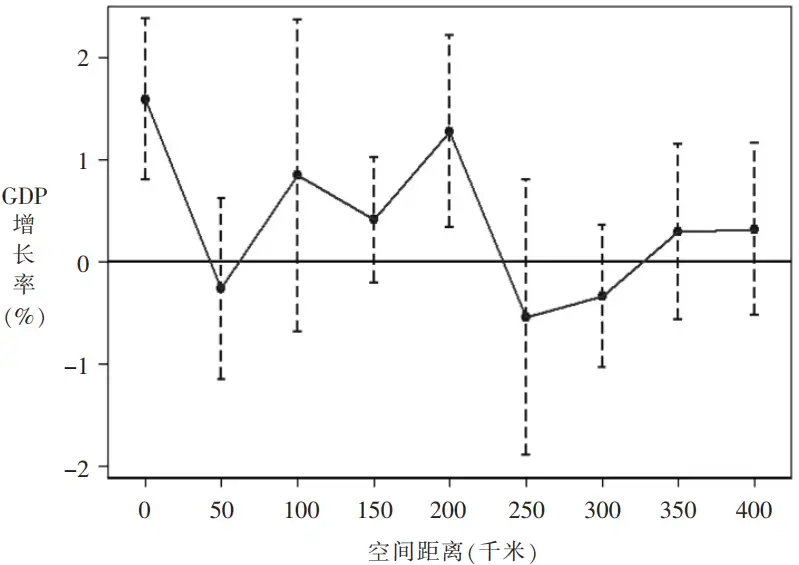
参考文献:
[14] 曹清峰. 国家级新区对区域经济增长的带动效应——基于70大中城市的经验证据[J]. 中国工业经济, 2020(07): 43-60.
ssss
简单介绍一下实证论文中双重差分法安慰剂检验(Placebo Test)在Stata中如何操作。
下面的内容根据实际使用的案例及数据集分为两个部分。
- 一是以一个截面数据集为例,介绍一下安慰剂检验的整个思路与流程。这里使用的是系统数据集
auto.dta,由于是简单介绍思路,因此该部分并没有第二部分面板数据那么复杂,且模型中不包括DID的交互项,仅仅是对一个核心变量rep78进行1,000次随机抽样 - 二是以一个面板数据集为例,介绍一下面板数据DID中安慰剂检验的整个流程。这里使用的数据集是石大千等(2018)[1]公布在《中国工业经济》网站上的附件内容。论文使用的模型是普通DID模型,也即政策发生时点(2012年)固定,处理组与控制组的设置也固定
参考文献:
石大千, 丁海, 卫平, 刘建江. 智慧城市建设能否降低环境污染[J]. 中国工业经济, 2018(06): 117-135.
一、安慰剂检验方法选择
通常而言,DID中的安慰剂检验方法包括两种。
- 一是改变政策发生时点,具体又包括前置处理组的政策发生时点,此时安慰剂检验的作用与平行趋势检验相同,都是考察政策发生前基础回归中时间虚拟变量与处理组交互项系数(
F(-1)、F(-2)、F(-3)、……)的显著性,如果不显著说明检验通过;还包括将政策发生时点随机化,也即将时点前置或后置,这是一种更一般化的做法 - 二是将处理组随机化,对处理组变量进行一定次数的随机抽样,然后再观测随机化后的DID项系数或观测值的核密度图是否集中分布于0附近,以及是否显著偏离其真实值
- 第二种方法更为常见,第一种方法的不足在于:如果样本期间较短,导致随机抽样的时段区间过短,得出的结论不一定真实,虽然抽样次数可以很多,但抽样空间过短将影响结论的稳健性。综合来说,对处理组进行随机化处理是一种更为合适的做法。当然,具体论文要具体分析
二、截面数据集的安慰剂检验
这部分代码使用的是Stata系统自带的数据集auto.dta,该数据集是截面数据且不包含DID项,在实际使用中,可以将reg改为面板数据回归命令(如xtreg、reghdfe等),同时将这里的核心解释变量rep78改为论文中需要进行随机化处理的关键变量。需要提醒的是,陆菁等(2021)[2]在随机化处理时,提到“DID模型估计要求政策实施年份前后至少有一年数据”,因此在时间窗口不长且需要进行安慰剂检验的情况下,需要特别注意这一点。
参考文献:
陆菁, 鄢云, 王韬璇. 绿色信贷政策的微观效应研究——基于技术创新与资源再配置的视角[J]. 中国工业经济, 2021(01): 174-192.
此外,代码部分还参考了李青原和章尹赛楠(2021)[3]发表在中国工业经济上的一篇文章的附件,同时还参考了简书的一位热心网友[4]写的文章。
参考文献:
李青原, 章尹赛楠. 金融开放与资源配置效率——来自外资银行进入中国的证据[J]. 中国工业经济, 2021(05): 95-113.
2.1 整体思路
- 第一步:在原始数据集
auto.dta中单独剔除核心变量rep78的样本数据 - 第二步:将剔除出来的
rep78随机打乱顺序,再将随机化的rep78合并至已被处理过的原始数据集中 - 第三步:将随机化的
rep78放入回归方程中进行回归 - 第四步:以上操作步骤重复1,000次
- 第五步:单独提取出1,000次回归结果中
rep78的系数与标准误,最后分别绘制系数和t值的核密度分布图以及P值 – 系数散点图
2.2 代码实现
*==============================================================================*
* 安慰剂检验 - 对核心解释变量进行1,000次随机抽样与回归 *
*==============================================================================*
** Stata Version: 16 | 17
** 【文章首发】这篇文章首发于本人微信公众号『DMETP』,是两篇推文的合辑,欢迎关注!
cd "C:\Users\KEMOSABE\Desktop\placebo_test"
**# 一、截面数据的安慰剂检验
**# 1.1 根据原始样本进行基础回归
sysuse auto.dta, clear
global ctrlvar1 "mpg headroom trunk weight length"
reg price rep78 $ctrlvar , r
*- 基础回归中核心变量rep78的真实系数与真实t值分别为:
*- 真实系数 = 889.6715
*- 真实t值 = 3.2206(可手动计算,也即889.6715 / 276.2438)
clear all
**# 1.2 对rep78进行1,000次随机抽样、回归并绘制核密度图
*- 思路:
*- a. 在原始数据集auto.dta中单独剔除核心变量rep78的样本数据
*- b. 将剔除出来的rep78随机打乱顺序,再将随机化的rep78合并至已被处理过的原始数据集中
*- c. 将随机化的rep78放入回归方程中进行回归
*- d. 以上操作步骤重复1,000次
*- e. 单独提取出1,000次回归结果中rep78的系数与标准误,最后分别绘制系数和t值的核密度估计图以及P值与系数的散点图
set seed 13579 // 设置随机种子数
forvalue i = 1/1000 {
sysuse auto.dta, clear
preserve
gen randomvar = runiform()
sort randomvar
gen id = _n
label var id "用于匹配的样本序号"
keep rep78 id
save rep78_random.dta, replace // 该数据集中仅保留rep78和随机化的id
// id用于将该数据集中的rep78横向合并(merge)至原数据集
restore
gen id = _n
label var id "用于匹配的样本序号"
drop rep78
save rep78_dropped.dta, replace // 原数据集中已剔除rep78字段
use rep78_dropped.dta, clear
merge 1:1 id using rep78_random.dta, keepusing(rep78) // 将随机化排序的rep78合并至原数据集
qui reg price rep78 $ctrlvar1 , r
gen b_rep78 = _b[rep78] // 提取回归后rep78的系数
gen se_rep78 = _se[rep78] // 提取回归后rep78的标准误
keep b_rep78 se_rep78
duplicates drop b_rep78, force
save placebo_`i'.dta, replace
}
erase rep78_random.dta
erase rep78_dropped.dta
use placebo_1.dta, clear
forvalue k = 2/1000 {
append using placebo_`k'.dta // 将1,000次回归中rep78的系数和标准误纵向合并(append)至单独的数据集(placebo_1.dta)
erase placebo_`k'.dta
}
graph set window fontface "Times New Roman"
graph set window fontfacesans "宋体" // 设置图形输出的字体
gen tvalue = b_rep78 / se_rep78
gen pvalue = 2 * ttail(e(df_r), abs(tvalue)) // 计算t值和P值
**# 1.2.1 系数
sum b_rep78, detail
twoway(kdensity b_rep78, ///
xline(`r(mean)', lpattern(dash) lcolor(black)) ///
xline(889.6715 , lpattern(solid) lcolor(black)) ///
scheme(qleanmono) ///
xtitle("{stSans:系数}" , size(medlarge)) ///
ytitle("{stSans:核}""{stSans:密}""{stSans:度}", size(medlarge) orientation(h)) ///
saving(placebo_test_Coefficient1, replace)), ///
xlabel(, labsize(medlarge)) ///
ylabel(, labsize(medlarge) format(%05.4f)) // 绘制1,000次回归rep78的系数的核密度图
graph export "placebo_test_Coefficient1.png", replace // 导出为矢量图,方便论文中的图形展示;medlarge可以改为large以将标题文字加大
**# 1.2.2 P值
sum b_rep78, detail
twoway(scatter pvalue b_rep78, ///
msy(oh) mcolor(black) ///
xline(`r(mean)', lpattern(dash) lcolor(black)) ///
xline(889.6715 , lpattern(solid) lcolor(black)) ///
yline(0.1 , lpattern(shortdash) lcolor(black)) ///
scheme(qleanmono) ///
xtitle("{stSans:系数}" , size(medlarge)) ///
ytitle("{stSans:P}""{stSans:值}" , size(medlarge) orientation(h)) ///
saving(placebo_test_Pvalue1, replace)), ///
xlabel( , labsize(medlarge)) ///
ylabel(0(0.25)1, labsize(medlarge) format(%03.2f))
graph export "placebo_test_Pvalue1.png", replace
**# 1.2.3 t值
sum tvalue, detail
twoway(kdensity tvalue, ///
xline(`r(mean)', lpattern(dash) lcolor(black)) ///
xline(3.2206 , lpattern(solid) lcolor(black)) ///
xline(-1.65 , lpattern(shortdash) lcolor(black)) ///
xline( 1.65 , lpattern(shortdash) lcolor(black)) ///
scheme(qleanmono) ///
xtitle("{stSans:t值}" , size(medlarge)) ///
ytitle("{stSans:核}""{stSans:密}""{stSans:度}", size(medlarge) orientation(h)) ///
saving(placebo_test_Tvalue1, replace)), ///
xlabel(, labsize(medlarge)) ///
ylabel(, labsize(medlarge) format(%02.1f)) // 绘制1,000次回归rep78的t值的核密度图
graph export "placebo_test_Tvalue1.png", replace
erase placebo_1.dta
discard
clear all
cls
2.3 运行结果与解读
以上这段代码的运行结果是3张图,如下所示。其中图 1是系数的核密度估计图;图 2是P值 – 系数散点图;图 3是t值的核密度估计图。
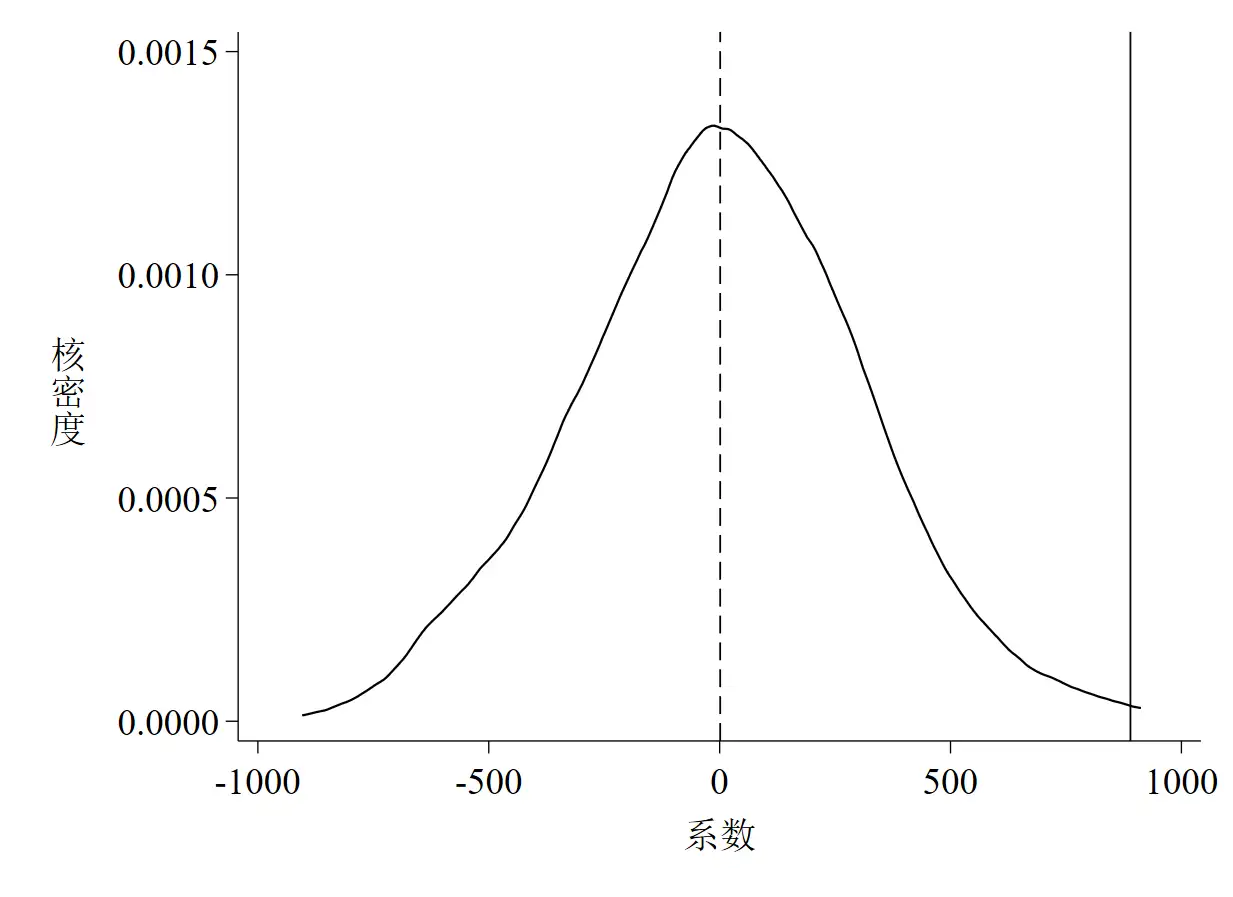
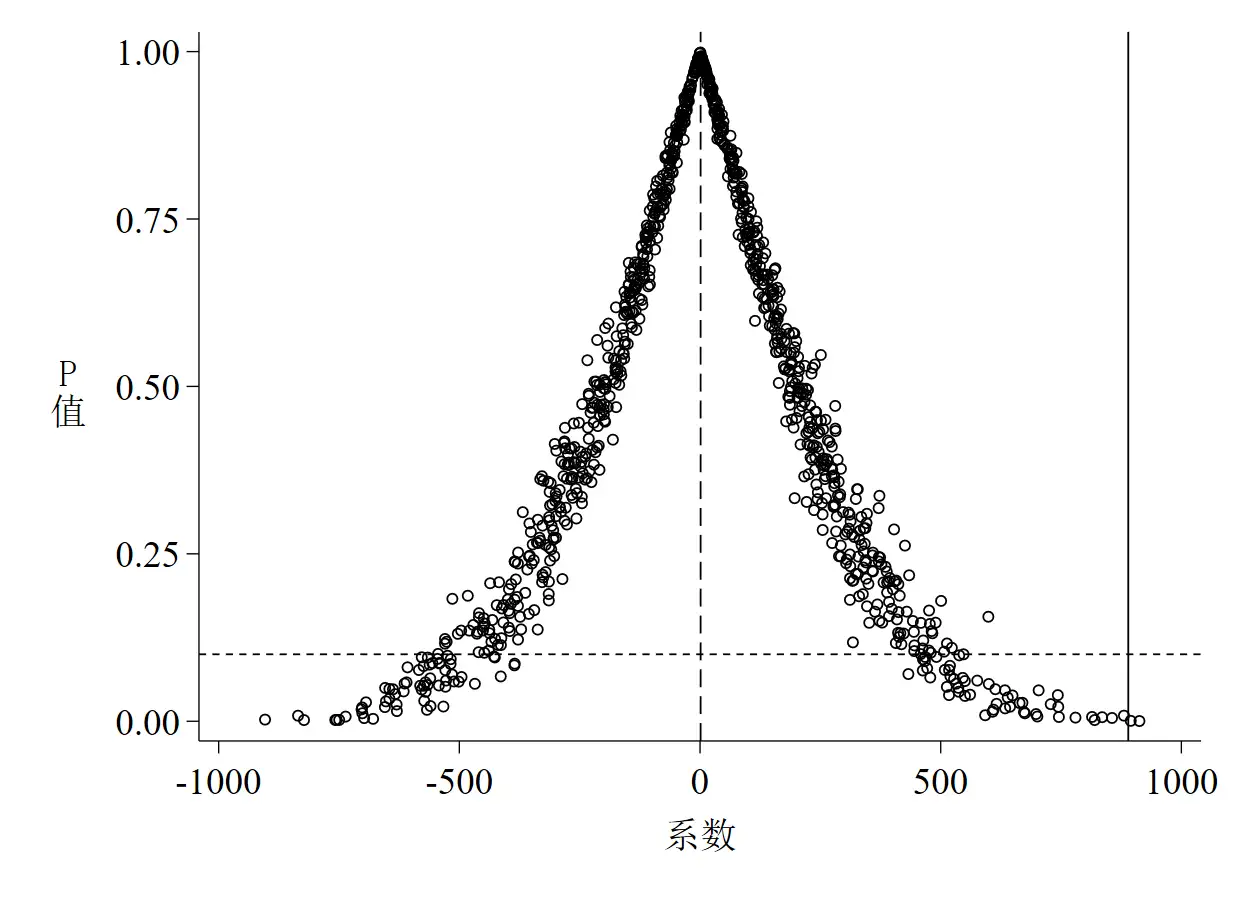
针对图 1至图 3的解读如下:
- 随机化核心解释变量后系数与t值的核密度估计值的均值都接近于0(分别为1.2233和0.0029)
- 随机化后系数与t值的核密度估计值的均值都大大偏离其真实值(真实值分别为889.6715和3.2206)
- 随机化后多数系数的P值位于
P value = 0.1线以上,说明多数系数至少在10%的水平下不显著 - 以上三点均说明
rep78对price的影响不是由其他不可观测因素(或遗漏变量)推动的 - 设置随机种子数为13,579时,可重复以上结果并得出一致结论
- 从P值的散点图可以得到以下两点信息:
- 第一,更多的散点集中分布于0附近,而位于真实值垂直线上的散点只有几个,这说明在随机化后真实值是一个异常点
- 第二,虽然多数散点集中于0附近,但这些散点所代表的系数至少在10%的水平上是不显著的
三、面板数据集的安慰剂检验
前面一部分介绍了安慰剂检验的具体操作,但都是以一个截面数据集(auto.dta)作为示例的,且模型中没有加入DID的交互项,因此严格来说这个例子还不太恰当。这里用一个具体例子介绍面板数据双重差分模型中的安慰剂检验,这个例子是一个普通DID模型,政策发生时点固定,处理组和控制组也是固定的,相对而言模型设置比较简单,但也可以延伸至相对复杂的DID模型中(如多期DID、连续DID和广义DID等),所需的可能仅仅是要发挥更多的想象力。
原始数据来源于石大千(2018),但这篇文章和中国工业经济官网放出来的附件都没有详细解释处理组和控制组的具体设置,因此虽然可以用gen dt = (year >= 2012)生成政策发生时间虚拟变量,但处理组虚拟变量(du)无法生成,因此这里使用的是公众号『功夫计量经济学』提供的数据[5],数据有效性本人无法保证,这里只作为一个示例。
关于论文的具体内容详见参考文献,这里不做介绍,也可以快速浏览『功夫计量经济学』的相关推文。值得一提的是,『功夫计量经济学』给出了另外一种随机抽样的方法,可以与本推送给出的方案对照阅读。
这里设置了一个随机种子(seed),方便复现结果与推送内容保持一致,随机种子数是223,至于为什么是这个数,纯粹是试错试出来的,因为设置成这个数画出来的图最好看。
3.1 整体思路
- 第一步:在原始数据集
smart_city2018.dta中单独剔除变量id的样本数据 - 第二步:将剔除出来的
id随机打乱顺序,再将随机化的id合并至已被处理过的原始数据集中 - 第三步:将随机化的
treat与dt的交互项(did)放入回归方程中进行回归 - 第四步:以上操作步骤重复1,000次
- 第五步:单独提取出1,000次回归结果后
did的系数与标准误,最后分别绘制系数和t值的核密度估计图以及P值与系数的散点图
3.2 代码实现
*==============================================================================*
* 安慰剂检验 - 对核心解释变量进行1,000次随机抽样与回归 *
*==============================================================================*
** Stata Version: 16 | 17
** 【文章首发】这篇文章首发于本人微信公众号『DMETP』,是两篇推文的合辑,欢迎关注!
**# 二、面板数据的安慰剂检验
*- 【原始数据来源】石大千, 丁海, 卫平, 刘建江. 智慧城市建设能否降低环境污染[J]. 中国工业经济, 2018(06): 117-135.
* 《中国工业经济》附件下载地址:http://ciejournal.ajcass.org/Magazine/show/?id=54281
*- 【加工数据来源】微信公众号『功夫计量经济学』2021.4.20推送文章“双重差分法(DID)安慰剂检验的做法:随机抽取500次”
* 微信公众号推文地址:https://mp.weixin.qq.com/s/06v6s90G1pp-yLju_yAy1Q
cd "C:\Users\KEMOSABE\Desktop\placebo_test\example"
**# 2.1 基础回归
use smart_city2018.dta, clear
global ctrlvars2 "lnrgdp lninno lnurb lnopen lnss"
reghdfe lnrso dudt $ctrlvars2 , absorb(id year) cluster(id)
*- 基础回归中核心变量dudt的真实系数与真实t值分别为:
*- 真实系数 = -0.1706
*- 真实t值 = -2.1245(可手动计算,即-0.1706 / 0.0803)
discard
**# 2.2 安慰剂检验
*- 思路:
*- a. 在原始数据集smart_city2018.dta中单独剔除变量id的样本数据
*- b. 将剔除出来的id随机打乱顺序,再将随机化的id合并至已被处理过的原始数据集中
*- c. 将随机化的treat与dt的交互项(did)放入回归方程中进行回归
*- d. 以上操作步骤重复1,000次
*- e. 单独提取出1,000次回归结果后did的系数与标准误,最后分别绘制did系数和t值的核密度估计图以及P值与系数的散点图
set seed 223 // 设置随机种子数
forvalue i = 1/1000 {
use smart_city2018.dta, clear
preserve
keep if year == 2005
gen randomvar = runiform()
sort randomvar
keep if id in 1/32
keep id
save id_random.dta, replace // 数据集仅保留随机化后的id
restore
merge m:1 id using id_random.dta // 将随机化id合并至原数据集
gen treat = (_merge == 3)
gen did = treat * dt
qui reghdfe lnrso did $ctrlvars2 , absorb(id year) cluster(id)
gen b_did = _b[did] // 提取单次回归后did的系数
gen se_did = _se[did] // 提取单次回归后did的标准误
keep b_did se_did
duplicates drop b_did, force
save placebo_`i'.dta, replace
}
erase id_random.dta
use placebo_1.dta, clear
forvalue k = 2/1000 {
append using placebo_`k'.dta // 将1,000次回归后did的系数和标准误纵向合并(append)至单独的数据集(placebo_1.dta)
erase placebo_`k'.dta
}
graph set window fontface "Times New Roman"
graph set window fontfacesans "宋体" // 设置图形输出的字体
gen tvalue = b_did / se_did
gen pvalue = 2 * ttail(e(df_r), abs(tvalue)) // 计算t值和P值
**# 2.2.1 系数
sum b_did, detail
twoway(kdensity b_did, ///
xline(`r(mean)', lpattern(dash) lcolor(black)) ///
xline(-0.1706 , lpattern(solid) lcolor(black)) ///
scheme(qleanmono) ///
xtitle("{stSans:系数}" , size(medlarge)) ///
ytitle("{stSans:核}""{stSans:密}""{stSans:度}", size(medlarge) orientation(h)) ///
saving(placebo_test_Coefficient2, replace)), ///
xlabel(, labsize(medlarge) format(%02.1f)) ///
ylabel(, labsize(medlarge) format(%02.1f)) // 绘制1,000次回归did的系数的核密度图
graph export "placebo_test_Coefficient2.png", replace // 导出为矢量图,方便论文中的图形展示;可改medlarge为large以加大字体
**# 2.2.2 P值
sum b_did, detail
twoway(scatter pvalue b_did, ///
msy(oh) mcolor(black) ///
xline(`r(mean)', lpattern(dash) lcolor(black)) ///
xline(-0.1706 , lpattern(solid) lcolor(black)) ///
yline( 0.1 , lpattern(shortdash) lcolor(black)) ///
scheme(qleanmono) ///
xtitle("{stSans:系数}" , size(medlarge)) ///
ytitle("{stSans:P}""{stSans:值}" , size(medlarge) orientation(h)) ///
saving(placebo_test_Pvalue2, replace)), ///
xlabel( , labsize(medlarge) format(%02.1f)) ///
ylabel(0(0.25)1, labsize(medlarge) format(%03.2f))
graph export "placebo_test_Pvalue2.png", replace
**# 2.2.3 t值
sum tvalue, detail
twoway(kdensity tvalue, ///
xline(`r(mean)', lpattern(dash) lcolor(black)) ///
xline(-2.1245 , lpattern(solid) lcolor(black)) ///
xline(-1.65 , lpattern(shortdash) lcolor(black)) ///
xline( 1.65 , lpattern(shortdash) lcolor(black)) ///
scheme(qleanmono) ///
xtitle("{stSans:t值}" , size(medlarge)) ///
ytitle("{stSans:核}""{stSans:密}""{stSans:度}", size(medlarge) orientation(h)) ///
saving(placebo_test_Tvalue2, replace)), ///
xlabel(, labsize(medlarge)) ///
ylabel(, labsize(medlarge) format(%02.1f)) // 绘制1,000次回归did的t值的核密度图
graph export "placebo_test_Tvalue2.png", replace
erase placebo_1.dta
3.3 运行结果与解读
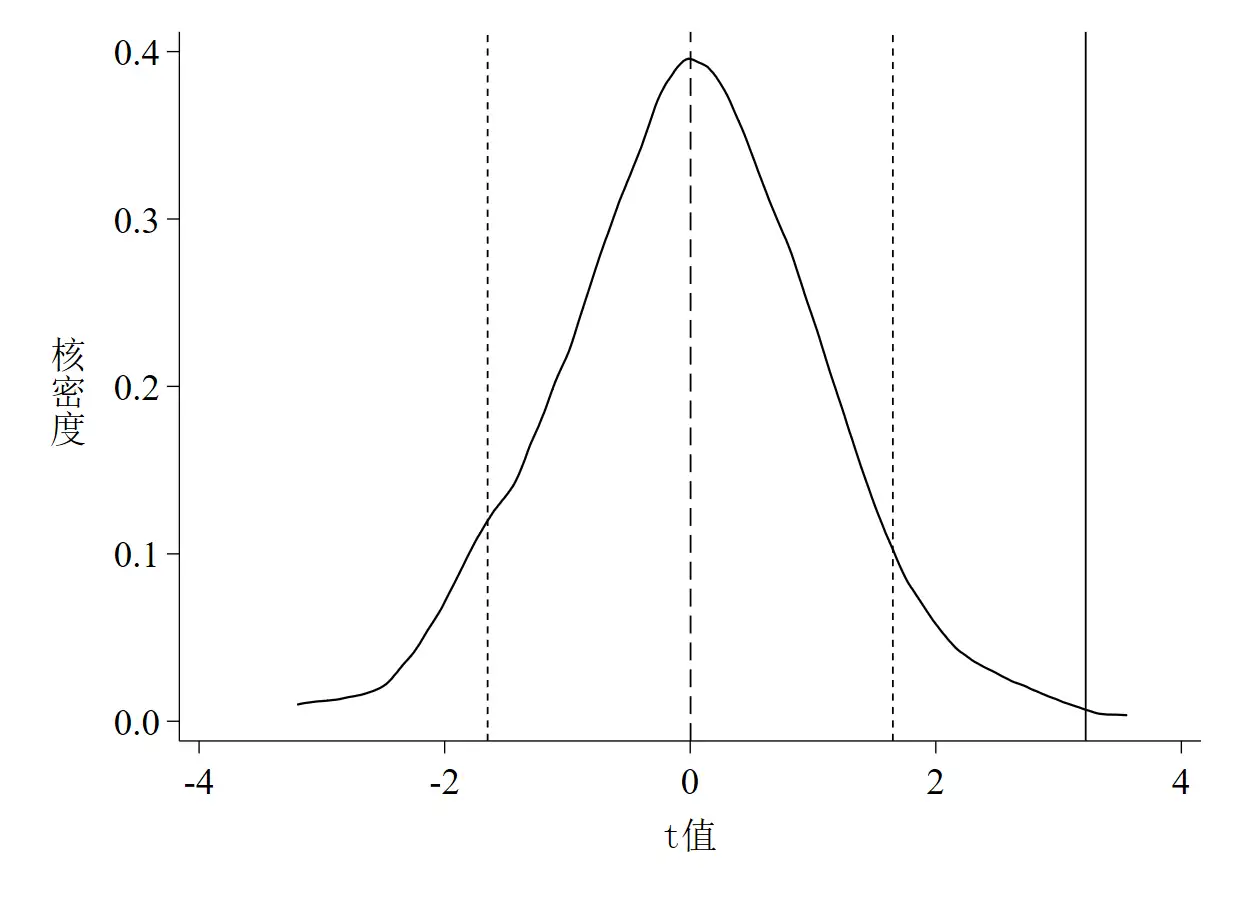
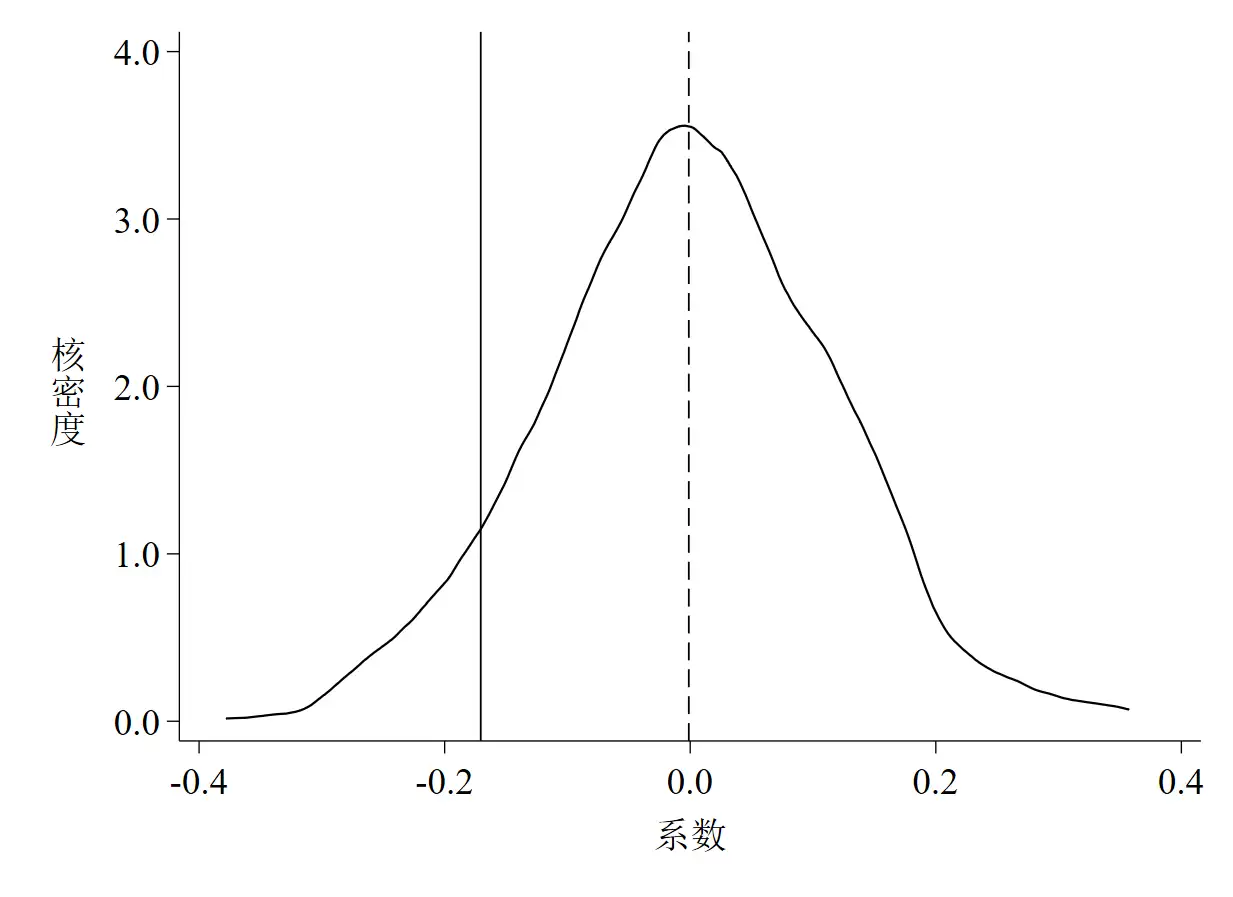
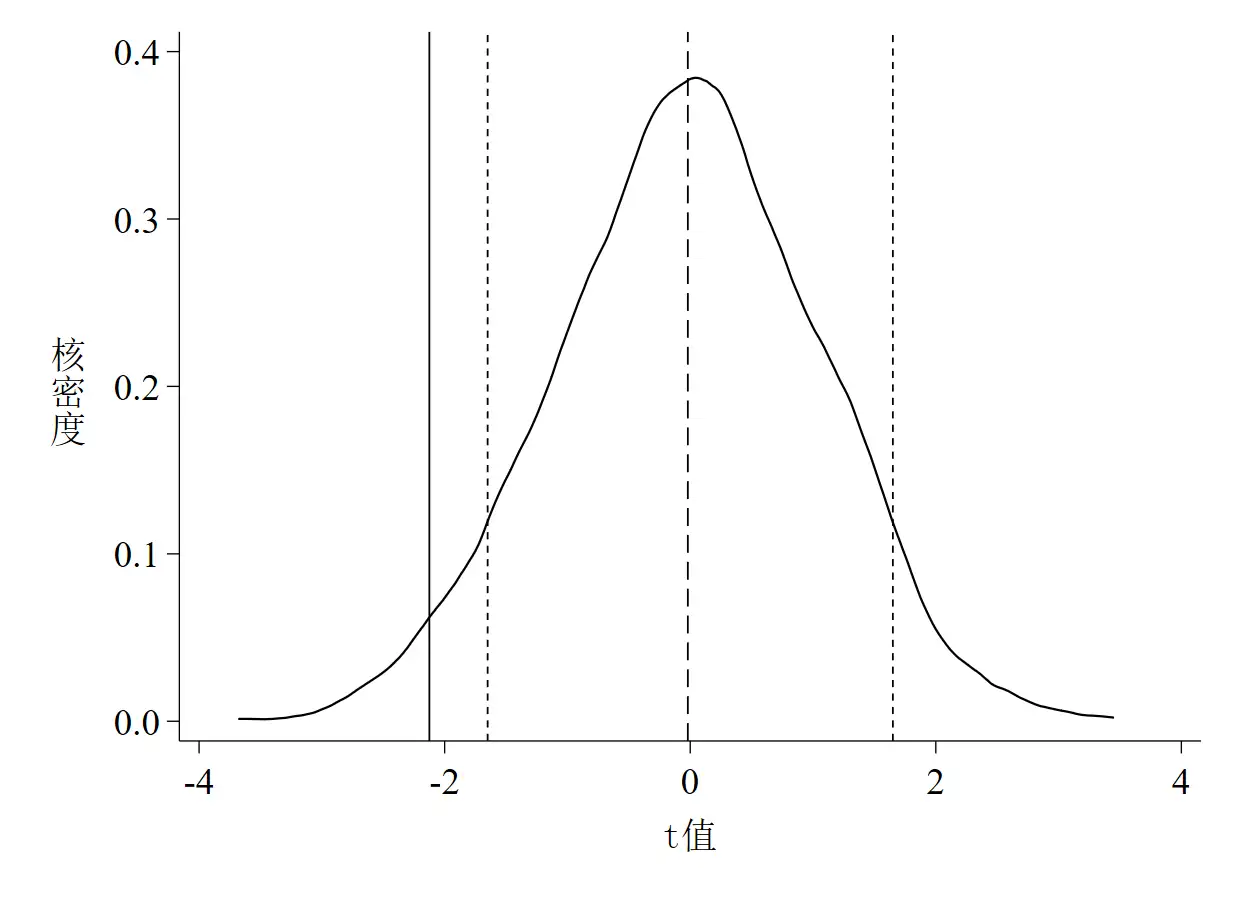
同样,以上代码的运行结果是3张图,如下图 4至图 6。
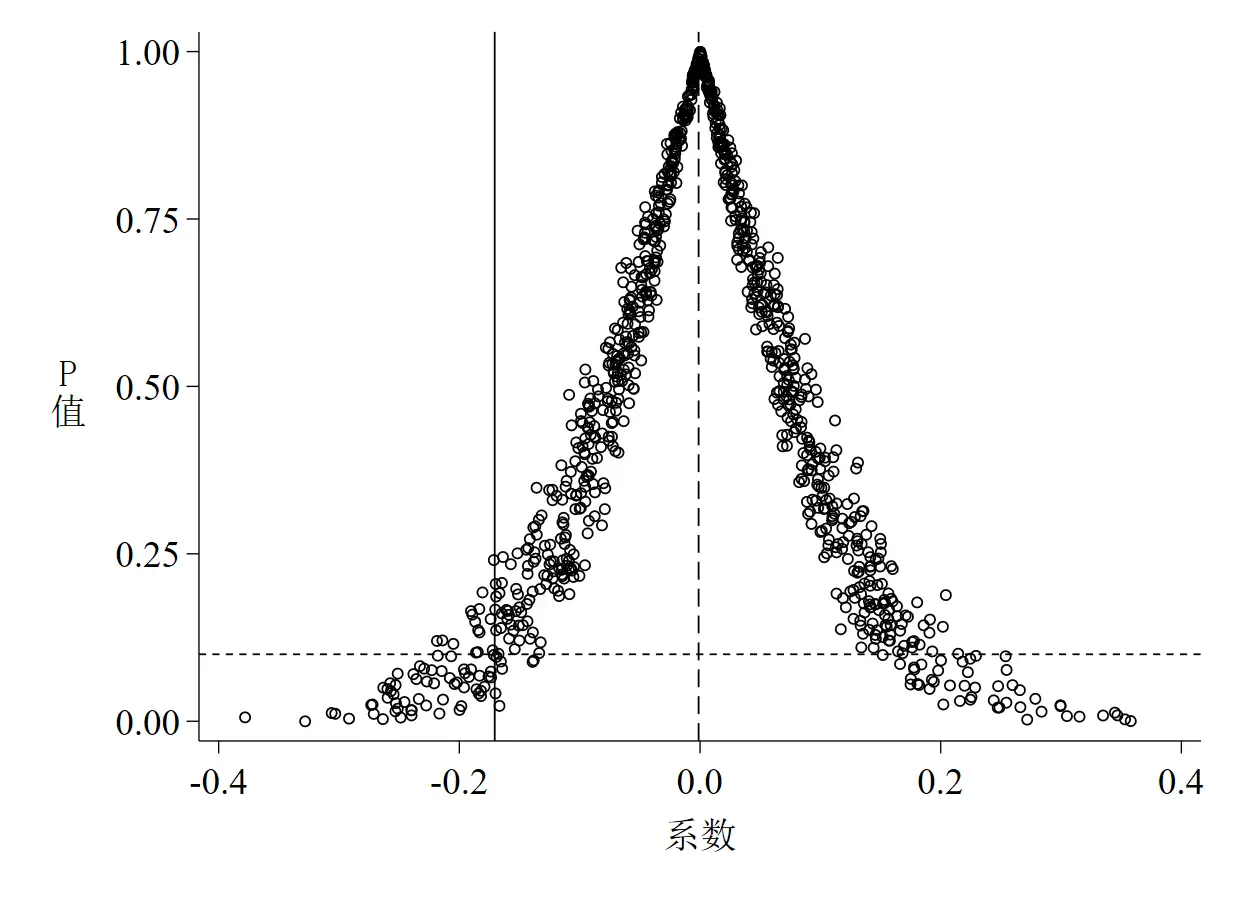
针对以上3张图,有如下几点解读。
- 第一,
图 4是随机化处理组后did项回归系数的核密度估计图,其中实线是基础回归估计出来的真实系数,虚线是1,000个“虚拟”系数的均值。 - 第二,
图 5是t值的核密度估计图,其中实线是真实t值,虚线是均值,两根短虚线分别代表t = -1.65和t = 1.65(也即大样本下10%的显著性水平所对应的t值,t值的绝对值小于该数说明至少在10%的水平下不显著)。 - 第三,
图 6是P值的散点图,其中水平短虚线是P = 0.1,散点位于该虚线以下说明系数至少在10%的水平下显著,反之则不显著。 - 第四,
图 4和图 5都说明了一个基本事实,那就是绝大多数系数和t值均集中分布在0附近,均值与真实值的距离较远,且绝大多数估计系数并不显著,这意味着智慧城市试点对环境污染治理的政策效应没有受到其他未被观测因素的影响。这个基本事实其实完全可以从P值的散点图(图 6)中得知,如散点集中分布在0附近,且远离其真实值,多数散点都位于虚线以上,同时说明在10%的水平下不显著,也就是说,P值散点图包含的信息其实更多更凝练。
参考资料 https://zhuanlan.zhihu.com/p/387900282
[1] 石大千等(2018)在《中国工业经济》的原始数据:
http://ciejournal.ajcass.org/Magazine/show/?id=54281
[2] 陆菁等(2021)在中国知网的原文:
[3] 李青原和章尹赛楠(2021)在《中国工业经济》的原始数据:
http://ciejournal.ajcass.org/Magazine/show/?id=77331
[4] 简书上的一篇文章:
https://www.jianshu.com/p/bad7471ab73b?from=singlemessage
[5] 『功夫计量经济学』的处理数据:
https://mp.weixin.qq.com/s/06v6s90G1pp-yLju_yAy1Q
ssssss
简单介绍一下双重差分法中平行趋势检验在Stata中如何操作。顺便体验一下用Markdown写微信推文的效果,嘻嘻~
(文章首发于本人的微信公众号『DMETP』,欢迎关注!)
一、平行趋势假定
平行趋势假定是实证论文中使用DID的前提,处理组与控制组的目标变量在政策发生前(事前)只有满足平行趋势假设才能使用DID。反之,如果处理组和控制组在事前就存在一定的差异,那么用DID做出来(可能还很好看)的结果就不再能代表政策的净效应,极有可能存在其他因素影响我们被解释变量的变动,此时可以使用三重差分法(DDD)。关于三重差分模型,连老师有一篇推文[1]讲的超级详细。
二、平行趋势检验
这里主要介绍两种情况下的平行趋势检验。
一是普通DID模型的平行趋势检验,包括怎么画时间趋势图,怎么画95%置信区间图(动态效应检验图)。这里以石大千等(2018)公布在《中国工业经济》官网上的数据[2]为例,由于所公布资料无法生成处理组虚拟变量,这里将使用微信公众号『功夫计量经济学』处理之后的数据[3]。
参考文献:
石大千, 丁海, 卫平, 刘建江. 智慧城市建设能否降低环境污染[J]. 中国工业经济, 2018(06): 117-135.
二是多期DID模型的平行趋势检验,包括怎么画95%置信区间图。这里之所以没有画平行趋势图,是因为在多期DID中,各个处理组受到政策冲击的时点不一致。因此,就算能够准确识别出处理组和控制组,由于处理组政策起始时点不一致,我们也很难在同一张图中将两组目标变量的时间趋势图画出来。李青原和章尹赛楠(2021)[4]的思路是,单独提取从样本开始年份直到某一年年末才受到政策冲击的样本为处理组,并将从样本开始年份直到某一年年末都没受到政策冲击的样本作为控制组,画出两组间的时间趋势图,这样的方法在政策冲击时点较少时可以考虑,因此不具有一般性。
参考文献:
李青原, 章尹赛楠. 金融开放与资源配置效率——来自外资银行进入中国的证据[J]. 中国工业经济, 2021(05): 95-113.
三、动态效应检验
动态效应检验实质上就是引入有限个时间虚拟变量,并将其与处理组虚拟变量交乘,考察交乘项的显著性。动态效应检验和平行趋势检验是有区别的,平行趋势检验中,只要考察0时期前的交乘项是否显著,如果不显著,说明处理组和控制组在事前并没有显著差异,可以使用DID。而动态效应检验不仅考察事前,也关注事后组别之间的差异,如果0时期后(包括0时期)的交乘项显著,说明政策实施存在一定的持续性效果。当然,平行趋势检验只要求事前不显著,事后显不显著不影响事前的结论。
由于多期DID中处理组受到政策影响的时点不一致,那么怎样生成时间虚拟变量就成为一个问题。在李青原和章尹赛楠(2021)中,分为5个时期,分别是样本起始年份至政策实施前两年、政策实施前一年、政策实施当年,政策实施后一年、政策实施后两年至样本结束年份;而在沈坤荣和金刚(2018)[5]中,直接省略政策推行前三年以上的年份。可见,多期DID平行趋势检验中如何设计时间虚拟变量需要兼顾理论假设和最终结果,同时需要想象力~
参考文献:
沈坤荣, 金刚. 中国地方政府环境治理的政策效应——基于“河长制”演进的研究[J]. 中国社会科学, 2018(05): 92-115.
四、Stata代码
*==============================================================================*
* 双重差分法(DID) | 平行趋势检验 *
*==============================================================================*
** Stata Version: 16 | 17
** 【文章首发】微信公众号『DMETP』,欢迎关注!
** 【数据来源】普通DID(原始数据):石大千等(2018), 参见在《中国工业经济》网站(http://ciejournal.ajcass.org/Magazine/show/?id=54281)
*- 普通DID(加工数据):『功夫计量经济学』微信公众号(https://mp.weixin.qq.com/s/06v6s90G1pp-yLju_yAy1Q)
*- 多期DID(原始数据):李青原和章尹赛楠(2021),参见在《中国工业经济网站》(http://ciejournal.ajcass.org/Magazine/show/?id=77331)
** 【参考文献】[1] 石大千, 丁海, 卫平, 刘建江. 智慧城市建设能否降低环境污染[J]. 中国工业经济, 2018(06): 117-135.
*- [2] 李青原, 章尹赛楠. 金融开放与资源配置效率——来自外资银行进入中国的证据[J]. 中国工业经济, 2021(05): 95-113.
*- [3] 沈坤荣, 金刚. 中国地方政府环境治理的政策效应——基于“河长制”演进的研究[J]. 中国社会科学, 2018(05): 92-115+206.
cd "C:\Users\KEMOSABE\Desktop\parallel_trend_test"
graph set window fontface "Times New Roman"
graph set window fontfacesans "宋体"
**# 一、普通DID的平行趋势检验
use smart_city2018.dta, clear
global xlist "lnrgdp lninno lnurb lnopen lnss"
**# 1.1 时间趋势图
bysort du year: egen mean_lnrso = mean(lnrso)
twoway(line mean_lnrso year if du == 1, ///
lpattern(solid) ///
lcolor(black) ///
lwidth(thin) ///
scheme(qleanmono) ///
ytitle("{stSans:人}""{stSans:均}""{stSans:废}" ///
"{stSans:气}""{stSans:排}""{stSans:放}" ///
"{stSans:量}" , size(medlarge) orientation(h)) ///
xtitle("{stSans:年份}", size(medlarge)) ///
xline(2012, lpattern(solid) lcolor(black) lwidth(thin)) ///
saving(parallel_trend_test_1-1, replace)) ///
(line mean_lnrso year if du == 0, ///
lpattern(shortdash) ///
lcolor(black) ///
lwidth(thin)) , ///
xlabel(2005(2)2015 , labsize(medlarge)) ///
ylabel(-2.5(0.25)-1.5, labsize(medlarge) format(%3.2f)) ///
legend(label(1 "{stSans:处理组}") ///
label(2 "{stSans:控制组}") ///
size(medlarge) position(1) symxsize(10))
graph export "parallel_trend_test_1-1.emf", replace
discard // 结果已保存至路径文件夹
**# 1.2 动态效应检验(事件研究法)
gen current = 2012.year * du
forvalue i = 4(-1)1 {
gen before`i' = (year == 2012 - `i') * du
}
forvalue k = 1/3 {
gen after`k' = (year == 2012 + `k') * du
}
drop before4 // 将2008年作为基准年
qui reghdfe lnrso before* current after* $xlist , absorb(id year) cluster(id)
coefplot, ///
keep(before* current after*) ///
vertical ///
scheme(qleanmono) ///
coeflabels(before3 = -3 ///
before2 = -2 ///
before1 = -1 ///
current = 0 ///
after1 = 1 ///
after2 = 2 ///
after3 = 3) ///
msymbol(O) msize(small) mcolor(black) ///
addplot(line @b @at, lcolor(black) lwidth(thin) lpattern(solid)) ///
ciopts(recast(rcap) lcolor(black) lwidth(thin)) ///
yline(0, lpattern(dash) lcolor(black) lwidth(thin)) ///
ytitle("{stSans:系}""{stSans:数}", size(medlarge) orientation(h)) ///
xtitle("{stSans:期数}" , size(medlarge)) ///
xlabel(, labsize(medlarge)) ///
ylabel(, labsize(medlarge) format(%02.1f)) ///
saving(parallel_trend_test_1-2, replace)
graph export "parallel_trend_test_1-2.emf", replace
discard
clear all
cls
**# 二、多期DID的平行趋势检验
use 平行趋势检验.dta, clear
global y "TFPQD_OP TFPQD_LP"
global adjyear "yb2 yb1 y0 ya1 ya2"
global ctrlvars "ADM PPE ADV RD HHI INDSIZE NFIRMS FCFIRM MARGIN LEVDISP SIZEDISP ENTRYR EXITR"
global options "absorb((city)*(year) (ind3)*(year)) cluster(city year) keepsing"
gen year_enter = 2007
replace year_enter = 2004 if city == 5101 | city == 5000 | city == 2102 | ///
city == 3501 | city == 4401 | city == 3701 | ///
city == 3201 | city == 3702 | city == 3101 | ///
city == 4403 | city == 1200 | city == 4201 | ///
city == 4404 | prov == 44 | prov == 45 | ///
prov == 43 | prov == 32 | prov == 33
replace year_enter = 2005 if city == 1100 | city == 5301 | city == 2101 | ///
city == 3502 | city == 6101
replace year_enter = 2006 if city == 2201 | city == 2301 | city == 6201 | ///
city == 6401
gen yb2 = (year_enter == year + 2)
gen yb1 = (year_enter == year + 1)
gen y0 = (year_enter == year)
gen ya1 = (year_enter == year - 1)
gen ya2 = (year_enter <= year - 2)
**# 2.1 动态效应检验(TFPQD_OP)
qui reghdfe TFPQD_OP $adjyear $ctrlvars , $options
coefplot, ///
keep( $adjyear ) ///
vertical ///
scheme(qleanmono) ///
coeflabels(yb2 = -2 ///
yb1 = -1 ///
y0 = 0 ///
ya1 = 1 ///
ya2 = 2) ///
msymbol(O) msize(small) mcolor(black) ///
addplot(line @b @at, lcolor(black) lwidth(thin) lpattern(solid)) ///
ciopts(recast(rcap) lcolor(black) lwidth(thin)) ///
yline(0, lpattern(dash) lcolor(black) lwidth(thin)) ///
ytitle("{stSans:系}""{stSans:数}", size(medlarge) orientation(h)) ///
xtitle("{stSans:期数}" , size(medlarge)) ///
xlabel(, labsize(medlarge)) ///
ylabel(, labsize(medlarge) format(%03.2f)) ///
saving(parallel_trend_test_2-1, replace)
graph export "parallel_trend_test_2-1.emf", replace
discard
**# 2.2 动态效应检验(TFPQD_LP)
qui reghdfe TFPQD_LP $adjyear $ctrlvars , $options
coefplot, ///
keep( $adjyear ) ///
vertical ///
scheme(qleanmono) ///
coeflabels(yb2 = -2 ///
yb1 = -1 ///
y0 = 0 ///
ya1 = 1 ///
ya2 = 2) ///
msymbol(O) msize(small) mcolor(black) ///
addplot(line @b @at, lcolor(black) lwidth(thin) lpattern(solid)) ///
ciopts(recast(rcap) lcolor(black) lwidth(thin)) ///
yline(0, lpattern(dash) lcolor(black) lwidth(thin)) ///
ytitle("{stSans:系}""{stSans:数}", size(medlarge) orientation(h)) ///
xtitle("{stSans:期数}" , size(medlarge)) ///
xlabel(, labsize(medlarge)) ///
ylabel(, labsize(medlarge) format(%03.2f)) ///
saving(parallel_trend_test_2-2, replace)
graph export "parallel_trend_test_2-2.emf", replace
discard
五、运行结果
1. 普通DID的平行趋势检验
用石大千等(2018)的数据绘制出如下图 1和图 2。其中,图 1是时间趋势图,可以看到,在政策实施年份(2012)年之前,处理组和控制组的人均废气排放量变动趋势大体一致,但在2005-2006这两年间两组目标变量的变动方向相反。在2012年以后,控制组人均废气排放量有过上扬的历史,随后在2013年开始逐年下降,但下降幅度不大;处理组的人均废气排放量在2012年以后年份均处于下降通道,且在2014年下降幅度较大。因此,可以初步判断两组间在政策实施年份前的时间趋势假定基本是满足的,政策实施年份以后趋势线的差异基本判断是由智慧城市试点造成的。当然,这个结论并不稳健,需要进一步检验两组间的动态效应。
图 2是动态效应检验图。其中,垂直于横轴的带盖短直线是各期数与处理组虚拟变量的交乘项回归系数的95%置信区间。可以看到,在期数为0(该例为2012年)以前,除政策实施年份三年前的系数显著(95%置信区间没有越过系数 = 0的水平虚线),其余期数都是不显著的,这也与时间趋势图所揭示的信息基本保持一致。而在政策实施以后的所有年份,系数基本显著(期数为2时有微微不显著),说明该政策的影响具有一定的持续性(或称时滞性),并且在样本期间内于实施后的第三年该政策具有最大的效果。当然,基准年的选择对显著性的影响很大,这里将2008年作为基准年,也可以通过选择不同的基准年对结果进行适当调整。
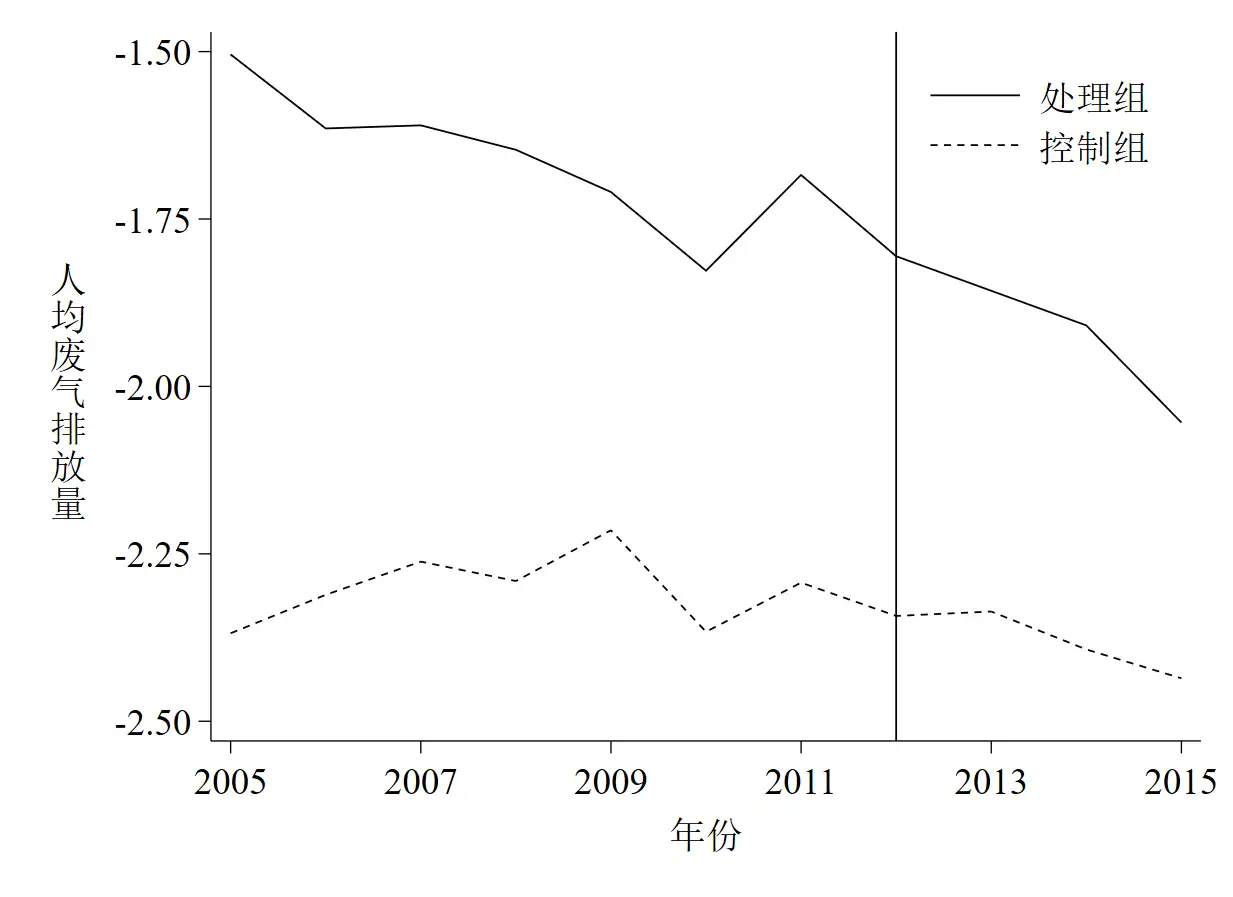
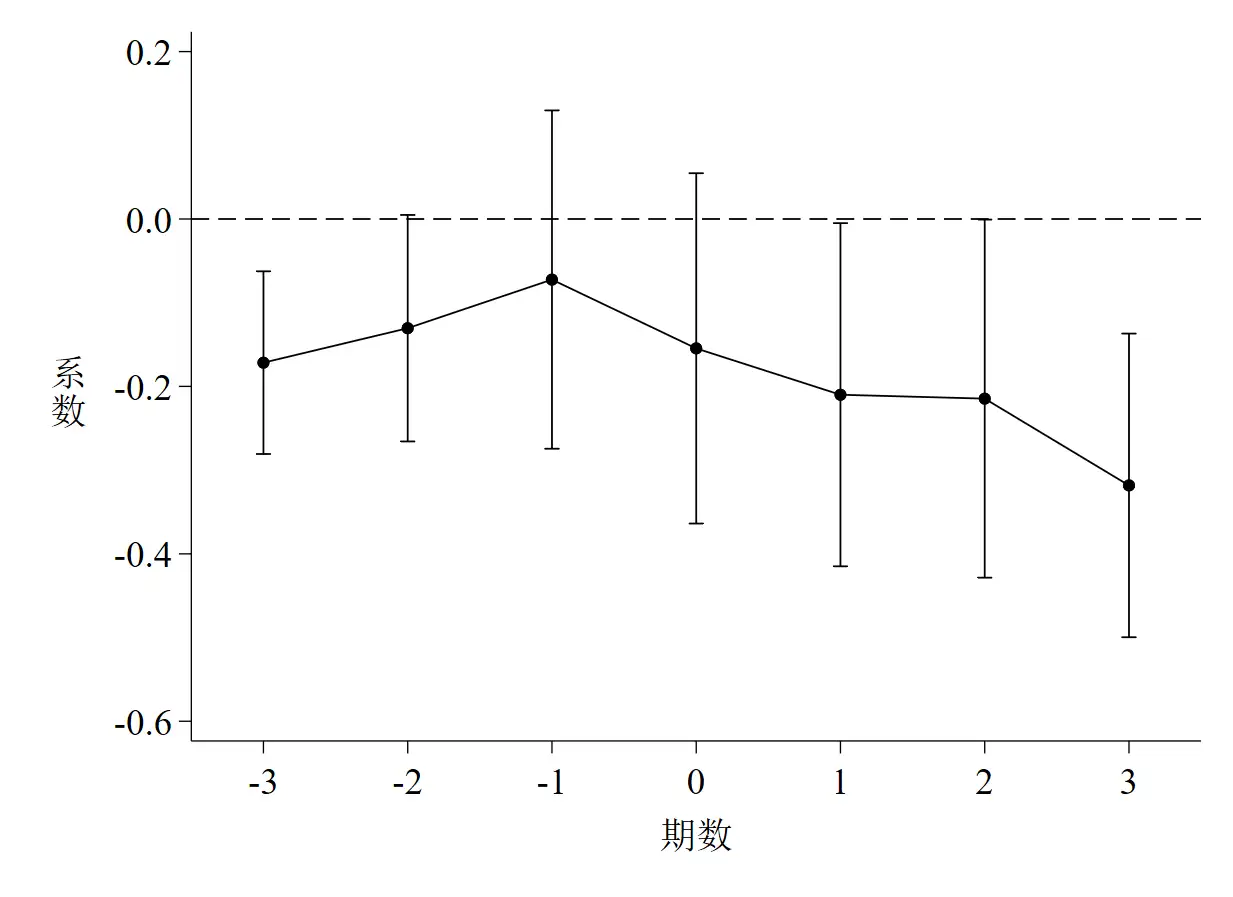
2. 多期DID的平行趋势检验
图 3和图 4分别是使用李青原和章尹赛楠(2021)公布的数据画出来的基于OP法和LP法计算的TFP离散度的动态效应检验图。在李青原和章尹赛楠(2021)公布的附件中,作者在平行趋势检验部分提供了回归结果表,但没有将其绘制成图。如图 3所示,在政策实施之前,系数都是不显著的,政策实施以后,系数同样都不显著。这说明了基于OP法计算的TFP离散度满足平行趋势假定,但政策实施不具有持续性。虽然政策不具有持续性,但系数为负是符合基本理论假设的,并且在政策实施一年后开始,系数与t值较之前明显增大。
图 4就比较完美了,实施年份之前都不显著,实施年份之后都显著,且系数符合理论假设,这说明基于OP法计算的TFP离散度既满足平行趋势假定,而且政策实施的影响具有一定的持续性。
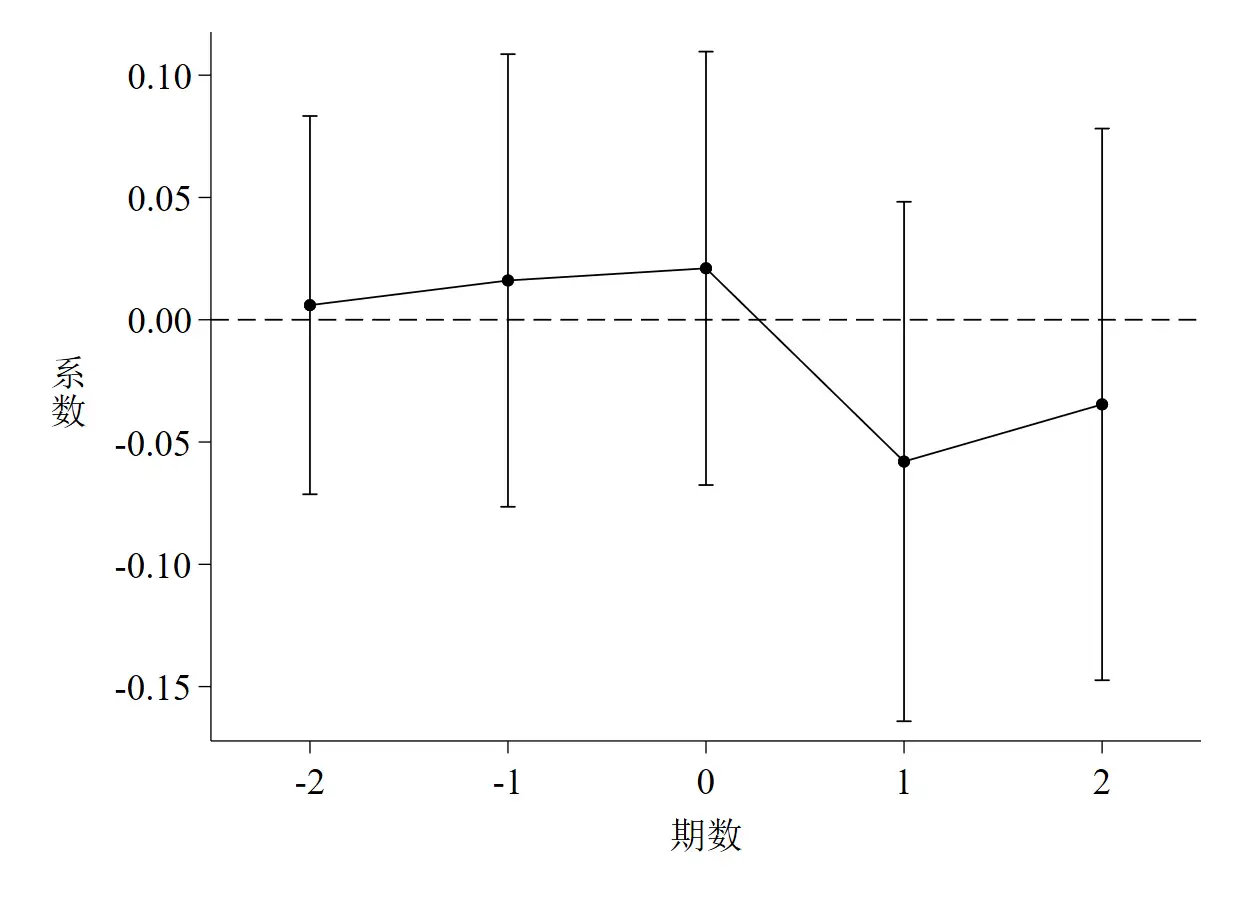
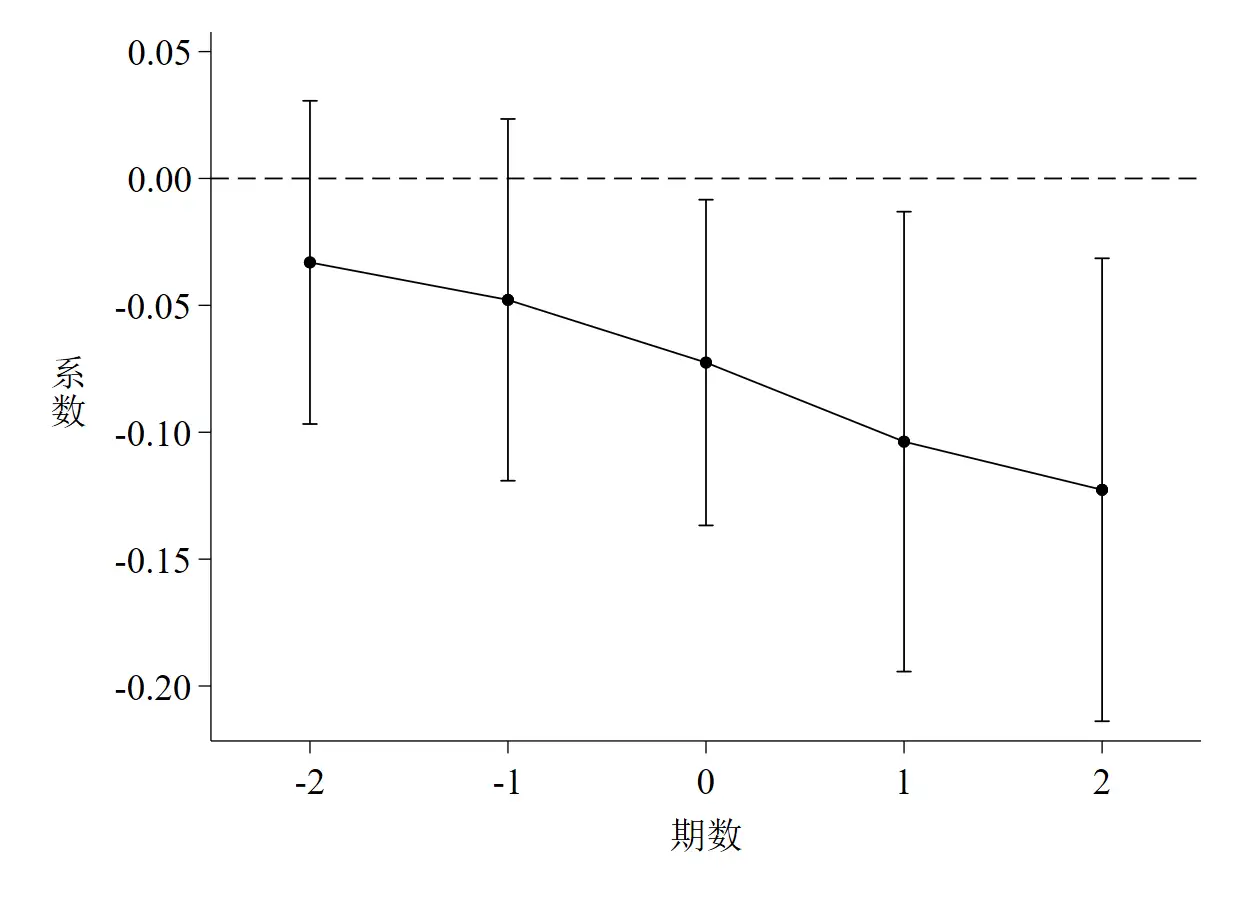
参考资料
[1] 连享会的知乎专栏:
https://zhuanlan.zhihu.com/p/96690721
[2] 石大千等(2018)在《中国工业经济》的原始数据:
http://ciejournal.ajcass.org/Magazine/show/?id=54281
[3] 『功夫计量经济学』的处理数据:
https://mp.weixin.qq.com/s/06v6s90G1pp-yLju_yAy1Q
[4] 李青原和章尹赛楠(2021)在《中国工业经济》的原始数据:
http://ciejournal.ajcass.org/Magazine/show/?id=77331
[5] 沈坤荣和金刚(2018)在知网的原文:
sssssssss
这期推送简单介绍一下我在以往清洗数据的过程中用过的一些野路子。
这期推文其实在上期之后就一直在构思,只是在实际落地的时候有一些小问题需要解决,然后这段时间又在忙其他事情,所以就一直拖到了现在……
1、下划线字体为链接,可点击跳转;2、推文中的公式与代码块均可左右滑动;3、该文首发于微信公众号
DMETP,欢迎关注;4、文中所有外部命令均可通过以下方式获得,以高维固定效应估计命令reghdfe为例:
*- 法一:
ssc install reghdfe, replace
*- 法二:
findit reghdfe
*- 法三:
search reghdfe< 目录 >
一、数据格式转换与合并
当我们从EPS中国微观经济数据查询系统[1]按照单年数据查询下载好每一年的csv文件后,假设我们按照年份把这些csv文件分别放到不同的文件夹中,接下来的事情就是把这些csv文件统一转化为dta文件,再将这些同一年份的dta文件纵向append到一个dta文件中。
往期推送的解决方案是:
- 首先,利用批处理对文件重命名;
- 其次,使用StatTransfer软件将
csv文件转为dta文件; - 最后,在Stata中修正乱码并使用
for循环进行多个数据集的纵向合并。
整体来看,这样的操作比较繁乱,而且特别容易出错。事实上,Stata有一个csvconvert外部命令能够同时进行多个csv文件的转换与合并,极大地方便了我们的数据清洗工作(除了不能修正乱码)。下面结合工企数据库对该命令进行简要介绍。
首先,在桌面创建一个文件夹,并将其命名为exp,在该文件夹中再创建两个子文件夹:
- 一是
raw_data文件夹,raw_data中再分别按照年份创建16个孙文件夹(1998-2013年),分别存放我们下载好的对应年份的原始数据。 - 二是
temp_data文件夹,用于存放我们操作过程中产生的缓存数据。
其次,在Stata中定义原始数据及缓存数据存放路径的全局暂元。
global path C:\Users\KEMOSABE\Desktop\exp
global raw_path $path\raw_data
global temp_path $path\temp_data之后,结合循环语句和csvconvert命令将原始数据合并为16个dta文件。
forvalue i = 1998/2013 {
capture csvconvert $raw_path\\`i' , ///
replace output_dir( $temp_path ) output_file(`i')
}以1998年为例:
$raw_path\\1998是1998年所有原始数据存放的路径,在子路径和孙路径中间加两个\的原因是,如果只加一个\,Stata将自动忽略这个符号从而报错。replace代表替代该路径下的同名文件。output_dir( $temp_path )代表输出的缓存文件的存放路径,这里是C:\Users\KEMOSABE\Desktop\exp\temp_data。output_file(1998)代表该缓存文件命名为1998。
整体来看,csvconvert命令确实比之前的方法要简便。但是,一个不能忽视的问题是,在我们得到这16年的dta文件之后,任意打开一个文件可以发现乱码的现象是普遍存在的,包括所有变量名称、字符型数据和标签。之前的方法可以使用Stata自带的转码命令进行转码,但是通过csvconvert输出的数据集却只能对标签进行转码,我尝试了几乎所有能找到的方法,但这些方法都不能奏效。针对这个顽疾,欢迎各位读者在公众号后台与我交流!
二、OP法计算企业TFP
OP法测算TFP的常用外部命令是opreg,在该命令下需要企业退出变量Exit,Exit的取值规则是:若企业在下一年退出市场且于观察期内不复进入时取1,否则取0;特别地,当企业在观测期末年仍旧存续时取0。以工企数据库为例,存在以下四种情况:
- 情况一,企业只有单年观测值( singleton ),也就是说,某企业在1998-2013年这16年的观测区间内只有一年观测值。对于这种样本,
Exit的取值情况不影响回归结果,因为在参与回归时单年观测值将被自动剔除(除非强行不剔除,如reghdfe命令下使用keepsingletons选择项,但这样的后果是统计显著性有偏)。在这里,我们将其取1。 - 情况二,企业存在两年及以上观测值,并且这些观测值在时间上连续,如某企业在2001、2002和2003年这三年内存续,并且在2003年以后不存在(无论其原因是退出市场还是数据本身的缺陷)。对于这种情况,我们令
Exit在2001年和2002年取0,2003年取1。 - 情况三,企业存在两年及以上观测值,并且这些观测值在时间上不连续,如某企业在2001、2002和2004年这三年内存续,并且在2004年以后不存在。在这种情况下,我们令
Exit在2001年和2002年取0,2004年取1。对于间断的年份(如这里的2003年),我们认为企业在这些间断年份内仍旧保持存续,数据缺失不表明企业不存续。 - 情况四,特别地,如果某企业在2013年存在观测值,由于我们无法得知企业在2014年的存续状态,因此我们令
Exit在2013年取0。
我们以一个手工生成的数据集为例。
clear all
input id year emp
1 2011 1
2 2008 0
2 2009 0
2 2010 0
2 2011 0
2 2012 0
2 2013 0
3 2008 0
3 2010 0
3 2011 0
3 2012 0
3 2013 0
4 2008 0
4 2011 0
4 2012 0
4 2013 0
5 2008 0
5 2009 0
5 2011 0
5 2012 0
5 2013 0
6 2008 0
6 2009 0
6 2010 0
6 2011 0
6 2012 1
7 2006 0
7 2007 1
end
list, sepby(id)其中,变量emp是企业实际的存续状况,其取值与后面创建的Exit变量保持一致。可以看到,个体1符合上文中的情况一;个体2符合情况二和情况四;个体3、4和5符合情况三和情况四;个体6和个体7符合情况二。
下面是创建Exit变量的代码。
xtset id year
bysort id: gen Exit = (_n == _N)
replace Exit = 0 if year == 2013
bro可以看到,Exit的取值与emp保持一致。
事实上,opreg命令的编写者Yasar et al.(2008[2];2012)[3]也提供了变量Exit的生成方法。下面是参照Yasar et al.(2008;2012)的方法生成工企数据库企业退出变量exit的代码。
[2] Yasar M, Raciborski R, Poi B. Production Function Estimation in Stata Using the Olley and Pakes Method[J]. Stata Journal, 2008, 8(02): 221-231.
[3] Software Updates[J]. Stata Journal, 2012, 12(01): 167-167.
xtset id year
sort id year
by id: gen count = _N
gen survivor = (count == 16)
gen has98 = 1 if year == 2013
sort id has98
by id: replace has98 = 1 if has98[_n-1] == 1
replace has98 = 0 if has98 == .
sort id year
by id: gen has_gaps = 1 if year[_n-1] != year-1 & _n != 1
sort id has_gaps
by id: replace has_gaps = 1 if has_gaps[_n-1] == 1
replace has_gaps = 0 if has_gaps == .
sort id year
by id: gen exit = (survivor == 0 & has98 == 0 & has_gaps != 1 & _n == _N)
replace exit = 0 if exit == 1 & year == 2013
drop count survivor has98 has_gaps
bro可以看到,emp、Exit和exit保持一致。
此外,部分研究者在生成Exit变量时,直接将存续年份不连续的样本剔除,关于这种做法的理论与文献基础我暂时没有找到,因此其合理性存疑。下面的实现代码借鉴了黄河泉老师(2021)[4]在经管之家论坛的回答。若有必要,这段代码在Exit生成之前运行即可。
xtset id year
gen d = 1
tsfill
bysort id: egen tem1 = count(d)
bysort id: gen tem2 = _N
keep if tem1 == tem2
drop d tem1 tem2 // 剔除存续序列不连续的样本,该步骤的必要性与合理性存疑OP法测算企业TFP,除了上文介绍的opreg命令,prodest这个外部命令也能实现,且不需要加入Exit变量。prodest除了可以使用OP法测算TFP,还可以使用LP法、WRDG法、MR法、以及OP法和LP法的ACF修正法,具体方法与使用细节可以键入help prodest进行了解。
值得一提的是,在实际测算中,OP、LP、WRDG和MR方法测算的TFP基本保持一致,但ACF法测算的结果与前面几种相比存在较大偏差。篇幅所限,这几种测算方法的结果对比推文没有贴出来。
三、截取字符串生成新变量
假设有一个字符型变量,在该变量下的数据为字母与数字的混合组合,且长度不一致。现在的需求就是,生成两个新变量,其中一个变量记录字符型变量的字母部分;另外一个变量记录字符型变量的数字部分,且将变量类型改为数值型。
最初的想法是使用substr()函数,但问题是字符型变量的长度不一致,而substr()函数只能截取固定位置的信息,也就是说,substr()函数要求变量的长度保持一致。这里将尝试使用正则表达式(regular expression)。
还是以一个手工生成的数据集为例。
clear all
input str8 x
"abc"
"123"
"abc123"
"123abc"
"a1b2c3"
"1a2b3c"
end可以看到,该数据集的唯一变量x有多个字符串组合,包括纯字母、纯数字、前字母后数字、前数字后字母以及其他组合类型。下面的实现代码专门针对前三种组合,至于后面几种组合,利用正则表达式也能实现。
gen x1 = regexs(0) if regexm(x, "^([a-z]*)([0-9]*)$")
gen x2 = regexs(1) if regexm(x, "^([a-z]*)([0-9]*)$")
gen x3 = regexs(2) if regexm(x, "^([a-z]*)([0-9]*)$")
destring x3, replace
list, separator(6)
bro
/*
+-----------------------------+
| x x1 x2 x3 |
|-----------------------------|
1. | abc abc abc . |
2. | 123 123 123 |
3. | abc123 abc123 abc 123 |
4. | 123abc . |
5. | a1b2c3 . |
6. | 1a2b3c . |
+-----------------------------+
*/可以看到,x2和x3就是我们需要的变量。
下面对代码进行解释,由于这里只是正则表达式的简单应用,因此不会做过多分析,但若能够熟练使用该方法,在处理数据时帮助会很大。键入help string_functions详细了解。
regexs(#)提示截取信息的位置,#等于0说明截取regexm()中逗号前的内容;#等于1说明截取逗号后第一个括号内的内容;#等于2说明截取逗号后第二个括号内的内容。regex()提示信息截取的具体内容,双引号内^表示开始,$表示结束;[a-z]表示字母,[0-9]表示数字;*表示截取0个及以上的数字或字母。
四、永续盘存法测算投资额
使用OP法估计企业TFP时,须引入企业投资额作为不可观测生产率冲击的代理变量,以缓解模型中可能存在的同时性偏差(Simultaneity)(Olley & Pakes,1996)[5]。
[5] Olley G S, Pakes A. The Dynamics of Productivity in the Telecommunications Equipment Industry[J]. Econometrica, 1996, 64(06): 1263-1297.
因此,在使用OP法估计工业企业TFP时,固定资产投资额是一个必须变量,但在工企数据库中,不存在固定资产投资额字段。一个常见的方法是使用永续盘存法(Perpetual Inventory Method,PIM)间接测算,公式如下:
有两点比较关键的说明:
- 第一,
为企业在年的固定资产合计或固定资产净值(这里选择固定资产合计),式说明上一年观测值缺失的样本无法计算当年的,因为上一年的固定资产合计数据无法获得,但对于在整个观测区间内至少存在两年观测值的样本(仅有单年观测值的样本在参与回归时将自动被剔除),年的企业固定资产合计可以以企业固定资产的平均增长率进行估算,假定平均增长率为,则(张天华和张少华,2016)[6]。在这里,企业在年的固定资产增长率计算公式如下式,其中与在年份不连续的情况下其差值不等于1,即为
- 的组内均值。
- 第二,
为经济折旧率,对的选择是充满有争议的。根据经济学领域的常用选择,可以将经济折旧率设定为9.6%(张军等,2004[7];何兴强等,2014[8])。但存在的问题是,张军等(2004)测算的9.6%是各省固定资本形成总额的经济折旧率,也就是说,该数值没有细分到具体地区,也不是我们关注的制造业行业,更关键地,该折旧率的时间跨度为1952-2000年。因此,为了增强估计结果的稳健性,还应该参考其他文献的做法来设定
- ,如5%(邵宜航等,2013)[9]、10%(肖文和林高榜,2014[10];李青原和章尹赛楠,2021)[11]和15%(聂辉华等,2012)[12]。
[6] 张天华, 张少华. 中国工业企业全要素生产率的稳健估计[J]. 世界经济, 2016, 39(04): 44-69.
[7] 张军, 吴桂英, 张吉鹏. 中国省际物质资本存量估算:1952—2000[J]. 经济研究, 2004(10): 35-44.
[8] 何兴强, 欧燕, 史卫, 刘阳. FDI技术溢出与中国吸收能力门槛研究[J]. 世界经济, 2014, 37(10): 52-76.
[9] 邵宜航, 步晓宁, 张天华. 资源配置扭曲与中国工业全要素生产率——基于工业企业数据库再测算[J]. 中国工业经济, 2013(12): 39-51.
[10] 肖文, 林高榜. 政府支持、研发管理与技术创新效率——基于中国工业行业的实证分析[J]. 管理世界, 2014(04): 71-80.
[11] 李青原, 章尹赛楠. 金融开放与资源配置效率——来自外资银行进入中国的证据[J]. 中国工业经济, 2021(05): 95-113.
[12] 聂辉华, 江艇, 杨汝岱. 中国工业企业数据库的使用现状和潜在问题[J]. 世界经济, 2012, 35(05): 142-158.
下面以一个手动生成的数据集为例。
clear all
input id year
1 2011
2 2008
2 2009
2 2010
2 2011
2 2012
2 2013
3 2008
3 2011
3 2012
3 2013
4 2008
4 2013
5 2008
5 2009
5 2011
5 2012
5 2013
6 2008
6 2009
6 2010
6 2011
6 2012
7 2006
7 2007
end
set seed 2021
gen asset = abs(rnormal())可以看到,个体1只有单年观测值,个体3、4和5的样本年份不连续。如果按照一般的方法使用PIM测算企业固定资产投资额,全部个体在样本初年的指标均无法计算,且年份不连续的个体在年份开始初年的指标也无法计算,如个体3在2011年的固定资产投资额无法计算。
sort id year
bys id: gen growth = (asset[_n] - asset[_n-1]) / (asset[_n-1] * (year[_n] - year[_n-1]))
xtset id year
tsfill
tsappend, add(1)
bys id: replace year = year[1] - 1 if _n == _N
sort id year
bys id: egen growth_mean = mean(growth)
bys id: gen ceiling = 1 if _n == _N
gen asset_hypo = asset
bys id: replace asset_hypo = asset_hypo[_n+1] / (1 + growth_mean) ///
if asset == . & asset[_n+1] != . & ceiling != 1
*- 经济折旧率δ = 9.6%(张军等,2004)
bys id: gen investment1 = asset_hypo - asset_hypo[_n-1] * (1 - 0.096)
*- 经济折旧率δ = 5%(邵宜航等,2013)
bys id: gen investment2 = asset_hypo - asset_hypo[_n-1] * (1 - 0.05)
*- 经济折旧率δ = 10%(肖文和林高榜,2014;李青原和章尹赛楠,2021)
bys id: gen investment3 = asset_hypo - asset_hypo[_n-1] * (1 - 0.1)
*- 经济折旧率δ = 15%(聂辉华等,2012)
bys id: gen investment4 = asset_hypo - asset_hypo[_n-1] * (1 - 0.15)
label var investment1 "经济折旧率取9.6%时测算的固定资产投资额"
label var investment2 "经济折旧率取5%时测算的固定资产投资额"
label var investment3 "经济折旧率取10%时测算的固定资产投资额"
label var investment4 "经济折旧率取15%时测算的固定资产投资额"
drop growth growth_mean ceiling asset_hypo
drop if asset == .
list, sepby(id)
*- 只有单年观测值的个体参与回归时将被剔除
sum invest*
#delimit ;
twoway (kdensity investment1)
(kdensity investment2)
(kdensity investment3)
(kdensity investment4)
;
#delimit cr
bro其中,growth为,growth_mean为的组内均值
,四个investment#即是不同经济折旧率下测算的固定资产投资额。
下面以核密度曲线图来直观呈现这四个investment#的偏离程度,如图 1。可见,这四个investment#的核密度曲线基本重合,也就是说,对于手动生成的数据集,在
这个区间选择任意一个折旧率进行测算结果均基本保持一致。
五、货币型变量的指数平减
阅读以下文字前,建议把如何对变量进行指数平减弄懂,可参考知乎用户『无宇』个人主页的第一个回答[13]。
这里以一份手工生成的数据集为例,该数据集包含两个个体1997-2019年的工业增加值,这两个个体所属省份均为安徽省(二位数行政区划代码为34),工业增加值以当年价格计算,因此需要进行指数平减,平减工业增加值的常用指数为工业品出厂价格指数PPI。
version 17
clear all
set obs 20
set seed 2021
gen id = 1 in 1/10
replace id = 2 in 11/20
bys id: gen year = 1996 + _n
gen province = 1
gen VA = abs(rnormal())
label var VA "工业增加值(当年价格)"对工业增加值进行指数平减的大致思路可以分为两步:
- 第一步,将上年=100的
PPI转为1997=1; - 第二步,利用
PPI(1997 = 1)对货币型变量进行指数平减。
由于指数平减涉及两个数据集的数据处理与合并,因此下面将使用框架(frame)进行操作。当然,对单个数据集分别进行处理,然后再横向merge到一个数据集也是可行的做法。
需要说明的是,frame是Stata 16新加入的功能,Stata 15及以下版本无法使用。Stata中frame的功能类似于Excel的工作表sheet,方便在同一个操作窗口中打开多份数据集并对数据集进行处理,而不需另外加载Stata软件打开数据集。
先简单介绍一下Stata中的frame系列命令,具体信息请键入help frame进行了解。
frame dir:显示内存中所有的框架;frame pwf:显示当前正在工作的框架,pwf和frame作用与之相同;frame create newfraname:创建一个新的框架,并命名为newfraname,mkf newfraname作用与其一致;frame drop franame:删除框架franame,但不可删除当前工作框架;frame change franame:将工作框架转换到franame,cwf franame作用与之相同;frame rename oldfraname newfraname:重命名框架;frame franame: command或frame franame {command}在框架franame下运行命令;frlink:通过连接变量linkvar建立两个框架之间的连接;frget: 通过连接变量将其他框架中的数据复制到当前工作框架中,一般与frlink配合使用,两者的配合使用功能类似于merge命令进行横向合并(append)。
mkf ppi
frame ppi {
input province year ppi
34 1997 99.4
34 1998 96.4
34 1999 92.9
34 2000 98.9
34 2001 98.6
34 2002 99.82
34 2003 103.5
34 2004 108.16
34 2005 103.25
34 2006 103.07
34 2007 103.6
34 2008 108.4
34 2009 92.8
34 2010 108.98
34 2011 108.3
34 2012 98.26
34 2013 98.16
34 2014 97.4
34 2015 93.94
34 2016 98.5
34 2017 108
34 2018 103.03
34 2019 100.3
end
replace ppi = ppi / 100
label var ppi "工业品出厂价格指数(上年 = 1)"
sort province year
gen ppi97 = ppi
bys province: replace ppi97 = 1 if _n
bys province: replace ppi97 = ppi97[_n-1] * ppi if _n != 1
label var ppi97 "工业品出厂价格指数(1997 = 1)"
format ppi* %6.4f
list
}
frame dir
pwf
frlink m:1 province year, frame(ppi) gen(linkid)
frget ppi97, from(linkid)
gen VA1 = VA / ppi97
label var VA1 "工业增加值(可比价格)"
bro其中,linkid是两个框架之间建立联系的关键连接变量,ppi97是以1997年为基期的PPI,VA1是经指数平减后的工业增加值,因此该变量在不同年份可比。
参考资料
[1] EPS中国微观经济数据查询系统: http://microdata.sozdata.com/home.html
[2] Yasar et al.(2008)在Stata Journal上的原文: https://www.stata-journal.com/article.html?article=st0145
[3] Yasar et al.(2012)在Stata Journal上的原文: https://www.stata-journal.com/article.html?article=up0035
[4] 黄河泉老师(2021)在经管之家论坛的回答: https://bbs.pinggu.org/thread-10619028-1-1.html
[5] Olley & Pakes(1996)在JSTOR上的原文链接: http://www.jstor.org/stable/2171831
[6] 张天华和张少华(2016)在CNKI上的原文链接: https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CJFD&dbname=CJFDLAST2016&filename=SJJJ201604004&uniplatform=NZKPT&v=fEO%25mmd2B%25mmd2B7WsCzS0W9fwUDyV8tOQs1k1aKuslcOIVichjwTbSllAKhJeiZoQ%25mmd2B6aswJ8b
[7] 张军等(2004)在CNKI上的原文链接: https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CJFD&dbname=CJFD2004&filename=JJYJ200410004&uniplatform=NZKPT&v=f8c3dhGN04%25mmd2FREI3VIjzuOEIer8fMdjTNPq340fZQSg%25mmd2B2iLg806QYX2qKz2PDB1J9
[8] 何兴强等(2014)在CNKI上的原文链接: https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CJFD&dbname=CJFDLAST2015&filename=SJJJ201410004&uniplatform=NZKPT&v=7ZdISdpBS7NGfj8rXK4IIpab2R8%25mmd2F%25mmd2Fs1TWlUCp%25mmd2BoCDIdMlD%25mmd2FfsfVQzKFfhyr%25mmd2B3iKm
[9] 邵宜航等(2013)在CNKI上的原文链接: https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CJFD&dbname=CJFDHIS2&filename=GGYY201312005&uniplatform=NZKPT&v=fZT%25mmd2BwLoz1b1IEPIaKh%25mmd2Bmlx%25mmd2BsVl4WSQYghAjIsgheowSu3J3zIe1XeWVOc%25mmd2FCL%25mmd2BfMZ
[10] 肖文和林高榜(2014)在CNKI上的原文链接: https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CJFD&dbname=CJFDLAST2015&filename=GLSJ201404008&uniplatform=NZKPT&v=2205LbYcuSHuDLH8xWiM3vEcHK%25mmd2F2BnoqYKOMMSr87KRNib09DcA3fi3iYoIZe7Nh
[11] 李青原和章尹赛楠(2021)在CNKI上的原文链接: https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CJFD&dbname=CJFDLAST2021&filename=GGYY202105007&uniplatform=NZKPT&v=O%25mmd2F1bdOGYPcqB6ZjY9Jm%25mmd2BZx3jTQOhxAhy43aP2vd1L7%25mmd2BDBPxy1WBALOoPyVRNNpMi
[12] 聂辉华等(2012)在CNKI上的原文链接: https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CJFD&dbname=CJFD2012&filename=SJJJ201205011&uniplatform=NZKPT&v=yOdL3GT33co33gtCCIvZYpYKKE4bKg4Thio5Glbj93qxa9PGauSDsa1HR%25mmd2F44eNNg
[13] 知乎用户『无宇』个人主页的第一个回答: https://www.zhihu.com/people/ecustwu-yu/answers/by_votes