did
1小时用Stata速成毕业论文-第1部分-准备工作

上海财经大学 管理学博士
我之前曾经教过三届学生用Stata处理毕业论文数据,本教程在上述授课讲义的基础上进行了高度简化,相信略有点数理统计基础的同学应该很容易上手。
本教程不讲原理,如果读者对统计检验、回归分析的具体原理感兴趣,请自行翻阅经典的统计学教材。对大部分这辈子没有兴趣做第二篇毕业论文(比如硕士论文)的同学,我不建议花时间在这上面。
当然,肯定会有读者质疑“1小时学会用Stata”的严谨性。杨老师坦诚讲,“1小时”的表述是不严谨的。我认为,如果读者专注在数据处理的学习方面,那么,上机操作完成本教程所有的程序,所花费的时间不会超过45分钟。因此,我原来想将教程命名“45分钟用Stata速成毕业论文”。可是,以我的教学经验,必然会有部分读者出现大小写混淆、手工输入错字母、空格不当和其他技术性误操作。犹豫再三,稳妥起见,再加15分钟以覆盖这部分错误所耗费的时间,最后命名“1小时用Stata速成毕业论文”。
磨刀不误砍材功。
“工欲善其事,必先利其器”,我们要先准备好工具和材料。一共有五个文件夹,包括:
1.软件;
2.论文;
3.数据;
4.讲义;
5.练习。
这些工具和材料,如果你可以进“QQ群:921928271或者411303206”,那么去里面下载。如果搜不到上面这个账号,那么,请通过手机QQ扫码直接进群。
当然,如果二维码被屏蔽,可以搜索我的微信公众号SasInResearch,点击stata菜单栏,里面有群信息。
(最近由于加群人数太多,一个QQ群已满,另一个估计很快也会满。
我做了如下分享:
链接:https://pan.baidu.com/s/1e4tt54-WSX8bjlxfDxSQlw
提取码:8gdm)更新于2020.10.17
让我们花一点时间看看各个文件夹的具体内容。
1.软件
软件就是Stata。这个软件很小巧,大家可以看到压缩包只有16.5兆,但数据处理功能很强大。此外,Stata在绘图和回归分析方面做得都比较好。我们要将Stata10解压,解压后你可以看到文件夹里有如下内容:
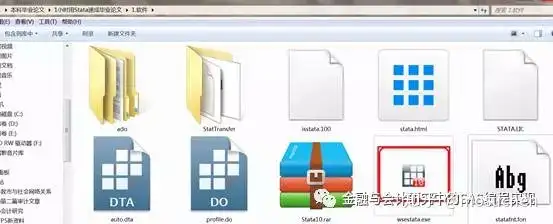
双击我标红框的图标:“wsestata.exe”。
你可以看到如下的界面:
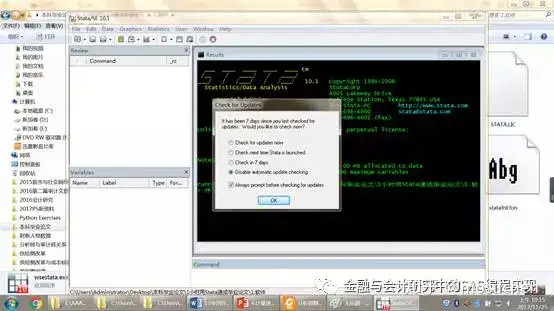
这时选择“Disable automatic update checking”,再点击OK,界面如下:
简单介绍一下各个窗口,你有个印象就好,记不住没关系。

2.论文
这是我和合作者们的一篇工作论文,这篇文章的统计部分非常完整,很适合作为数据分析的示例。

如果你有时间,请仔细阅读下面两句话和每句话下面的回归模型。
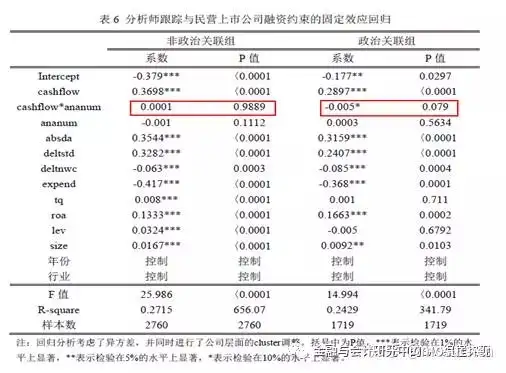
假说 H1:对无政治关联的民营上市公司而言,分析师跟踪与其融资约束无关;对有政治关联的民营上市公司而言,分析师跟踪次数越多,其面临的融资约束越小。
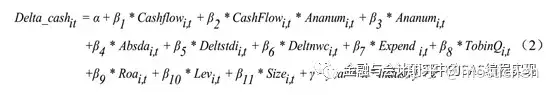
假说 H2:对无政治关联的民营上市公司而言,分析师跟踪与其非效率投资负相关;对有政治关联的民营上市公司而言,分析师跟踪与其非效率投资无关。


看不懂,对吧?没关系,你先有个印象,接着往下看。
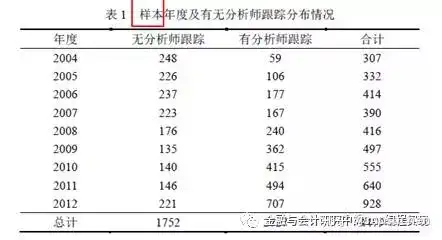
一篇标准的毕业论文至少要有六个表格:
(1)样本分布表
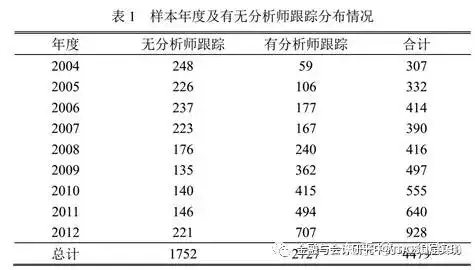
(2)变量定义表
在这里,我们稍微停一下,仔细看看这张表,再回过头看看上面的回归模型。
还是看不懂吧?没关系,你就记住这篇文章探讨的是Ananum是否会影响Delta_cash 、OverInv 、UnderInv这三个变量就行了。这三个变量的定义请仔细看看。
(3)描述性统计表
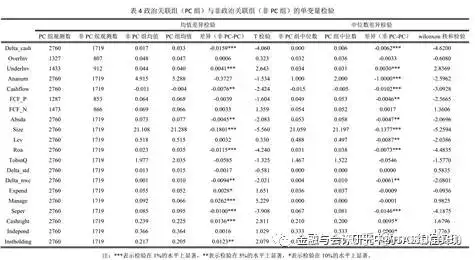
(4)均值差异检验和中位数差异检验表(单变量差异检验表)
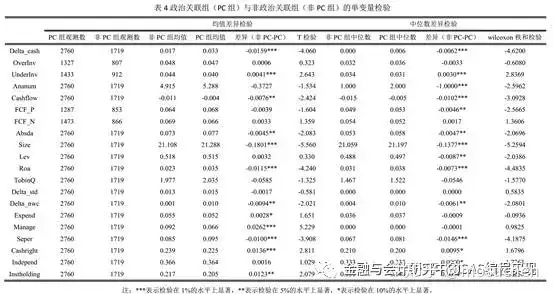
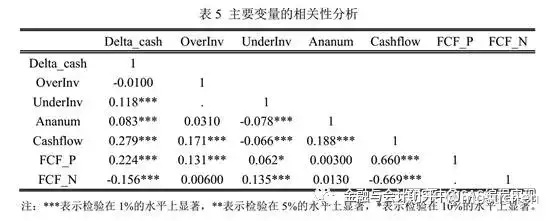
(5)相关性分析表
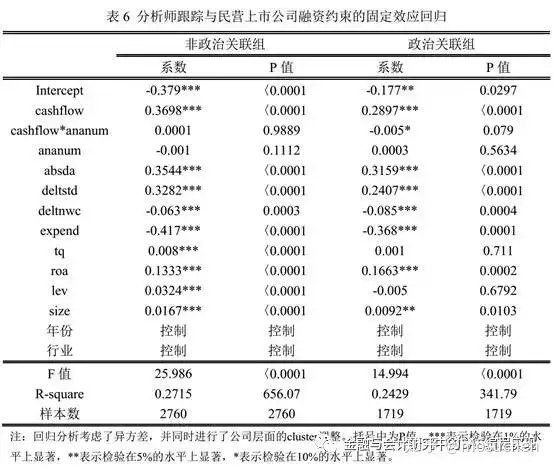
(6)回归分析表
3.数据
数据文件夹里只有一个数据“table0”,本教程所有统计表格都基于这个table0制作。
4.讲义
如果你对回归分析原理想做简单的理解,可以阅读讲义里的内容。如果你没有时间,那就算了。
5.练习
学习完了,要进行检验,我提供了数据集和练习内容,请花十分钟左右,检验一下学习成果。

准备工作完成以后,我们就要上机练习了。在第二部分,我将提供code,使用样本数据来演示基本实证分析过程。
详情请参考:
1小时用Stata速成毕业论文-第2部分-基本操作1018 赞同 · 38 评论文章
倘若文章给您带来些许收获,还请关注我的微信公众号,期待您的批评与建议。
1小时用Stata速成毕业论文-第2部分-基本操作
上海财经大学 管理学博士
基本操作包括如下六个部分:
1. EXCEL数据傻瓜式导入;
2.样本分布的表格编制;
3.主要变量的描述性统计;
4.单变量之间的分组检验;
5.相关性分析;
6.回归分析。
1. EXCEL数据傻瓜式导入
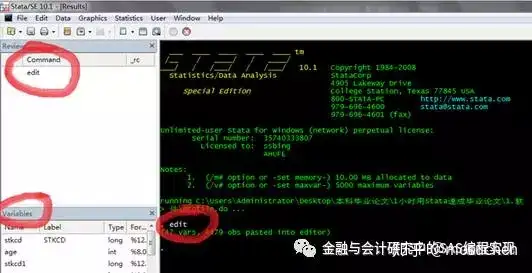
第一步,命令窗口输入 edit, 然后回车。
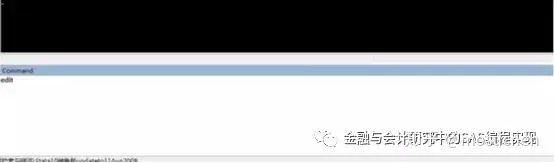
回车后得到下图,也就是Data Editor窗口:

第二步,打开EXCEL数据表(table0),选择所需数据(通常是全部数据),ctrl+c。
第三步,回到Stata的data editor,ctrl+v,得到下图:
第四步,关闭Stata的data editor,完成导入数据。
导入数据后,我们会发现Stata窗口发生了三处变化。Review窗口显示了我们刚刚输入的历史命令:edit。Variables窗口显示了我们导入数据的变量名称。Results窗口显示我们导入进去了47个变量,4479个观测(4479行数据)。
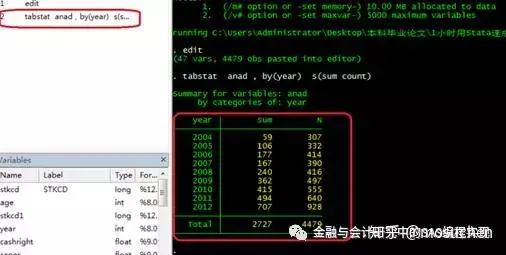
2.样本分布的表格编制
在命令窗口输入如下命令,然后回车。
tabstat anad , by(year) s(sum count)
简单解释一下:
tabstat是Stata自带的程序命令,Stata的程序格式通常都是这样安排的,第一个“单词”或“字母组合”是其自带的程序命令。
anad是标记公司有没有分析师跟踪的变量,这个变量是我一个公司一个公司标记的,有就标记为1,没有分析师跟踪就标记为0。对这个变量进行分年汇总求和就可以得到当年有分析师跟踪的样本公司总数。
by(year)是分年统计的意思。
s(sum count)意在输出变量anad的两个统计量,总和(sum),总观测数(count)。总观测数扣减总和就是没有分析师跟踪的公司数量。仔细想想为什么。
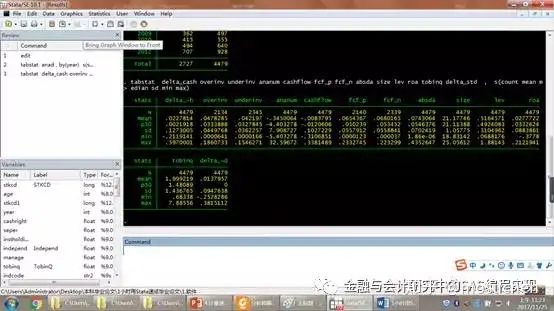
3.主要变量的描述性统计
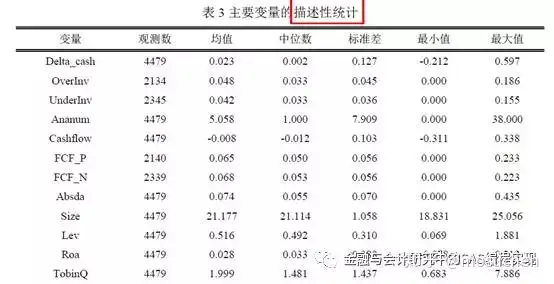
在命令窗口输入如下命令,然后回车。
tabstat delta_cash overinv underinv ananum cashflow fcf_p fcf_n absda size lev roa tobinq delta_std , s(count mean median sd min max)
简单解释一下:
tabstat是输出描述性统计非常好用的命令。
delta_cash overinv underinv ananum cashflow fcf_p fcf_n absda size lev roa tobinq delta_std是我们要进行统计的一组变量。
s(count mean median sd min max)是说我们要生成:总观测数、均值、中位数、标准差、最小值和最大值。共5项统计量。当然,如果你想生成其他统计量,可以在括号里添加,比如分位数。杨老师认为大家掌握这5项足够了。
对了,这些数据需要你手工黏贴到表格里。其实是可以自动生成表格的,不过程序更复杂一些,就不介绍了。
4.单变量之间的分组检验
有时候我们需要知道两个班级的成绩是否存在差异,从而比较班级成绩的优劣,使用简单的均值进行比较是不全面的。两个班级平均分差不多,但是一个班级高分和低分都特别多,另一个班级则比较平均。此时需要在比较时考虑数据的波动因素。这便引出了均值差异检验和中位数差异检验。你不需要知道这两种检验的区别,你只要知道,这两种检验可以告诉我们两组数据到底有没有差异就行了。
(1)参数检验:T检验(均值检验)
ttest delta_cash,by (pc)
做均值检验要一个一个变量来做。ttest 就是做均值检验的命令。
by(pc)是说根据pc(政治关联)分组,检验有政治关系的企业和没有政治关系的企业,在现金流量(delta_cash)方面,有无显著差异。
当然有差异,你看到无政治关联企业的现金流减去有政治关联企业的现金流后,得到负数。并且统计检验的P值<0.01,三颗星***显著。
注意下面这句话,你会经常碰到。
***表示检验在1%的水平上显著, **表示检验在 5%的水平上显著, *表示检验在 10%的水平上显著。
统计表格里有些差异标了*,有些没有,只有标了*才能说两组有差异,标的*越多,说明差异的可能性越大。Pr(|T| > |t|) =0.0000 ,这个数就是P值。
当P值<0.01,则表示检验在 1%的水平上显著,标记***。
当0.01<P值<0.05,则表示检验在 5%的水平上显著,标记**。
当0.05<P值<0.1,则表示检验在 10%的水平上显著,标记*。

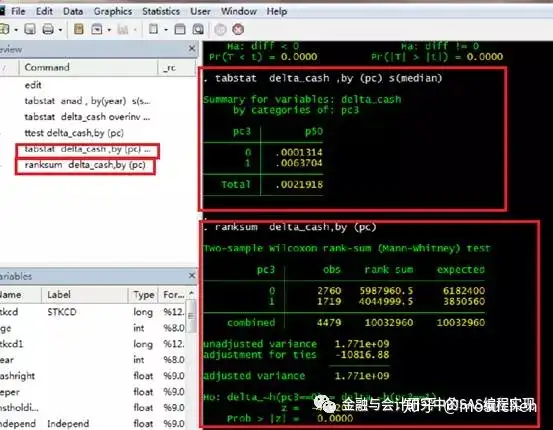
(2)非参数检验: wilcoxons 检验
tabstat delta_cash ,by (pc) s(median)
ranksum delta_cash,by (pc)
非参数检验也是要一个一个变量来检验,主要检验有政治关系的上市公司和没有政治关系的上市公司在现金流变量方面有无差异。
这个检验分两个部分。
第一部分是比较两组数据的中位数差异。
第二部分是检验这种差异是否显著。
对差异分析结果的解释与上面的解释类似。只不过P值的计算方法出现了变化。
Prob > |z|= 0.0000,这个数就是P值。
5.相关性分析
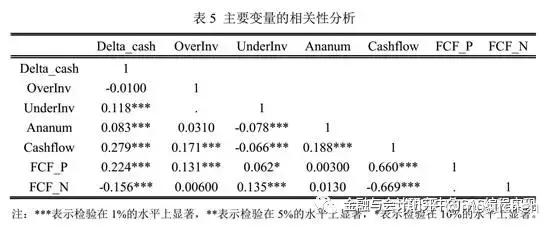
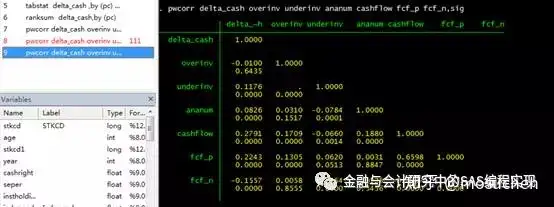
pwcorr delta_cash overinv underinv ananum cashflow fcf_p fcf_n, sig
简单解释一下,变量两两之间会有上下一对数据。比如delta_cash和overinv,对应-0.0100和0.6435上下两个数据。上面的数据是二者的相关性系数,下面的数据是对相关性进行显著性检验得到的P值。这个P值决定了二者相关性是否显著,关于P值、显著性和*数量的关系,见前文的描述。
6.回归分析
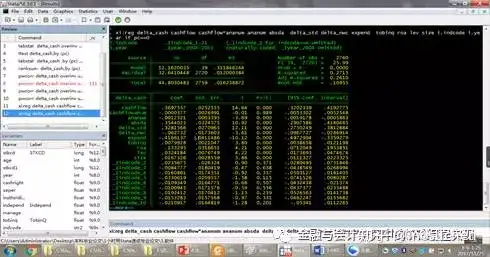
xi:reg delta_cash cashflow cashflow*ananum ananum absda delta_std delta_nwc expend tobinq roa lev size i.indcode i.year if pc==0
reg是stata的回归命令。
xi:配合后面的i.indcode和i.year,是为了控制年份和行业。
if pc==0,表示本次回归只输入没有政治关联的公司数据。
P>|t|下面的数据,就是针对每个回归系数进行检验的P值。你不需要理解P值的原理,但是你必须知道只有P值显著,我们才能说cashflow对delta_cash 有影响。不显著的话,则称未发现cashflow对delta_cash 有显著性影响。回归分析的任务就是发现哪些解释变量,对被解释变量有显著影响。因此,有没有*很重要,*越多越好。
xi:reg delta_cash cashflow cashflow*ananum ananum absda delta_std delta_nwc expend tobinq roa lev size i.indcode i.year if pc==1
if pc==0,表示本次回归只输入有政治关联的公司数据。

当然,标准的回归分析对数据诸多要求,而现实数据常常不满足回归分析的要求。此时,我们就需要识别和应对这些问题,譬如异方差、多重共线性等等。
1小时用Stata速成毕业论文-第3部分-进阶操作

上海财经大学 管理学博士
学会基本操作,足够各位同学做一篇毕业论文了,进阶操作的内容通常是为了应对答辩老师的要求。答辩老师肯定知道基本操作中的一些常见问题,他们可能需要追加一些检验。这些追加检验有很多,我挑选其中比较重要的进行简单讲解。
进阶操作包括5各部分:
1.数据的正态性检验;
2.Stata对单变量作图;
3.Stata对多变量作图;
4.异方差的调整;
5.多重共线性与方差膨胀因子。
1.数据的正态性检验
回归分析结果若要符合要求,其使用的数据应当满足正态分布。因此,有时候答辩老师会要你检验数据是否满足正态分布。
对单个变量进行正态性检验可以使用如下命令:
sktest varname
swilk varname
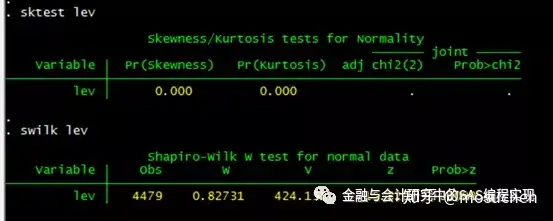
其中sktest基于变量的偏度和斜度(正态分布的偏度为0,斜度为3),swilk基于Shapiro-Wilk检验。这两个检验的零假设为变量服从正态分布。它们都给出p值,p值越小,越倾向于否定零假设,也就是变量越有可能不服从正态分布。
我们以资产负债率lev为例,对其进行正态性检验。检验的结果表明lev在样本中并不符合正态分布。虽然如此,这不是你的毕业论文,你不用在意啦。
sktest lev
swilk lev
2.Stata对单变量作图
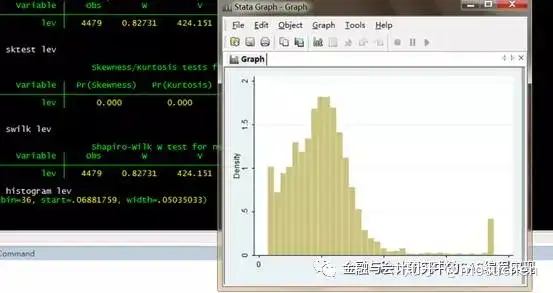
对单个变量,Stata能画如下图案:
直方图 histogram y (y是变量名,下同)
box plot graph box y
pie charts graph pie y
核估计方法得到的概率密度函数 kdensity y
QQ图 qnorm y
我们做个直方图给大家看看就好了。
命令:histogram lev
3.Stata对多变量作图
对多个变量,Stata能画如下图案:
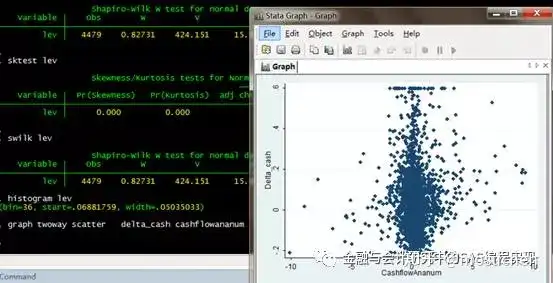
graph twoway scatter y x (y对x的散点图)
graph twoway line y x (以x为横座标,y为纵座标的点连成的折线)
graph twoway connected y x (以x为横座标,y为纵座标的点连成折线,但转角处特别标出)
graph twoway lfit y x (y对x回归的回归直线)
我们做个散点图给大家看看就好了。
命令:graph twoway scatter delta_cash cashflowananum
4.异方差的调整
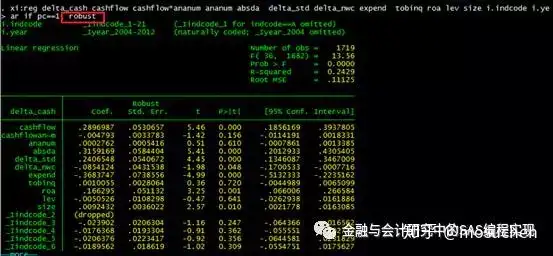
你不需要知道什么是异方差,你只要知道,如果有答辩老师问你,如果回归存在异方差怎么办,你说你进行了如下处理,在基本回归命令后加了“, robust”。这样的处理可以解决异方差问题。
xi:reg delta_cash cashflow cashflow*ananum ananum absda delta_std delta_nwc expend tobinq roa lev size i.indcode i.year if pc==0, robust

xi:reg delta_cash cashflow cashflow*ananum ananum absda delta_std delta_nwc expend tobinq roa lev size i.indcode i.year if pc==1, robust
5.多重共线性与方差膨胀因子
你不需要知道什么是多重共线性,也不需要知道什么是方差膨胀因子。你只需要知道,如果有老师问你“你的模型有没有多重共线性问题”,你就说我查看了方差膨胀因子,所有变量的方差膨胀因子都小于10,多重共线性问题不严重。
怎么查看方差膨胀因子呢。
举一个例子就可以了。
先做一个回归分析:
xi:reg delta_cash cashflow cashflow*ananum ananum absda delta_std delta_nwc expend tobinq roa lev size i.indcode i.year if pc==0, robust
然后,另起一行,跟三个字母:vif。vif就是方差膨胀因子的缩写。
注意:完整的命令是这样的。
xi:reg delta_cash cashflow cashflow*ananum ananum absda delta_std delta_nwc expend tobinq roa lev size i.indcode i.year if pc==0, robust
vif
你可以得到下图。你会发现,最大方差膨胀因子是7.89,小于10。因此,你的回归结果并没有严重的多重共线性问题。HAPPY ENDING!

